 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeE^2VTS: Energy-Efficient Video Text Spotting from Unmanned Aerial Vehicles
Jun 05, 2022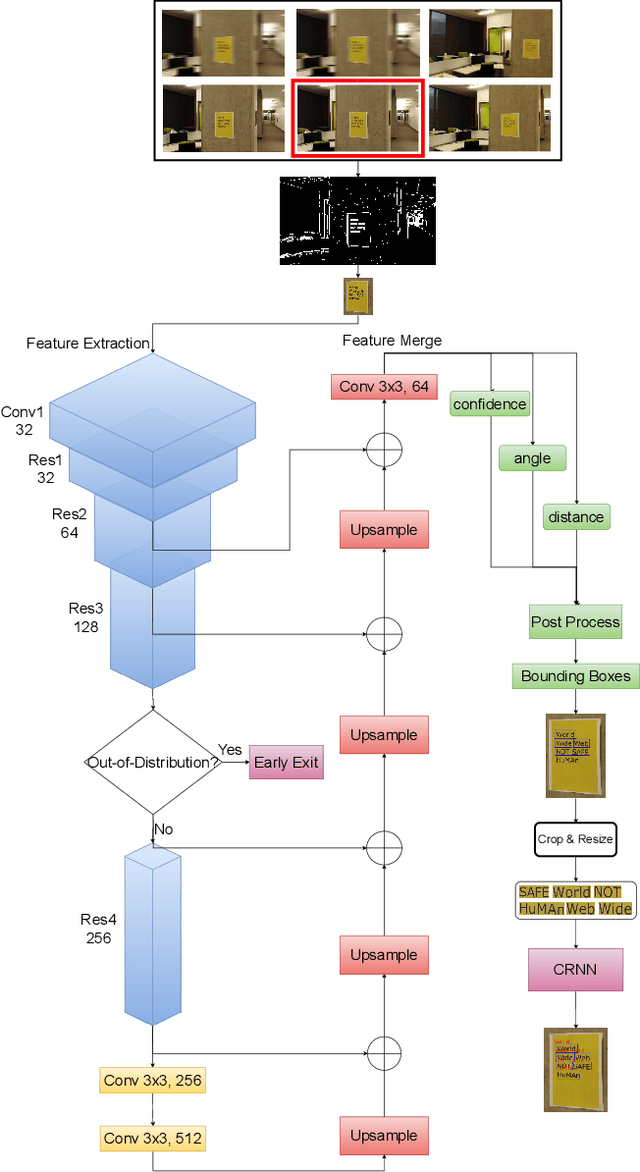
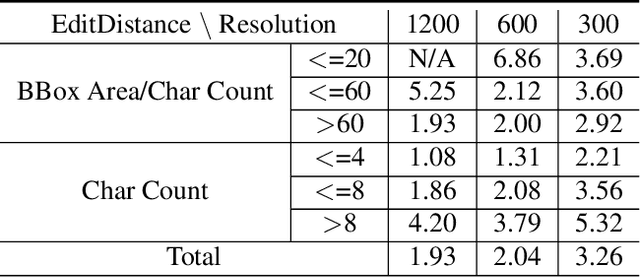

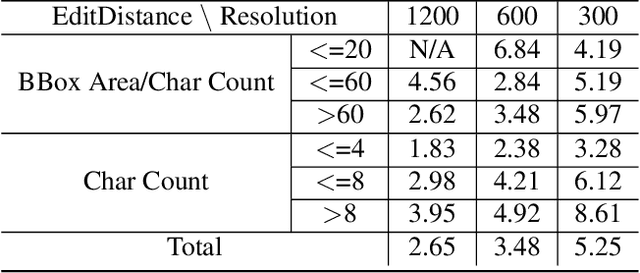
Unmanned Aerial Vehicles (UAVs) based video text spotting has been extensively used in civil and military domains. UAV's limited battery capacity motivates us to develop an energy-efficient video text spotting solution. In this paper, we first revisit RCNN's crop & resize training strategy and empirically find that it outperforms aligned RoI sampling on a real-world video text dataset captured by UAV. To reduce energy consumption, we further propose a multi-stage image processor that takes videos' redundancy, continuity, and mixed degradation into account. Lastly, the model is pruned and quantized before deployed on Raspberry Pi. Our proposed energy-efficient video text spotting solution, dubbed as E^2VTS, outperforms all previous methods by achieving a competitive tradeoff between energy efficiency and performance. All our codes and pre-trained models are available at https://github.com/wuzhenyusjtu/LPCVC20-VideoTextSpotting.
