 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpidR-Adapt: A Universal Speech Representation Model for Few-Shot Adaptation
Dec 24, 2025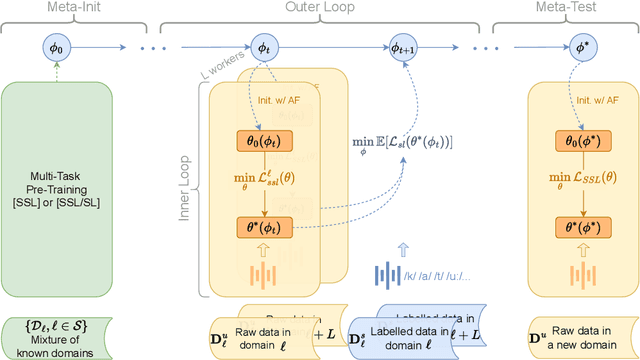

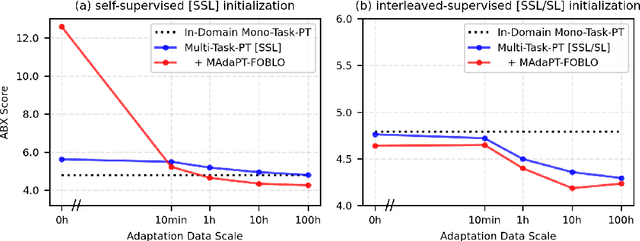
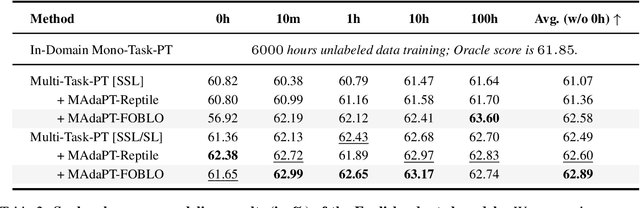
Human infants, with only a few hundred hours of speech exposure, acquire basic units of new languages, highlighting a striking efficiency gap compared to the data-hungry self-supervised speech models. To address this gap, this paper introduces SpidR-Adapt for rapid adaptation to new languages using minimal unlabeled data. We cast such low-resource speech representation learning as a meta-learning problem and construct a multi-task adaptive pre-training (MAdaPT) protocol which formulates the adaptation process as a bi-level optimization framework. To enable scalable meta-training under this framework, we propose a novel heuristic solution, first-order bi-level optimization (FOBLO), avoiding heavy computation costs. Finally, we stabilize meta-training by using a robust initialization through interleaved supervision which alternates self-supervised and supervised objectives. Empirically, SpidR-Adapt achieves rapid gains in phonemic discriminability (ABX) and spoken language modeling (sWUGGY, sBLIMP, tSC), improving over in-domain language models after training on less than 1h of target-language audio, over $100\times$ more data-efficient than standard training. These findings highlight a practical, architecture-agnostic path toward biologically inspired, data-efficient representations. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr-adapt.
SpidR: Learning Fast and Stable Linguistic Units for Spoken Language Models Without Supervision
Dec 23, 2025The parallel advances in language modeling and speech representation learning have raised the prospect of learning language directly from speech without textual intermediates. This requires extracting semantic representations directly from speech. Our contributions are threefold. First, we introduce SpidR, a self-supervised speech representation model that efficiently learns representations with highly accessible phonetic information, which makes it particularly suited for textless spoken language modeling. It is trained on raw waveforms using a masked prediction objective combined with self-distillation and online clustering. The intermediate layers of the student model learn to predict assignments derived from the teacher's intermediate layers. This learning objective stabilizes the online clustering procedure compared to previous approaches, resulting in higher quality codebooks. SpidR outperforms wav2vec 2.0, HuBERT, WavLM, and DinoSR on downstream language modeling benchmarks (sWUGGY, sBLIMP, tSC). Second, we systematically evaluate across models and layers the correlation between speech unit quality (ABX, PNMI) and language modeling performance, validating these metrics as reliable proxies. Finally, SpidR significantly reduces pretraining time compared to HuBERT, requiring only one day of pretraining on 16 GPUs, instead of a week. This speedup is enabled by the pretraining method and an efficient codebase, which allows faster iteration and easier experimentation. We open-source the training code and model checkpoints at https://github.com/facebookresearch/spidr.
