 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge[CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster
Dec 02, 2024![Figure 1 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F8-Table1-1.png&w=640&q=75)
![Figure 2 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F2-Figure2-1.png&w=640&q=75)
![Figure 3 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F5-Figure3-1.png&w=640&q=75)
![Figure 4 for [CLS] Attention is All You Need for Training-Free Visual Token Pruning: Make VLM Inference Faster](/_next/image?url=https%3A%2F%2Ffigures.semanticscholar.org%2Fb02159650df9813f25db4afd4f094e53bccd526c%2F9-Table3-1.png&w=640&q=75)
Large vision-language models (VLMs) often rely on a substantial number of visual tokens when interacting with large language models (LLMs), which has proven to be inefficient. Recent efforts have aimed to accelerate VLM inference by pruning visual tokens. Most existing methods assess the importance of visual tokens based on the text-visual cross-attentions in LLMs. In this study, we find that the cross-attentions between text and visual tokens in LLMs are inaccurate. Pruning tokens based on these inaccurate attentions leads to significant performance degradation, especially at high reduction ratios. To this end, we introduce FasterVLM, a simple yet effective training-free visual token pruning method that evaluates the importance of visual tokens more accurately by utilizing attentions between the [CLS] token and image tokens from the visual encoder. Since FasterVLM eliminates redundant visual tokens immediately after the visual encoder, ensuring they do not interact with LLMs and resulting in faster VLM inference. It is worth noting that, benefiting from the accuracy of [CLS] cross-attentions, FasterVLM can prune 95\% of visual tokens while maintaining 90\% of the performance of LLaVA-1.5-7B. We apply FasterVLM to various VLMs, including LLaVA-1.5, LLaVA-NeXT, and Video-LLaVA, to demonstrate its effectiveness. Experimental results show that our FasterVLM maintains strong performance across various VLM architectures and reduction ratios, significantly outperforming existing text-visual attention-based methods. Our code is available at https://github.com/Theia-4869/FasterVLM.
MMTrail: A Multimodal Trailer Video Dataset with Language and Music Descriptions
Jul 30, 2024



Massive multi-modality datasets play a significant role in facilitating the success of large video-language models. However, current video-language datasets primarily provide text descriptions for visual frames, considering audio to be weakly related information. They usually overlook exploring the potential of inherent audio-visual correlation, leading to monotonous annotation within each modality instead of comprehensive and precise descriptions. Such ignorance results in the difficulty of multiple cross-modality studies. To fulfill this gap, we present MMTrail, a large-scale multi-modality video-language dataset incorporating more than 20M trailer clips with visual captions, and 2M high-quality clips with multimodal captions. Trailers preview full-length video works and integrate context, visual frames, and background music. In particular, the trailer has two main advantages: (1) the topics are diverse, and the content characters are of various types, e.g., film, news, and gaming. (2) the corresponding background music is custom-designed, making it more coherent with the visual context. Upon these insights, we propose a systemic captioning framework, achieving various modality annotations with more than 27.1k hours of trailer videos. Here, to ensure the caption retains music perspective while preserving the authority of visual context, we leverage the advanced LLM to merge all annotations adaptively. In this fashion, our MMtrail dataset potentially paves the path for fine-grained large multimodal-language model training. In experiments, we provide evaluation metrics and benchmark results on our dataset, demonstrating the high quality of our annotation and its effectiveness for model training.
Decomposing the Neurons: Activation Sparsity via Mixture of Experts for Continual Test Time Adaptation
May 26, 2024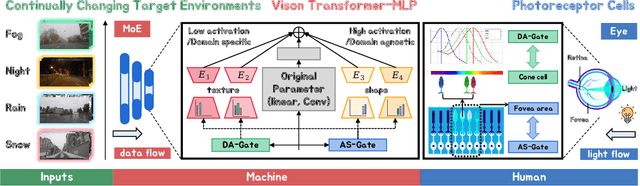
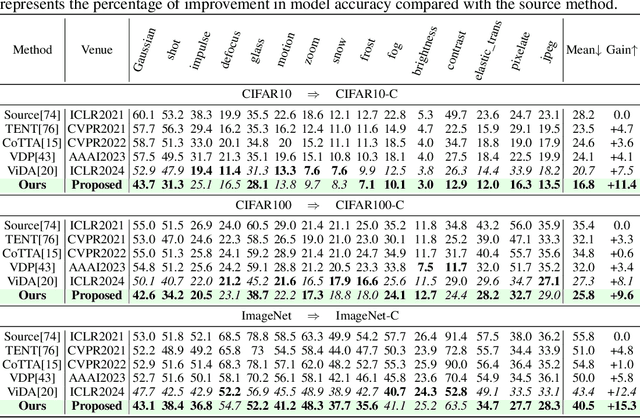