Persia: An Open, Hybrid System Scaling Deep Learning-based Recommenders up to 100 Trillion Parameters
Nov 23, 2021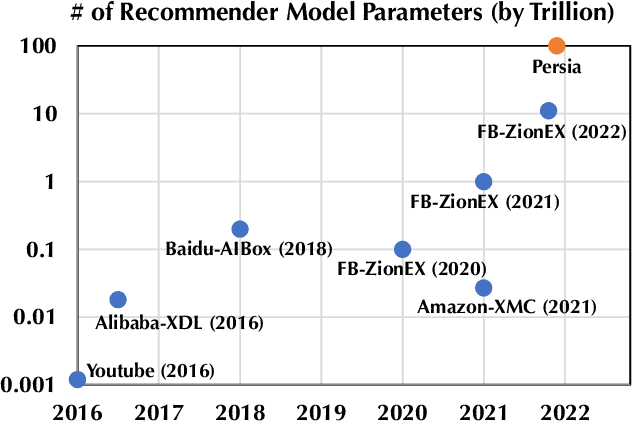
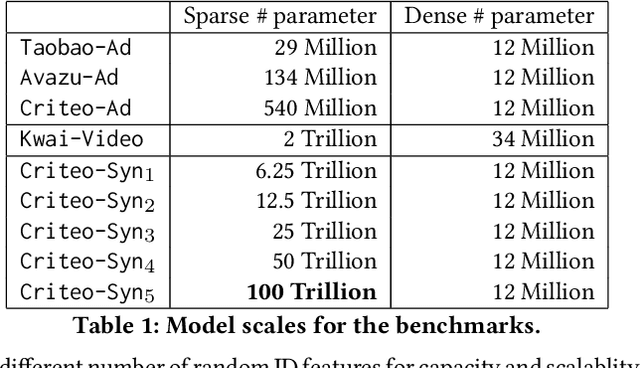
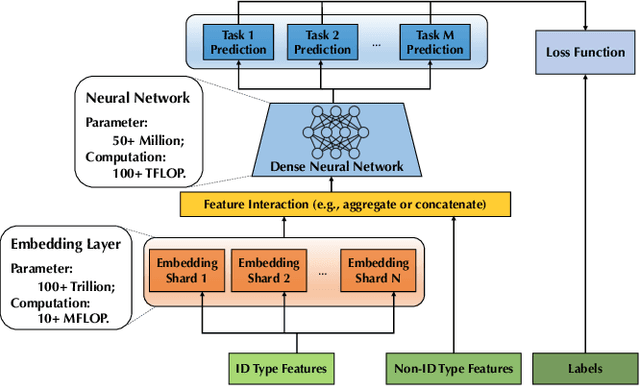
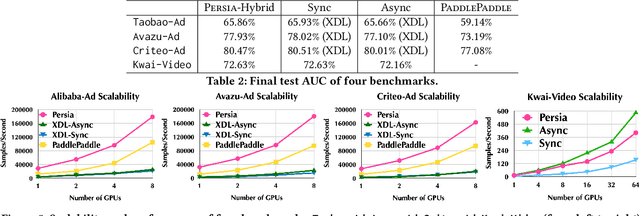
Deep learning based models have dominated the current landscape of production recommender systems. Furthermore, recent years have witnessed an exponential growth of the model scale--from Google's 2016 model with 1 billion parameters to the latest Facebook's model with 12 trillion parameters. Significant quality boost has come with each jump of the model capacity, which makes us believe the era of 100 trillion parameters is around the corner. However, the training of such models is challenging even within industrial scale data centers. This difficulty is inherited from the staggering heterogeneity of the training computation--the model's embedding layer could include more than 99.99% of the total model size, which is extremely memory-intensive; while the rest neural network is increasingly computation-intensive. To support the training of such huge models, an efficient distributed training system is in urgent need. In this paper, we resolve this challenge by careful co-design of both the optimization algorithm and the distributed system architecture. Specifically, in order to ensure both the training efficiency and the training accuracy, we design a novel hybrid training algorithm, where the embedding layer and the dense neural network are handled by different synchronization mechanisms; then we build a system called Persia (short for parallel recommendation training system with hybrid acceleration) to support this hybrid training algorithm. Both theoretical demonstration and empirical study up to 100 trillion parameters have conducted to justified the system design and implementation of Persia. We make Persia publicly available (at https://github.com/PersiaML/Persia) so that anyone would be able to easily train a recommender model at the scale of 100 trillion parameters.