LongTail-Swap: benchmarking language models' abilities on rare words
Oct 05, 2025Children learn to speak with a low amount of data and can be taught new words on a few-shot basis, making them particularly data-efficient learners. The BabyLM challenge aims at exploring language model (LM) training in the low-data regime but uses metrics that concentrate on the head of the word distribution. Here, we introduce LongTail-Swap (LT-Swap), a benchmark that focuses on the tail of the distribution, i.e., measures the ability of LMs to learn new words with very little exposure, like infants do. LT-Swap is a pretraining corpus-specific test set of acceptable versus unacceptable sentence pairs that isolate semantic and syntactic usage of rare words. Models are evaluated in a zero-shot fashion by computing the average log probabilities over the two members of each pair. We built two such test sets associated with the 10M words and 100M words BabyLM training sets, respectively, and evaluated 16 models from the BabyLM leaderboard. Our results not only highlight the poor performance of language models on rare words but also reveal that performance differences across LM architectures are much more pronounced in the long tail than in the head. This offers new insights into which architectures are better at handling rare word generalization. We've also made the code publicly avail
Probabilistic Interactive 3D Segmentation with Hierarchical Neural Processes
May 03, 2025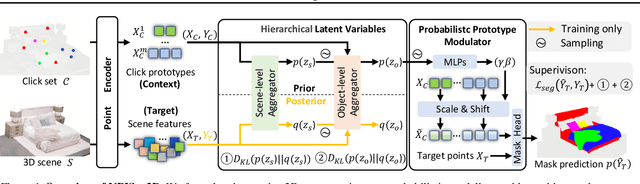
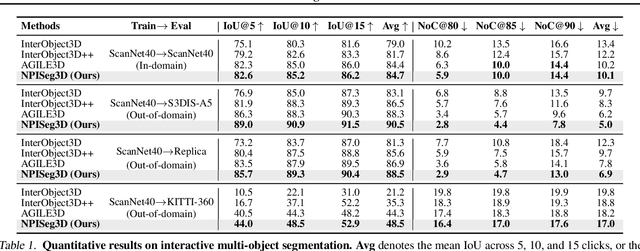
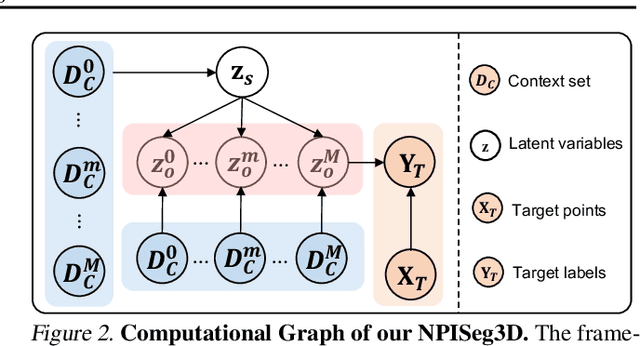
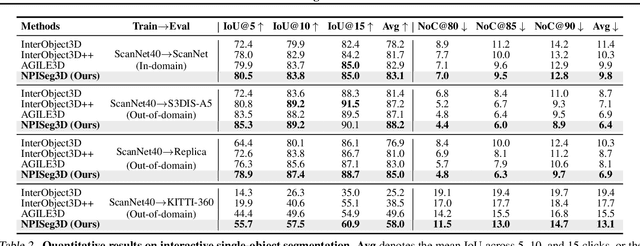
Interactive 3D segmentation has emerged as a promising solution for generating accurate object masks in complex 3D scenes by incorporating user-provided clicks. However, two critical challenges remain underexplored: (1) effectively generalizing from sparse user clicks to produce accurate segmentation, and (2) quantifying predictive uncertainty to help users identify unreliable regions. In this work, we propose NPISeg3D, a novel probabilistic framework that builds upon Neural Processes (NPs) to address these challenges. Specifically, NPISeg3D introduces a hierarchical latent variable structure with scene-specific and object-specific latent variables to enhance few-shot generalization by capturing both global context and object-specific characteristics. Additionally, we design a probabilistic prototype modulator that adaptively modulates click prototypes with object-specific latent variables, improving the model's ability to capture object-aware context and quantify predictive uncertainty. Experiments on four 3D point cloud datasets demonstrate that NPISeg3D achieves superior segmentation performance with fewer clicks while providing reliable uncertainty estimations.
