 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEVUDA++: Geometric-aware Unsupervised Domain Adaptation for Multi-View 3D Object Detection
Sep 17, 2025Vision-centric Bird's Eye View (BEV) perception holds considerable promise for autonomous driving. Recent studies have prioritized efficiency or accuracy enhancements, yet the issue of domain shift has been overlooked, leading to substantial performance degradation upon transfer. We identify major domain gaps in real-world cross-domain scenarios and initiate the first effort to address the Domain Adaptation (DA) challenge in multi-view 3D object detection for BEV perception. Given the complexity of BEV perception approaches with their multiple components, domain shift accumulation across multi-geometric spaces (e.g., 2D, 3D Voxel, BEV) poses a significant challenge for BEV domain adaptation. In this paper, we introduce an innovative geometric-aware teacher-student framework, BEVUDA++, to diminish this issue, comprising a Reliable Depth Teacher (RDT) and a Geometric Consistent Student (GCS) model. Specifically, RDT effectively blends target LiDAR with dependable depth predictions to generate depth-aware information based on uncertainty estimation, enhancing the extraction of Voxel and BEV features that are essential for understanding the target domain. To collaboratively reduce the domain shift, GCS maps features from multiple spaces into a unified geometric embedding space, thereby narrowing the gap in data distribution between the two domains. Additionally, we introduce a novel Uncertainty-guided Exponential Moving Average (UEMA) to further reduce error accumulation due to domain shifts informed by previously obtained uncertainty guidance. To demonstrate the superiority of our proposed method, we execute comprehensive experiments in four cross-domain scenarios, securing state-of-the-art performance in BEV 3D object detection tasks, e.g., 12.9\% NDS and 9.5\% mAP enhancement on Day-Night adaptation.
SpikeGen: Generative Framework for Visual Spike Stream Processing
May 23, 2025Neuromorphic Visual Systems, such as spike cameras, have attracted considerable attention due to their ability to capture clear textures under dynamic conditions. This capability effectively mitigates issues related to motion and aperture blur. However, in contrast to conventional RGB modalities that provide dense spatial information, these systems generate binary, spatially sparse frames as a trade-off for temporally rich visual streams. In this context, generative models emerge as a promising solution to address the inherent limitations of sparse data. These models not only facilitate the conditional fusion of existing information from both spike and RGB modalities but also enable the conditional generation based on latent priors. In this study, we introduce a robust generative processing framework named SpikeGen, designed for visual spike streams captured by spike cameras. We evaluate this framework across multiple tasks involving mixed spike-RGB modalities, including conditional image/video deblurring, dense frame reconstruction from spike streams, and high-speed scene novel-view synthesis. Supported by comprehensive experimental results, we demonstrate that leveraging the latent space operation abilities of generative models allows us to effectively address the sparsity of spatial information while fully exploiting the temporal richness of spike streams, thereby promoting a synergistic enhancement of different visual modalities.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
MoLe-VLA: Dynamic Layer-skipping Vision Language Action Model via Mixture-of-Layers for Efficient Robot Manipulation
Mar 26, 2025Multimodal Large Language Models (MLLMs) excel in understanding complex language and visual data, enabling generalist robotic systems to interpret instructions and perform embodied tasks. Nevertheless, their real-world deployment is hindered by substantial computational and storage demands. Recent insights into the homogeneous patterns in the LLM layer have inspired sparsification techniques to address these challenges, such as early exit and token pruning. However, these methods often neglect the critical role of the final layers that encode the semantic information most relevant to downstream robotic tasks. Aligning with the recent breakthrough of the Shallow Brain Hypothesis (SBH) in neuroscience and the mixture of experts in model sparsification, we conceptualize each LLM layer as an expert and propose a Mixture-of-Layers Vision-Language-Action model (MoLe-VLA, or simply MoLe) architecture for dynamic LLM layer activation. We introduce a Spatial-Temporal Aware Router (STAR) for MoLe to selectively activate only parts of the layers based on the robot's current state, mimicking the brain's distinct signal pathways specialized for cognition and causal reasoning. Additionally, to compensate for the cognitive ability of LLMs lost in MoLe, we devise a Cognition Self-Knowledge Distillation (CogKD) framework. CogKD enhances the understanding of task demands and improves the generation of task-relevant action sequences by leveraging cognitive features. Extensive experiments conducted in both RLBench simulation and real-world environments demonstrate the superiority of MoLe-VLA in both efficiency and performance. Specifically, MoLe-VLA achieves an 8% improvement in the mean success rate across ten tasks while reducing computational costs by up to x5.6 compared to standard LLMs.