BAGUA: Scaling up Distributed Learning with System Relaxations
Jul 12, 2021
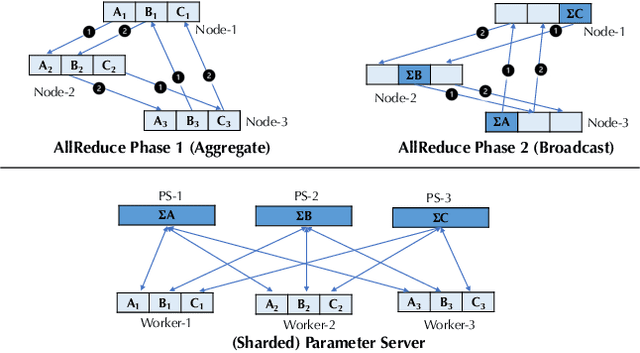
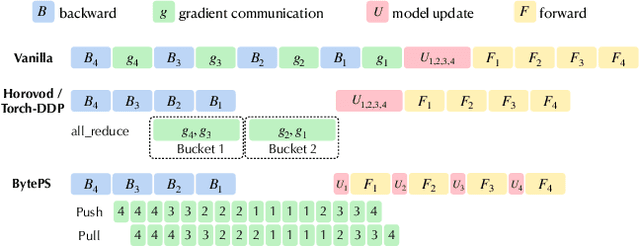

Recent years have witnessed a growing list of systems for distributed data-parallel training. Existing systems largely fit into two paradigms, i.e., parameter server and MPI-style collective operations. On the algorithmic side, researchers have proposed a wide range of techniques to lower the communication via system relaxations: quantization, decentralization, and communication delay. However, most, if not all, existing systems only rely on standard synchronous and asynchronous stochastic gradient (SG) based optimization, therefore, cannot take advantage of all possible optimizations that the machine learning community has been developing recently. Given this emerging gap between the current landscapes of systems and theory, we build BAGUA, a communication framework whose design goal is to provide a system abstraction that is both flexible and modular to support state-of-the-art system relaxation techniques of distributed training. Powered by the new system design, BAGUA has a great ability to implement and extend various state-of-the-art distributed learning algorithms. In a production cluster with up to 16 machines (128 GPUs), BAGUA can outperform PyTorch-DDP, Horovod and BytePS in the end-to-end training time by a significant margin (up to 1.95 times) across a diverse range of tasks. Moreover, we conduct a rigorous tradeoff exploration showing that different algorithms and system relaxations achieve the best performance over different network conditions.
DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning
Jun 11, 2021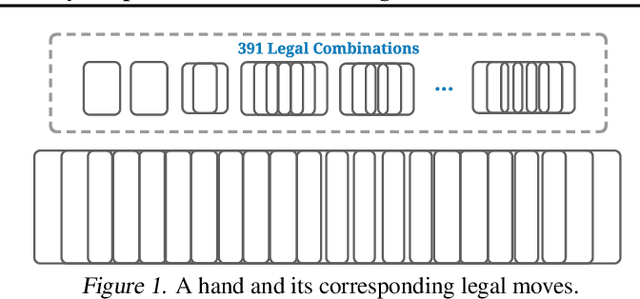
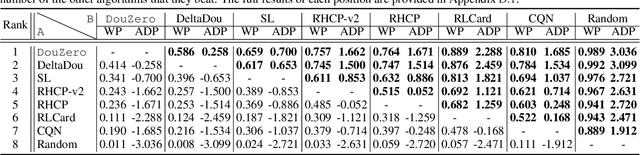
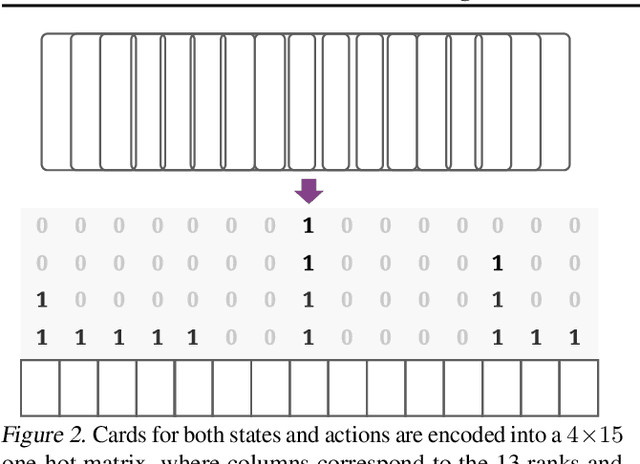

Games are abstractions of the real world, where artificial agents learn to compete and cooperate with other agents. While significant achievements have been made in various perfect- and imperfect-information games, DouDizhu (a.k.a. Fighting the Landlord), a three-player card game, is still unsolved. DouDizhu is a very challenging domain with competition, collaboration, imperfect information, large state space, and particularly a massive set of possible actions where the legal actions vary significantly from turn to turn. Unfortunately, modern reinforcement learning algorithms mainly focus on simple and small action spaces, and