Art3D: Training-Free 3D Generation from Flat-Colored Illustration
Apr 14, 2025Large-scale pre-trained image-to-3D generative models have exhibited remarkable capabilities in diverse shape generations. However, most of them struggle to synthesize plausible 3D assets when the reference image is flat-colored like hand drawings due to the lack of 3D illusion, which are often the most user-friendly input modalities in art content creation. To this end, we propose Art3D, a training-free method that can lift flat-colored 2D designs into 3D. By leveraging structural and semantic features with pre- trained 2D image generation models and a VLM-based realism evaluation, Art3D successfully enhances the three-dimensional illusion in reference images, thus simplifying the process of generating 3D from 2D, and proves adaptable to a wide range of painting styles. To benchmark the generalization performance of existing image-to-3D models on flat-colored images without 3D feeling, we collect a new dataset, Flat-2D, with over 100 samples. Experimental results demonstrate the performance and robustness of Art3D, exhibiting superior generalizable capacity and promising practical applicability. Our source code and dataset will be publicly available on our project page: https://joy-jy11.github.io/ .
Distributional Vision-Language Alignment by Cauchy-Schwarz Divergence
Feb 24, 2025Multimodal alignment is crucial for various downstream tasks such as cross-modal generation and retrieval. Previous multimodal approaches like CLIP maximize the mutual information mainly by aligning pairwise samples across modalities while overlooking the distributional differences, leading to suboptimal alignment with modality gaps. In this paper, to overcome the limitation, we propose CS-Aligner, a novel and straightforward framework that performs distributional vision-language alignment by integrating Cauchy-Schwarz (CS) divergence with mutual information. In the proposed framework, we find that the CS divergence and mutual information serve complementary roles in multimodal alignment, capturing both the global distribution information of each modality and the pairwise semantic relationships, yielding tighter and more precise alignment. Moreover, CS-Aligher enables incorporating additional information from unpaired data and token-level representations, enhancing flexible and fine-grained alignment in practice. Experiments on text-to-image generation and cross-modality retrieval tasks demonstrate the effectiveness of our method on vision-language alignment.
Geometric Neural Process Fields
Feb 04, 2025This paper addresses the challenge of Neural Field (NeF) generalization, where models must efficiently adapt to new signals given only a few observations. To tackle this, we propose Geometric Neural Process Fields (G-NPF), a probabilistic framework for neural radiance fields that explicitly captures uncertainty. We formulate NeF generalization as a probabilistic problem, enabling direct inference of NeF function distributions from limited context observations. To incorporate structural inductive biases, we introduce a set of geometric bases that encode spatial structure and facilitate the inference of NeF function distributions. Building on these bases, we design a hierarchical latent variable model, allowing G-NPF to integrate structural information across multiple spatial levels and effectively parameterize INR functions. This hierarchical approach improves generalization to novel scenes and unseen signals. Experiments on novel-view synthesis for 3D scenes, as well as 2D image and 1D signal regression, demonstrate the effectiveness of our method in capturing uncertainty and leveraging structural information for improved generalization.
Beyond Any-Shot Adaptation: Predicting Optimization Outcome for Robustness Gains without Extra Pay
Jan 19, 2025



The foundation model enables fast problem-solving without learning from scratch, and such a desirable adaptation property benefits from its adopted cross-task generalization paradigms, e.g., pretraining, meta-training, or finetuning. Recent trends have focused on the curation of task datasets during optimization, which includes task selection as an indispensable consideration for either adaptation robustness or sampling efficiency purposes. Despite some progress, selecting crucial task batches to optimize over iteration mostly exhausts massive task queries and requires intensive evaluation and computations to secure robust adaptation. This work underscores the criticality of both robustness and learning efficiency, especially in scenarios where tasks are risky to collect or costly to evaluate. To this end, we present Model Predictive Task Sampling (MPTS), a novel active task sampling framework to establish connections between the task space and adaptation risk landscape achieve robust adaptation. Technically, MPTS characterizes the task episodic information with a generative model and predicts optimization outcome after adaptation from posterior inference, i.e., forecasting task-specific adaptation risk values. The resulting risk learner amortizes expensive annotation, evaluation, or computation operations in task robust adaptation learning paradigms. Extensive experimental results show that MPTS can be seamlessly integrated into zero-shot, few-shot, and many-shot learning paradigms, increases adaptation robustness, and retains learning efficiency without affording extra cost. The code will be available at the project site https://github.com/thu-rllab/MPTS.