Second FRCSyn-onGoing: Winning Solutions and Post-Challenge Analysis to Improve Face Recognition with Synthetic Data
Dec 02, 2024Synthetic data is gaining increasing popularity for face recognition technologies, mainly due to the privacy concerns and challenges associated with obtaining real data, including diverse scenarios, quality, and demographic groups, among others. It also offers some advantages over real data, such as the large amount of data that can be generated or the ability to customize it to adapt to specific problem-solving needs. To effectively use such data, face recognition models should also be specifically designed to exploit synthetic data to its fullest potential. In order to promote the proposal of novel Generative AI methods and synthetic data, and investigate the application of synthetic data to better train face recognition systems, we introduce the 2nd FRCSyn-onGoing challenge, based on the 2nd Face Recognition Challenge in the Era of Synthetic Data (FRCSyn), originally launched at CVPR 2024. This is an ongoing challenge that provides researchers with an accessible platform to benchmark i) the proposal of novel Generative AI methods and synthetic data, and ii) novel face recognition systems that are specifically proposed to take advantage of synthetic data. We focus on exploring the use of synthetic data both individually and in combination with real data to solve current challenges in face recognition such as demographic bias, domain adaptation, and performance constraints in demanding situations, such as age disparities between training and testing, changes in the pose, or occlusions. Very interesting findings are obtained in this second edition, including a direct comparison with the first one, in which synthetic databases were restricted to DCFace and GANDiffFace.
EVA: An Embodied World Model for Future Video Anticipation
Oct 20, 2024



World models integrate raw data from various modalities, such as images and language to simulate comprehensive interactions in the world, thereby displaying crucial roles in fields like mixed reality and robotics. Yet, applying the world model for accurate video prediction is quite challenging due to the complex and dynamic intentions of the various scenes in practice. In this paper, inspired by the human rethinking process, we decompose the complex video prediction into four meta-tasks that enable the world model to handle this issue in a more fine-grained manner. Alongside these tasks, we introduce a new benchmark named Embodied Video Anticipation Benchmark (EVA-Bench) to provide a well-rounded evaluation. EVA-Bench focused on evaluating the video prediction ability of human and robot actions, presenting significant challenges for both the language model and the generation model. Targeting embodied video prediction, we propose the Embodied Video Anticipator (EVA), a unified framework aiming at video understanding and generation. EVA integrates a video generation model with a visual language model, effectively combining reasoning capabilities with high-quality generation. Moreover, to enhance the generalization of our framework, we tailor-designed a multi-stage pretraining paradigm that adaptatively ensembles LoRA to produce high-fidelity results. Extensive experiments on EVA-Bench highlight the potential of EVA to significantly improve performance in embodied scenes, paving the way for large-scale pre-trained models in real-world prediction tasks.
PAT: Pruning-Aware Tuning for Large Language Models
Aug 27, 2024
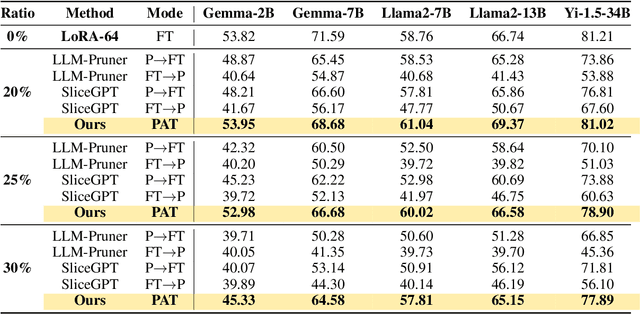
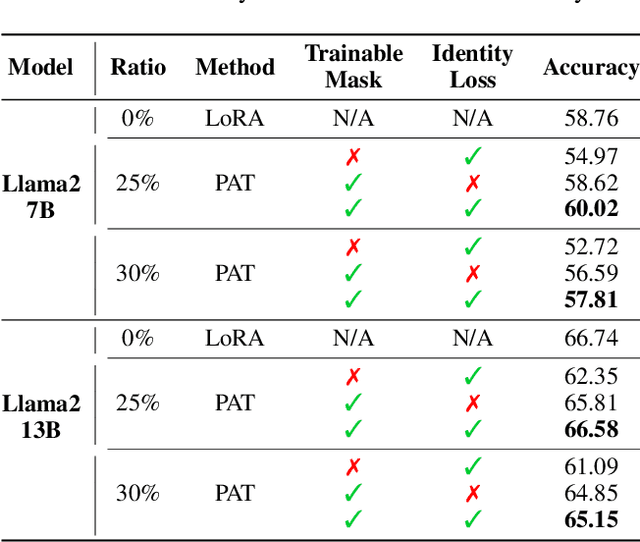
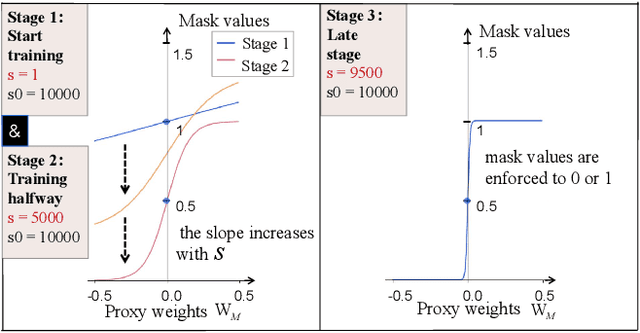
Large language models (LLMs) excel in language tasks, especially with supervised fine-tuning after pre-training. However, their substantial memory and computational requirements hinder practical applications. Structural pruning, which reduces less significant weight dimensions, is one solution. Yet, traditional post-hoc pruning often leads to significant performance loss, with limited recovery from further fine-tuning due to reduced capacity. Since the model fine-tuning refines the general and chaotic knowledge in pre-trained models, we aim to incorporate structural pruning with the fine-tuning, and propose the Pruning-Aware Tuning (PAT) paradigm to eliminate model redundancy while preserving the model performance to the maximum extend. Specifically, we insert the innovative Hybrid Sparsification Modules (HSMs) between the Attention and FFN components to accordingly sparsify the upstream and downstream linear modules. The HSM comprises a lightweight operator and a globally shared trainable mask. The lightweight operator maintains a training overhead comparable to that of LoRA, while the trainable mask unifies the channels to be sparsified, ensuring structural pruning. Additionally, we propose the Identity Loss which decouples the transformation and scaling properties of the HSMs to enhance training robustness. Extensive experiments demonstrate that PAT excels in both performance and efficiency. For example, our Llama2-7b model with a 25\% pruning ratio achieves 1.33$\times$ speedup while outperforming the LoRA-finetuned model by up to 1.26\% in accuracy with a similar training cost. Code: https://github.com/kriskrisliu/PAT_Pruning-Aware-Tuning