not surprisingly, are shown not to make satisfactory progress in DouDizhu. In this work, we propose a conceptually simple yet effective DouDizhu AI system, namely DouZero, which enhances traditional Monte-Carlo methods with deep neural networks, action encoding, and parallel actors. Starting from scratch in a single server with four GPUs, DouZero outperformed all the existing DouDizhu AI programs in days of training and was ranked the first in the Botzone leaderboard among 344 AI agents. Through building DouZero, we show that classic Monte-Carlo methods can be made to deliver strong results in a hard domain with a complex action space. The code and an online demo are released at https://github.com/kwai/DouZero with the hope that this insight could motivate future work.
1-bit Adam: Communication Efficient Large-Scale Training with Adam's Convergence Speed
Feb 04, 2021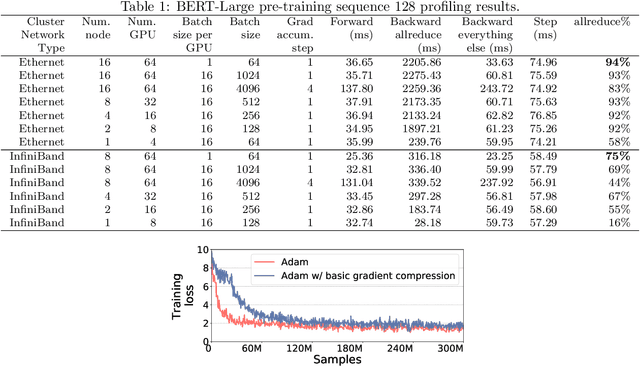
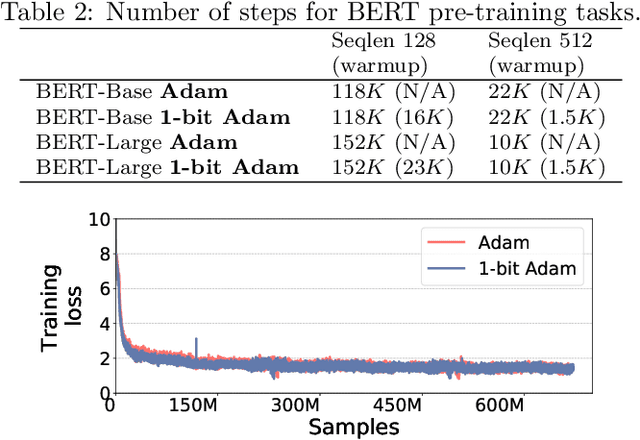

Scalable training of large models (like BERT and GPT-3) requires careful optimization rooted in model design, architecture, and system capabilities. From a system standpoint, communication has become a major bottleneck, especially on commodity systems with standard TCP interconnects that offer limited network bandwidth. Communication compression is an important technique to reduce training time on such systems. One of the most effective methods is error-compensated compression, which offers robust convergence speed even under 1-bit compression. However, state-of-the-art error compensation techniques only work with basic optimizers like SGD and momentum SGD, which are linearly dependent on the gradients. They do not work with non-linear gradient-based optimizers like Adam, which offer state-of-the-art convergence efficiency and accuracy for models like BERT. In this paper, we propose 1-bit Adam that reduces the communication volume by up to $5\times$, offers much better scalability, and provides the same convergence speed as uncompressed Adam. Our key finding is that Adam's variance (non-linear term) becomes stable (after a warmup phase) and can be used as a fixed precondition for the rest of the training (compression phase). Experiments on up to 256 GPUs show that 1-bit Adam enables up to $3.3\times$ higher throughput for BERT-Large pre-training and up to $2.9\times$ higher throughput for SQuAD fine-tuning. In addition, we provide theoretical analysis for our proposed work.
