 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroAda: Activating Each Neuron's Potential for Parameter-Efficient Fine-Tuning
Oct 21, 2025



Existing parameter-efficient fine-tuning (PEFT) methods primarily fall into two categories: addition-based and selective in-situ adaptation. The former, such as LoRA, introduce additional modules to adapt the model to downstream tasks, offering strong memory efficiency. However, their representational capacity is often limited, making them less suitable for fine-grained adaptation. In contrast, the latter directly fine-tunes a carefully chosen subset of the original model parameters, allowing for more precise and effective adaptation, but at the cost of significantly increased memory consumption. To reconcile this trade-off, we propose NeuroAda, a novel PEFT method that enables fine-grained model finetuning while maintaining high memory efficiency. Our approach first identifies important parameters (i.e., connections within the network) as in selective adaptation, and then introduces bypass connections for these selected parameters. During finetuning, only the bypass connections are updated, leaving the original model parameters frozen. Empirical results on 23+ tasks spanning both natural language generation and understanding demonstrate that NeuroAda achieves state-of-the-art performance with as little as $\leq \textbf{0.02}\%$ trainable parameters, while reducing CUDA memory usage by up to 60%. We release our code here: https://github.com/FightingFighting/NeuroAda.git.
Proactive Gradient Conflict Mitigation in Multi-Task Learning: A Sparse Training Perspective
Nov 27, 2024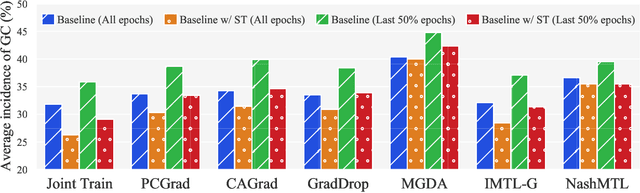
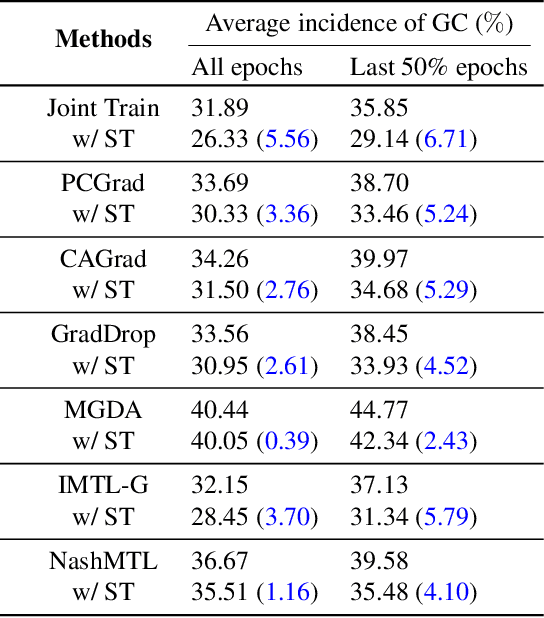
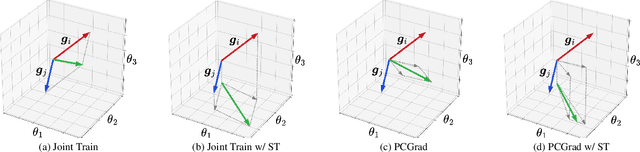
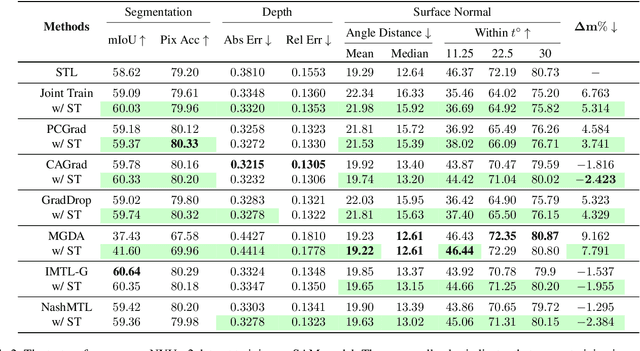
Advancing towards generalist agents necessitates the concurrent processing of multiple tasks using a unified model, thereby underscoring the growing significance of simultaneous model training on multiple downstream tasks. A common issue in multi-task learning is the occurrence of gradient conflict, which leads to potential competition among different tasks during joint training. This competition often results in improvements in one task at the expense of deterioration in another. Although several optimization methods have been developed to address this issue by manipulating task gradients for better task balancing, they cannot decrease the incidence of gradient conflict. In this paper, we systematically investigate the occurrence of gradient conflict across different methods and propose a strategy to reduce such conflicts through sparse training (ST), wherein only a portion of the model's parameters are updated during training while keeping the rest unchanged. Our extensive experiments demonstrate that ST effectively mitigates conflicting gradients and leads to superior performance. Furthermore, ST can be easily integrated with gradient manipulation techniques, thus enhancing their effectiveness.
CYCLE: Cross-Year Contrastive Learning in Entity-Linking
Oct 11, 2024