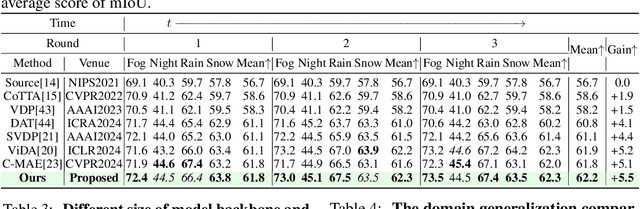
Continual Test-Time Adaptation (CTTA), which aims to adapt the pre-trained model to ever-evolving target domains, emerges as an important task for vision models. As current vision models appear to be heavily biased towards texture, continuously adapting the model from one domain distribution to another can result in serious catastrophic forgetting. Drawing inspiration from the human visual system's adeptness at processing both shape and texture according to the famous Trichromatic Theory, we explore the integration of a Mixture-of-Activation-Sparsity-Experts (MoASE) as an adapter for the CTTA task. Given the distinct reaction of neurons with low/high activation to domain-specific/agnostic features, MoASE decomposes the neural activation into high-activation and low-activation components with a non-differentiable Spatial Differentiate Dropout (SDD). Based on the decomposition, we devise a multi-gate structure comprising a Domain-Aware Gate (DAG) that utilizes domain information to adaptive combine experts that process the post-SDD sparse activations of different strengths, and the Activation Sparsity Gate (ASG) that adaptively assigned feature selection threshold of the SDD for different experts for more precise feature decomposition. Finally, we introduce a Homeostatic-Proximal (HP) loss to bypass the error accumulation problem when continuously adapting the model. Extensive experiments on four prominent benchmarks substantiate that our methodology achieves state-of-the-art performance in both classification and segmentation CTTA tasks. Our code is now available at https://github.com/RoyZry98/MoASE-Pytorch.
DesignEdit: Multi-Layered Latent Decomposition and Fusion for Unified & Accurate Image Editing
Mar 21, 2024



Recently, how to achieve precise image editing has attracted increasing attention, especially given the remarkable success of text-to-image generation models. To unify various spatial-aware image editing abilities into one framework, we adopt the concept of layers from the design domain to manipulate objects flexibly with various operations. The key insight is to transform the spatial-aware image editing task into a combination of two sub-tasks: multi-layered latent decomposition and multi-layered latent fusion. First, we segment the latent representations of the source images into multiple layers, which include several object layers and one incomplete background layer that necessitates reliable inpainting. To avoid extra tuning, we further explore the inner inpainting ability within the self-attention mechanism. We introduce a key-masking self-attention scheme that can propagate the surrounding context information into the masked region while mitigating its impact on the regions outside the mask. Second, we propose an instruction-guided latent fusion that pastes the multi-layered latent representations onto a canvas latent. We also introduce an artifact suppression scheme in the latent space to enhance the inpainting quality. Due to the inherent modular advantages of such multi-layered representations, we can achieve accurate image editing, and we demonstrate that our approach consistently surpasses the latest spatial editing methods, including Self-Guidance and DiffEditor. Last, we show that our approach is a unified framework that supports various accurate image editing tasks on more than six different editing tasks.