APMSqueeze: A Communication Efficient Adam-Preconditioned Momentum SGD Algorithm
Aug 28, 2020
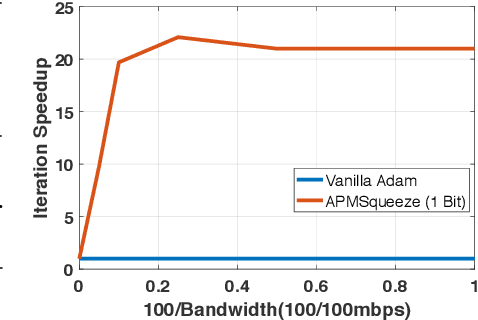
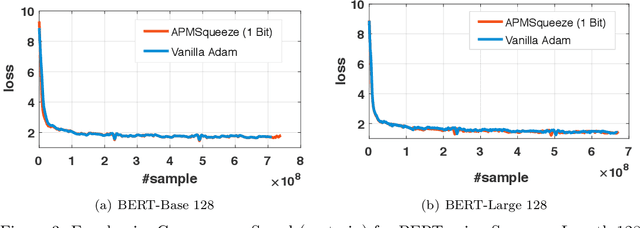
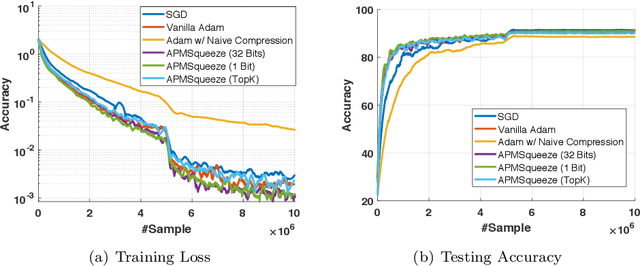
Adam is the important optimization algorithm to guarantee efficiency and accuracy for training many important tasks such as BERT and ImageNet. However, Adam is generally not compatible with information (gradient) compression technology. Therefore, the communication usually becomes the bottleneck for parallelizing Adam. In this paper, we propose a communication efficient {\bf A}DAM {\bf p}reconditioned {\bf M}omentum SGD algorithm-- named APMSqueeze-- through an error compensated method compressing gradients. The proposed algorithm achieves a similar convergence efficiency to Adam in term of epochs, but significantly reduces the running time per epoch. In terms of end-to-end performance (including the full-precision pre-condition step), APMSqueeze is able to provide {sometimes by up to $2-10\times$ speed-up depending on network bandwidth.} We also conduct theoretical analysis on the convergence and efficiency.
