 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboMIND 2.0: A Multimodal, Bimanual Mobile Manipulation Dataset for Generalizable Embodied Intelligence
Dec 31, 2025While data-driven imitation learning has revolutionized robotic manipulation, current approaches remain constrained by the scarcity of large-scale, diverse real-world demonstrations. Consequently, the ability of existing models to generalize across long-horizon bimanual tasks and mobile manipulation in unstructured environments remains limited. To bridge this gap, we present RoboMIND 2.0, a comprehensive real-world dataset comprising over 310K dual-arm manipulation trajectories collected across six distinct robot embodiments and 739 complex tasks. Crucially, to support research in contact-rich and spatially extended tasks, the dataset incorporates 12K tactile-enhanced episodes and 20K mobile manipulation trajectories. Complementing this physical data, we construct high-fidelity digital twins of our real-world environments, releasing an additional 20K-trajectory simulated dataset to facilitate robust sim-to-real transfer. To fully exploit the potential of RoboMIND 2.0, we propose MIND-2 system, a hierarchical dual-system frame-work optimized via offline reinforcement learning. MIND-2 integrates a high-level semantic planner (MIND-2-VLM) to decompose abstract natural language instructions into grounded subgoals, coupled with a low-level Vision-Language-Action executor (MIND-2-VLA), which generates precise, proprioception-aware motor actions.
SpikePingpong: High-Frequency Spike Vision-based Robot Learning for Precise Striking in Table Tennis Game
Jun 07, 2025

Learning to control high-speed objects in the real world remains a challenging frontier in robotics. Table tennis serves as an ideal testbed for this problem, demanding both rapid interception of fast-moving balls and precise adjustment of their trajectories. This task presents two fundamental challenges: it requires a high-precision vision system capable of accurately predicting ball trajectories, and it necessitates intelligent strategic planning to ensure precise ball placement to target regions. The dynamic nature of table tennis, coupled with its real-time response requirements, makes it particularly well-suited for advancing robotic control capabilities in fast-paced, precision-critical domains. In this paper, we present SpikePingpong, a novel system that integrates spike-based vision with imitation learning for high-precision robotic table tennis. Our approach introduces two key attempts that directly address the aforementioned challenges: SONIC, a spike camera-based module that achieves millimeter-level precision in ball-racket contact prediction by compensating for real-world uncertainties such as air resistance and friction; and IMPACT, a strategic planning module that enables accurate ball placement to targeted table regions. The system harnesses a 20 kHz spike camera for high-temporal resolution ball tracking, combined with efficient neural network models for real-time trajectory correction and stroke planning. Experimental results demonstrate that SpikePingpong achieves a remarkable 91% success rate for 30 cm accuracy target area and 71% in the more challenging 20 cm accuracy task, surpassing previous state-of-the-art approaches by 38% and 37% respectively. These significant performance improvements enable the robust implementation of sophisticated tactical gameplay strategies, providing a new research perspective for robotic control in high-speed dynamic tasks.
SpikeGen: Generative Framework for Visual Spike Stream Processing
May 23, 2025Neuromorphic Visual Systems, such as spike cameras, have attracted considerable attention due to their ability to capture clear textures under dynamic conditions. This capability effectively mitigates issues related to motion and aperture blur. However, in contrast to conventional RGB modalities that provide dense spatial information, these systems generate binary, spatially sparse frames as a trade-off for temporally rich visual streams. In this context, generative models emerge as a promising solution to address the inherent limitations of sparse data. These models not only facilitate the conditional fusion of existing information from both spike and RGB modalities but also enable the conditional generation based on latent priors. In this study, we introduce a robust generative processing framework named SpikeGen, designed for visual spike streams captured by spike cameras. We evaluate this framework across multiple tasks involving mixed spike-RGB modalities, including conditional image/video deblurring, dense frame reconstruction from spike streams, and high-speed scene novel-view synthesis. Supported by comprehensive experimental results, we demonstrate that leveraging the latent space operation abilities of generative models allows us to effectively address the sparsity of spatial information while fully exploiting the temporal richness of spike streams, thereby promoting a synergistic enhancement of different visual modalities.