Knowledge graphs constantly evolve with new entities emerging, existing definitions being revised, and entity relationships changing. These changes lead to temporal degradation in entity linking models, characterized as a decline in model performance over time. To address this issue, we propose leveraging graph relationships to aggregate information from neighboring entities across different time periods. This approach enhances the ability to distinguish similar entities over time, thereby minimizing the impact of temporal degradation. We introduce \textbf{CYCLE}: \textbf{C}ross-\textbf{Y}ear \textbf{C}ontrastive \textbf{L}earning for \textbf{E}ntity-Linking. This model employs a novel graph contrastive learning method to tackle temporal performance degradation in entity linking tasks. Our contrastive learning method treats newly added graph relationships as \textit{positive} samples and newly removed ones as \textit{negative} samples. This approach helps our model effectively prevent temporal degradation, achieving a 13.90\% performance improvement over the state-of-the-art from 2023 when the time gap is one year, and a 17.79\% improvement as the gap expands to three years. Further analysis shows that CYCLE is particularly robust for low-degree entities, which are less resistant to temporal degradation due to their sparse connectivity, making them particularly suitable for our method. The code and data are made available at \url{https://github.com/pengyu-zhang/CYCLE-Cross-Year-Contrastive-Learning-in-Entity-Linking}.
TIGER: Temporally Improved Graph Entity Linker
Oct 11, 2024



Knowledge graphs change over time, for example, when new entities are introduced or entity descriptions change. This impacts the performance of entity linking, a key task in many uses of knowledge graphs such as web search and recommendation. Specifically, entity linking models exhibit temporal degradation - their performance decreases the further a knowledge graph moves from its original state on which an entity linking model was trained. To tackle this challenge, we introduce \textbf{TIGER}: a \textbf{T}emporally \textbf{I}mproved \textbf{G}raph \textbf{E}ntity Linke\textbf{r}. By incorporating structural information between entities into the model, we enhance the learned representation, making entities more distinguishable over time. The core idea is to integrate graph-based information into text-based information, from which both distinct and shared embeddings are based on an entity's feature and structural relationships and their interaction. Experiments on three datasets show that our model can effectively prevent temporal degradation, demonstrating a 16.24\% performance boost over the state-of-the-art in a temporal setting when the time gap is one year and an improvement to 20.93\% as the gap expands to three years. The code and data are made available at \url{https://github.com/pengyu-zhang/TIGER-Temporally-Improved-Graph-Entity-Linker}.
UFLUX v2.0: A Process-Informed Machine Learning Framework for Efficient and Explainable Modelling of Terrestrial Carbon Uptake
Oct 04, 2024