Visual Large Language Models for Generalized and Specialized Applications
Jan 06, 2025



Visual-language models (VLM) have emerged as a powerful tool for learning a unified embedding space for vision and language. Inspired by large language models, which have demonstrated strong reasoning and multi-task capabilities, visual large language models (VLLMs) are gaining increasing attention for building general-purpose VLMs. Despite the significant progress made in VLLMs, the related literature remains limited, particularly from a comprehensive application perspective, encompassing generalized and specialized applications across vision (image, video, depth), action, and language modalities. In this survey, we focus on the diverse applications of VLLMs, examining their using scenarios, identifying ethics consideration and challenges, and discussing future directions for their development. By synthesizing these contents, we aim to provide a comprehensive guide that will pave the way for future innovations and broader applications of VLLMs. The paper list repository is available: https://github.com/JackYFL/awesome-VLLMs.
Proactive Gradient Conflict Mitigation in Multi-Task Learning: A Sparse Training Perspective
Nov 27, 2024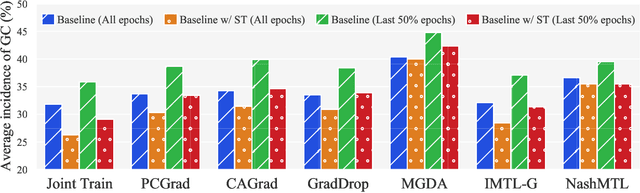
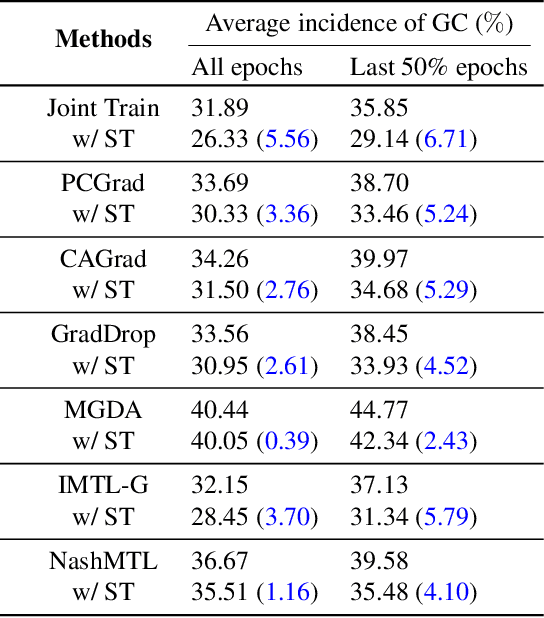
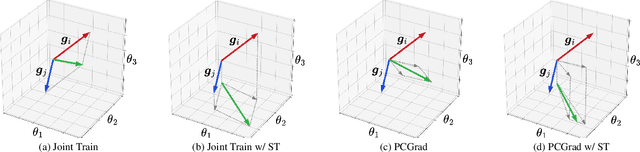
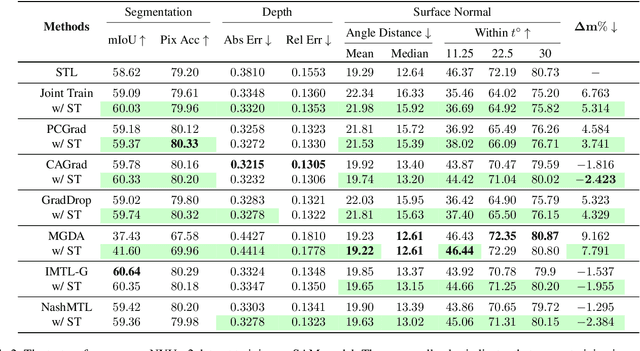
Advancing towards generalist agents necessitates the concurrent processing of multiple tasks using a unified model, thereby underscoring the growing significance of simultaneous model training on multiple downstream tasks. A common issue in multi-task learning is the occurrence of gradient conflict, which leads to potential competition among different tasks during joint training. This competition often results in improvements in one task at the expense of deterioration in another. Although several optimization methods have been developed to address this issue by manipulating task gradients for better task balancing, they cannot decrease the incidence of gradient conflict. In this paper, we systematically investigate the occurrence of gradient conflict across different methods and propose a strategy to reduce such conflicts through sparse training (ST), wherein only a portion of the model's parameters are updated during training while keeping the rest unchanged. Our extensive experiments demonstrate that ST effectively mitigates conflicting gradients and leads to superior performance. Furthermore, ST can be easily integrated with gradient manipulation techniques, thus enhancing their effectiveness.