UniCTokens: Boosting Personalized Understanding and Generation via Unified Concept Tokens
May 20, 2025Personalized models have demonstrated remarkable success in understanding and generating concepts provided by users. However, existing methods use separate concept tokens for understanding and generation, treating these tasks in isolation. This may result in limitations for generating images with complex prompts. For example, given the concept $\langle bo\rangle$, generating "$\langle bo\rangle$ wearing its hat" without additional textual descriptions of its hat. We call this kind of generation personalized knowledge-driven generation. To address the limitation, we present UniCTokens, a novel framework that effectively integrates personalized information into a unified vision language model (VLM) for understanding and generation. UniCTokens trains a set of unified concept tokens to leverage complementary semantics, boosting two personalized tasks. Moreover, we propose a progressive training strategy with three stages: understanding warm-up, bootstrapping generation from understanding, and deepening understanding from generation to enhance mutual benefits between both tasks. To quantitatively evaluate the unified VLM personalization, we present UnifyBench, the first benchmark for assessing concept understanding, concept generation, and knowledge-driven generation. Experimental results on UnifyBench indicate that UniCTokens shows competitive performance compared to leading methods in concept understanding, concept generation, and achieving state-of-the-art results in personalized knowledge-driven generation. Our research demonstrates that enhanced understanding improves generation, and the generation process can yield valuable insights into understanding. Our code and dataset will be released at: \href{https://github.com/arctanxarc/UniCTokens}{https://github.com/arctanxarc/UniCTokens}.
MoLe-VLA: Dynamic Layer-skipping Vision Language Action Model via Mixture-of-Layers for Efficient Robot Manipulation
Mar 26, 2025Multimodal Large Language Models (MLLMs) excel in understanding complex language and visual data, enabling generalist robotic systems to interpret instructions and perform embodied tasks. Nevertheless, their real-world deployment is hindered by substantial computational and storage demands. Recent insights into the homogeneous patterns in the LLM layer have inspired sparsification techniques to address these challenges, such as early exit and token pruning. However, these methods often neglect the critical role of the final layers that encode the semantic information most relevant to downstream robotic tasks. Aligning with the recent breakthrough of the Shallow Brain Hypothesis (SBH) in neuroscience and the mixture of experts in model sparsification, we conceptualize each LLM layer as an expert and propose a Mixture-of-Layers Vision-Language-Action model (MoLe-VLA, or simply MoLe) architecture for dynamic LLM layer activation. We introduce a Spatial-Temporal Aware Router (STAR) for MoLe to selectively activate only parts of the layers based on the robot's current state, mimicking the brain's distinct signal pathways specialized for cognition and causal reasoning. Additionally, to compensate for the cognitive ability of LLMs lost in MoLe, we devise a Cognition Self-Knowledge Distillation (CogKD) framework. CogKD enhances the understanding of task demands and improves the generation of task-relevant action sequences by leveraging cognitive features. Extensive experiments conducted in both RLBench simulation and real-world environments demonstrate the superiority of MoLe-VLA in both efficiency and performance. Specifically, MoLe-VLA achieves an 8% improvement in the mean success rate across ten tasks while reducing computational costs by up to x5.6 compared to standard LLMs.
Advancing Mobile GUI Agents: A Verifier-Driven Approach to Practical Deployment
Mar 21, 2025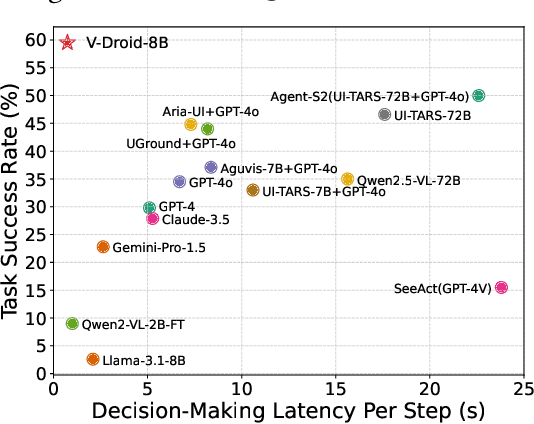
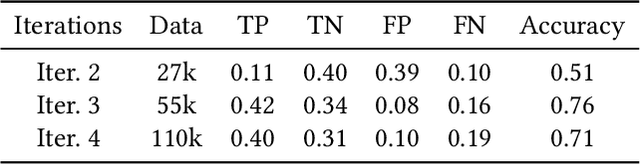
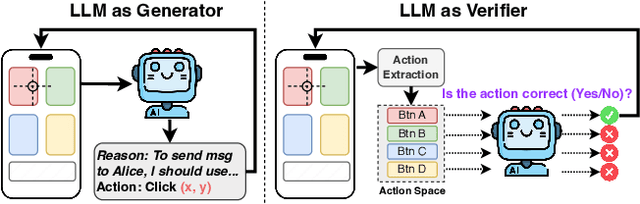
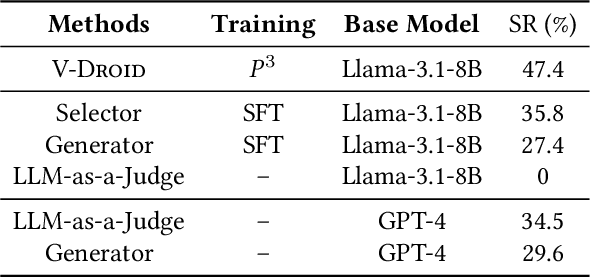
We propose V-Droid, a mobile GUI task automation agent. Unlike previous mobile agents that utilize Large Language Models (LLMs) as generators to directly generate actions at each step, V-Droid employs LLMs as verifiers to evaluate candidate actions before making final decisions. To realize this novel paradigm, we introduce a comprehensive framework for constructing verifier-driven mobile agents: the discretized action space construction coupled with the prefilling-only workflow to accelerate the verification process, the pair-wise progress preference training to significantly enhance the verifier's decision-making capabilities, and the scalable human-agent joint annotation scheme to efficiently collect the necessary data at scale. V-Droid sets a new state-of-the-art task success rate across several public mobile task automation benchmarks: 59.5% on AndroidWorld, 38.3% on AndroidLab, and 49% on MobileAgentBench, surpassing existing agents by 9.5%, 2.1%, and 9%, respectively. Furthermore, V-Droid achieves an impressively low latency of 0.7 seconds per step, making it the first mobile agent capable of delivering near-real-time, effective decision-making capabilities.