Gross Primary Productivity (GPP), the amount of carbon plants fixed by photosynthesis, is pivotal for understanding the global carbon cycle and ecosystem functioning. Process-based models built on the knowledge of ecological processes are susceptible to biases stemming from their assumptions and approximations. These limitations potentially result in considerable uncertainties in global GPP estimation, which may pose significant challenges to our Net Zero goals. This study presents UFLUX v2.0, a process-informed model that integrates state-of-art ecological knowledge and advanced machine learning techniques to reduce uncertainties in GPP estimation by learning the biases between process-based models and eddy covariance (EC) measurements. In our findings, UFLUX v2.0 demonstrated a substantial improvement in model accuracy, achieving an R^2 of 0.79 with a reduced RMSE of 1.60 g C m^-2 d^-1, compared to the process-based model's R^2 of 0.51 and RMSE of 3.09 g C m^-2 d^-1. Our global GPP distribution analysis indicates that while UFLUX v2.0 and the process-based model achieved similar global total GPP (137.47 Pg C and 132.23 Pg C, respectively), they exhibited large differences in spatial distribution, particularly in latitudinal gradients. These differences are very likely due to systematic biases in the process-based model and differing sensitivities to climate and environmental conditions. This study offers improved adaptability for GPP modelling across diverse ecosystems, and further enhances our understanding of global carbon cycles and its responses to environmental changes.
Comparing remote sensing-based forest biomass mapping approaches using new forest inventory plots in contrasting forests in northeastern and southwestern China
May 24, 2024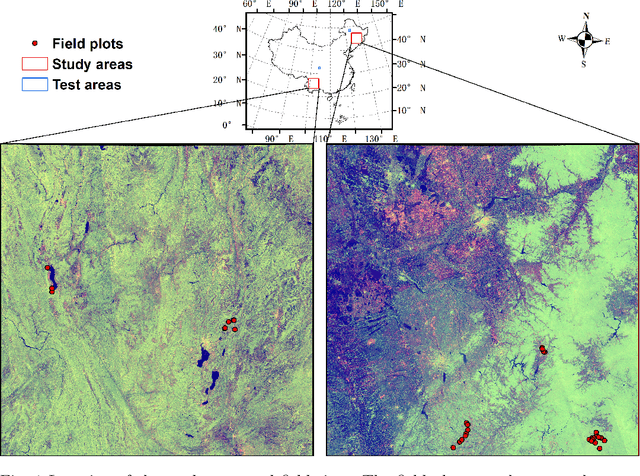
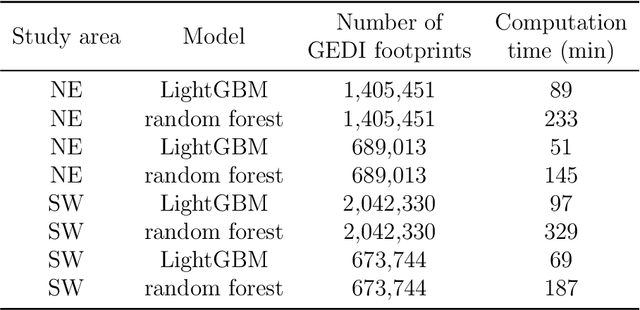

Large-scale high spatial resolution aboveground biomass (AGB) maps play a crucial role in determining forest carbon stocks and how they are changing, which is instrumental in understanding the global carbon cycle, and implementing policy to mitigate climate change. The advent of the new space-borne LiDAR sensor, NASA's GEDI instrument, provides unparalleled possibilities for the accurate and unbiased estimation of forest AGB at high resolution, particularly in dense and tall forests, where Synthetic Aperture Radar (SAR) and passive optical data exhibit saturation. However, GEDI is a sampling instrument, collecting dispersed footprints, and its data must be combined with that from other continuous cover satellites to create high-resolution maps, using local machine learning methods. In this study, we developed local models to estimate forest AGB from GEDI L2A data, as the models used to create GEDI L4 AGB data incorporated minimal field data from China. We then applied LightGBM and random forest regression to generate wall-to-wall AGB maps at 25 m resolution, using extensive GEDI footprints as well as Sentinel-1 data, ALOS-2 PALSAR-2 and Sentinel-2 optical data. Through a 5-fold cross-validation, LightGBM demonstrated a slightly better performance than Random Forest across two contrasting regions. However, in both regions, the computation speed of LightGBM is substantially faster than that of the random forest model, requiring roughly one-third of the time to compute on the same hardware. Through the validation against field data, the 25 m resolution AGB maps generated using the local models developed in this study exhibited higher accuracy compared to the GEDI L4B AGB data. We found in both regions an increase in error as slope increased. The trained models were tested on nearby but different regions and exhibited good performance.