Stochastic Recursive Momentum for Policy Gradient Methods
Mar 09, 2020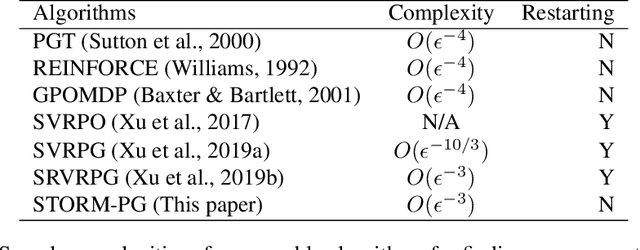
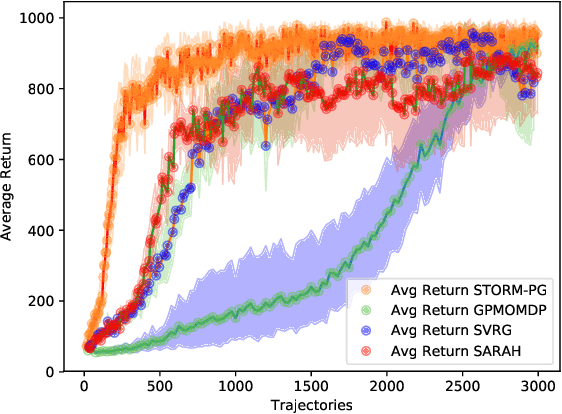
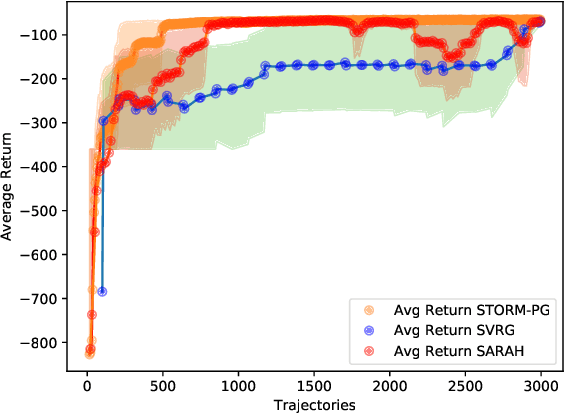
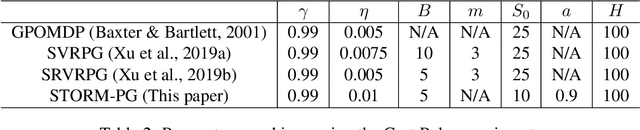
In this paper, we propose a novel algorithm named STOchastic Recursive Momentum for Policy Gradient (STORM-PG), which operates a SARAH-type stochastic recursive variance-reduced policy gradient in an exponential moving average fashion. STORM-PG enjoys a provably sharp $O(1/\epsilon^3)$ sample complexity bound for STORM-PG, matching the best-known convergence rate for policy gradient algorithm. In the mean time, STORM-PG avoids the alternations between large batches and small batches which persists in comparable variance-reduced policy gradient methods, allowing considerably simpler parameter tuning. Numerical experiments depicts the superiority of our algorithm over comparative policy gradient algorithms.
Stochastic Recursive Variance Reduction for Efficient Smooth Non-Convex Compositional Optimization
Jan 25, 2020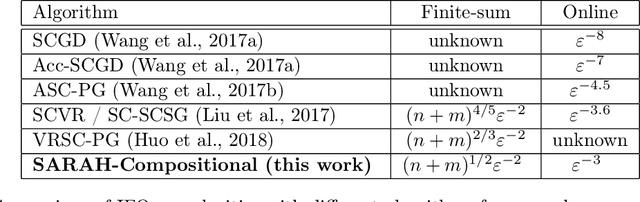
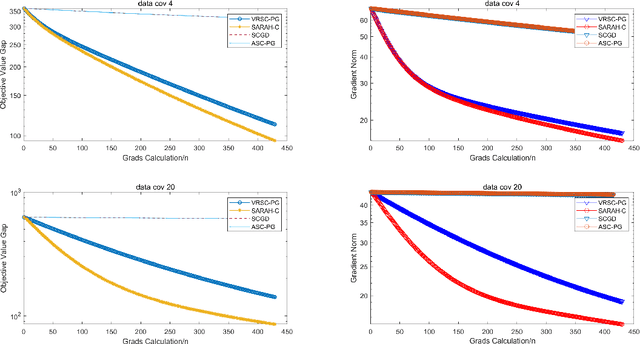

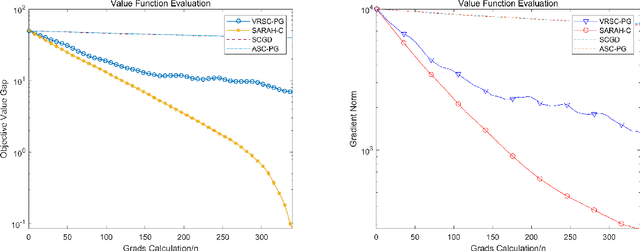
Stochastic compositional optimization arises in many important machine learning tasks such as value function evaluation in reinforcement learning and portfolio management. The objective function is the composition of two expectations of stochastic functions, and is more challenging to optimize than vanilla stochastic optimization problems. In this paper, we investigate the stochastic compositional optimization in the general smooth non-convex setting. We employ a recently developed idea of \textit{Stochastic Recursive Gradient Descent} to design a novel algorithm named SARAH-Compositional, and prove a sharp Incremental First-order Oracle (IFO) complexity upper bound for stochastic compositional optimization: $\mathcal{O}((n+m)^{1/2} \varepsilon^{-2})$ in the finite-sum case and $\mathcal{O}(\varepsilon^{-3})$ in the online case. Such a complexity is known to be the best one among IFO complexity results for non-convex stochastic compositional optimization, and is believed to be optimal. Our experiments validate the theoretical performance of our algorithm.