Expanding Deep Learning-based Sensing Systems with Multi-Source Knowledge Transfer
Dec 05, 2024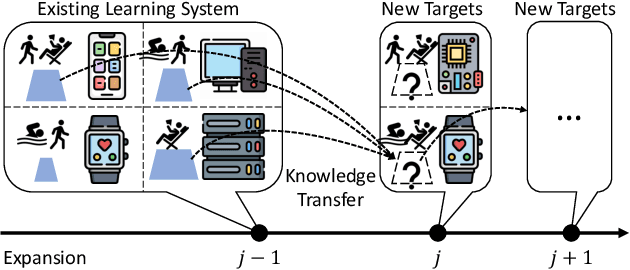
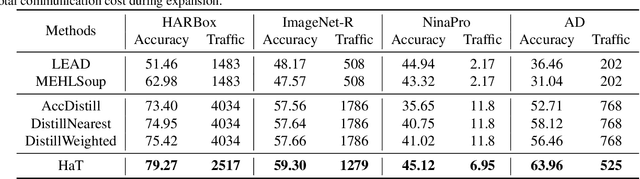
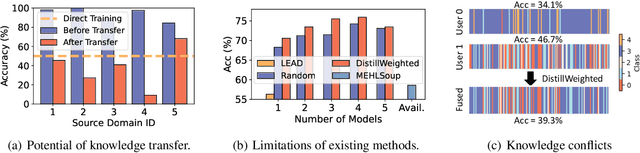
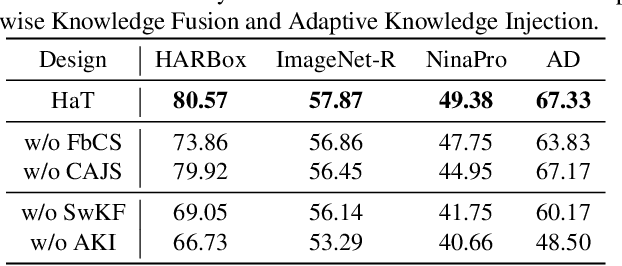
Expanding the existing sensing systems to provide high-quality deep learning models for more domains, such as new users or environments, is challenged by the limited labeled data and the data and device heterogeneities. While knowledge distillation methods could overcome label scarcity and device heterogeneity, they assume the teachers are fully reliable and overlook the data heterogeneity, which prevents the direct adoption of existing models. To address this problem, this paper proposes an efficient knowledge transfer framework, HaKT, to expand sensing systems. It first selects multiple high-quality models from the system at a low cost and then fuses their knowledge by assigning sample-wise weights to their predictions. Later, the fused knowledge is selectively injected into the customized models for new domains based on the knowledge quality. Extensive experiments on different tasks, modalities, and settings show that HaKT outperforms stat-of-the-art baselines by at most 16.5% accuracy and saves up to 39% communication traffic.