$\texttt{DeepSqueeze}$: Decentralization Meets Error-Compensated Compression
Aug 03, 2019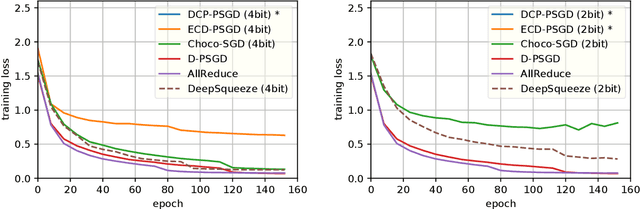
Communication is a key bottleneck in distributed training. Recently, an \emph{error-compensated} compression technology was particularly designed for the \emph{centralized} learning and receives huge successes, by showing significant advantages over state-of-the-art compression based methods in saving the communication cost. Since the \emph{decentralized} training has been witnessed to be superior to the traditional \emph{centralized} training in the communication restricted scenario, therefore a natural question to ask is "how to apply the error-compensated technology to the decentralized learning to further reduce the communication cost." However, a trivial extension of compression based centralized training algorithms does not exist for the decentralized scenario. key difference between centralized and decentralized training makes this extension extremely non-trivial. In this paper, we propose an elegant algorithmic design to employ error-compensated stochastic gradient descent for the decentralized scenario, named $\texttt{DeepSqueeze}$. Both the theoretical analysis and the empirical study are provided to show the proposed $\texttt{DeepSqueeze}$ algorithm outperforms the existing compression based decentralized learning algorithms. To the best of our knowledge, this is the first time to apply the error-compensated compression to the decentralized learning.
DoubleSqueeze: Parallel Stochastic Gradient Descent with Double-Pass Error-Compensated Compression
May 15, 2019

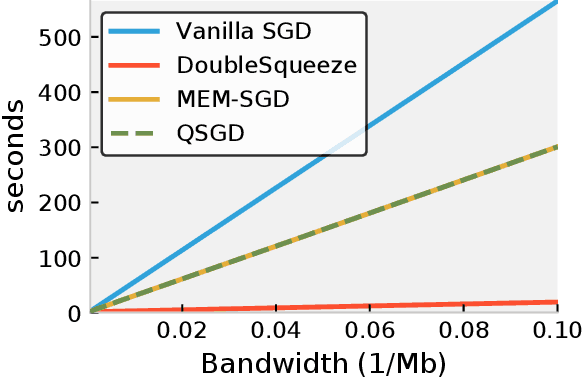

A standard approach in large scale machine learning is distributed stochastic gradient training, which requires the computation of aggregated stochastic gradients over multiple nodes on a network. Communication is a major bottleneck in such applications, and in recent years, compressed stochastic gradient methods such as QSGD (quantized SGD) and sparse SGD have been proposed to reduce communication. It was also shown that error compensation can be combined with compression to achieve better convergence in a scheme that each node compresses its local stochastic gradient and broadcast the result to all other nodes over the network in a single pass. However, such a single pass broadcast approach is not realistic in many practical implementations. For example, under the popular parameter server model for distributed learning, the worker nodes need to send the compressed local gradients to the parameter server, which performs the aggregation. The parameter server has to compress the aggregated stochastic gradient again before sending it back to the worker nodes. In this work, we provide a detailed analysis on this two-pass communication model and its asynchronous parallel variant, with error-compensated compression both on the worker nodes and on the parameter server. We show that the error-compensated stochastic gradient algorithm admits three very nice properties: 1) it is compatible with an \emph{arbitrary} compression technique; 2) it admits an improved convergence rate than the non error-compensated stochastic gradient methods such as QSGD and sparse SGD; 3) it admits linear speedup with respect to the number of workers. The empirical study is also conducted to validate our theoretical results.