Proactive Gradient Conflict Mitigation in Multi-Task Learning: A Sparse Training Perspective
Nov 27, 2024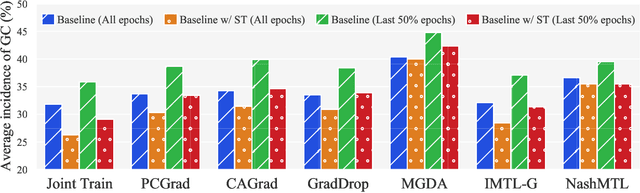
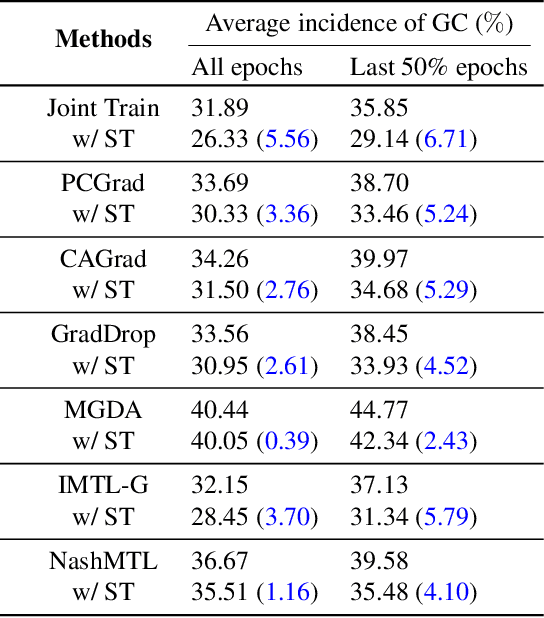
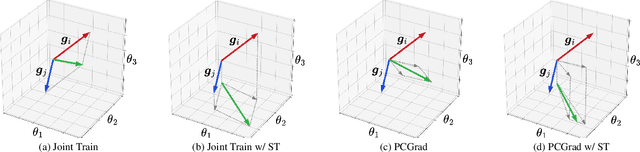
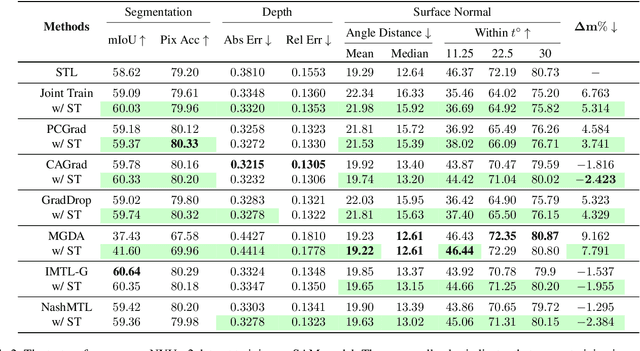
Advancing towards generalist agents necessitates the concurrent processing of multiple tasks using a unified model, thereby underscoring the growing significance of simultaneous model training on multiple downstream tasks. A common issue in multi-task learning is the occurrence of gradient conflict, which leads to potential competition among different tasks during joint training. This competition often results in improvements in one task at the expense of deterioration in another. Although several optimization methods have been developed to address this issue by manipulating task gradients for better task balancing, they cannot decrease the incidence of gradient conflict. In this paper, we systematically investigate the occurrence of gradient conflict across different methods and propose a strategy to reduce such conflicts through sparse training (ST), wherein only a portion of the model's parameters are updated during training while keeping the rest unchanged. Our extensive experiments demonstrate that ST effectively mitigates conflicting gradients and leads to superior performance. Furthermore, ST can be easily integrated with gradient manipulation techniques, thus enhancing their effectiveness.
Training-free Regional Prompting for Diffusion Transformers
Nov 04, 2024



Diffusion models have demonstrated excellent capabilities in text-to-image generation. Their semantic understanding (i.e., prompt following) ability has also been greatly improved with large language models (e.g., T5, Llama). However, existing models cannot perfectly handle long and complex text prompts, especially when the text prompts contain various objects with numerous attributes and interrelated spatial relationships. While many regional prompting methods have been proposed for UNet-based models (SD1.5, SDXL), but there are still no implementations based on the recent Diffusion Transformer (DiT) architecture, such as SD3 and FLUX.1.In this report, we propose and implement regional prompting for FLUX.1 based on attention manipulation, which enables DiT with fined-grained compositional text-to-image generation capability in a training-free manner. Code is available at https://github.com/antonioo-c/Regional-Prompting-FLUX.
Multimodal Large Language Models for Bioimage Analysis
Jul 29, 2024Rapid advancements in imaging techniques and analytical methods over the past decade have revolutionized our ability to comprehensively probe the biological world at multiple scales, pinpointing the type, quantity, location, and even temporal dynamics of biomolecules. The surge in data complexity and volume presents significant challenges in translating this wealth of information into knowledge. The recently emerged Multimodal Large Language Models (MLLMs) exhibit strong emergent capacities, such as understanding, analyzing, reasoning, and generalization. With these capabilities, MLLMs hold promise to extract intricate information from biological images and data obtained through various modalities, thereby expediting our biological understanding and aiding in the development of novel computational frameworks. Previously, such capabilities were mostly attributed to humans for interpreting and summarizing meaningful conclusions from comprehensive observations and analysis of biological images. However, the current development of MLLMs shows increasing promise in serving as intelligent assistants or agents for augmenting human researchers in biology research