FactorLLM: Factorizing Knowledge via Mixture of Experts for Large Language Models
Aug 15, 2024



Recent research has demonstrated that Feed-Forward Networks (FFNs) in Large Language Models (LLMs) play a pivotal role in storing diverse linguistic and factual knowledge. Conventional methods frequently face challenges due to knowledge confusion stemming from their monolithic and redundant architectures, which calls for more efficient solutions with minimal computational overhead, particularly for LLMs. In this paper, we explore the FFN computation paradigm in LLMs and introduce FactorLLM, a novel approach that decomposes well-trained dense FFNs into sparse sub-networks without requiring any further modifications, while maintaining the same level of performance. Furthermore, we embed a router from the Mixture-of-Experts (MoE), combined with our devised Prior-Approximate (PA) loss term that facilitates the dynamic activation of experts and knowledge adaptation, thereby accelerating computational processes and enhancing performance using minimal training data and fine-tuning steps. FactorLLM thus enables efficient knowledge factorization and activates select groups of experts specifically tailored to designated tasks, emulating the interactive functional segmentation of the human brain. Extensive experiments across various benchmarks demonstrate the effectiveness of our proposed FactorLLM which achieves comparable performance to the source model securing up to 85% model performance while obtaining over a 30% increase in inference speed. Code: https://github.com/zhenwuweihe/FactorLLM.
MMTrail: A Multimodal Trailer Video Dataset with Language and Music Descriptions
Jul 30, 2024



Massive multi-modality datasets play a significant role in facilitating the success of large video-language models. However, current video-language datasets primarily provide text descriptions for visual frames, considering audio to be weakly related information. They usually overlook exploring the potential of inherent audio-visual correlation, leading to monotonous annotation within each modality instead of comprehensive and precise descriptions. Such ignorance results in the difficulty of multiple cross-modality studies. To fulfill this gap, we present MMTrail, a large-scale multi-modality video-language dataset incorporating more than 20M trailer clips with visual captions, and 2M high-quality clips with multimodal captions. Trailers preview full-length video works and integrate context, visual frames, and background music. In particular, the trailer has two main advantages: (1) the topics are diverse, and the content characters are of various types, e.g., film, news, and gaming. (2) the corresponding background music is custom-designed, making it more coherent with the visual context. Upon these insights, we propose a systemic captioning framework, achieving various modality annotations with more than 27.1k hours of trailer videos. Here, to ensure the caption retains music perspective while preserving the authority of visual context, we leverage the advanced LLM to merge all annotations adaptively. In this fashion, our MMtrail dataset potentially paves the path for fine-grained large multimodal-language model training. In experiments, we provide evaluation metrics and benchmark results on our dataset, demonstrating the high quality of our annotation and its effectiveness for model training.
Implicit Neural Image Field for Biological Microscopy Image Compression
May 29, 2024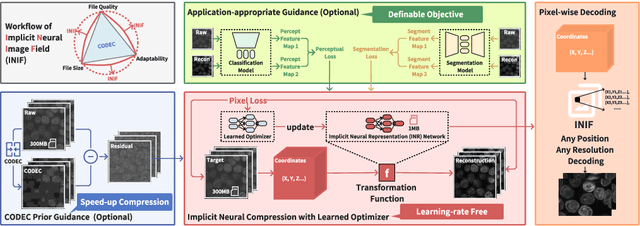


The rapid pace of innovation in biological microscopy imaging has led to large images, putting pressure on data storage and impeding efficient sharing, management, and visualization. This necessitates the development of efficient compression solutions. Traditional CODEC methods struggle to adapt to the diverse bioimaging data and often suffer from sub-optimal compression. In this study, we propose an adaptive compression workflow based on Implicit Neural Representation (INR). This approach permits application-specific compression objectives, capable of compressing images of any shape and arbitrary pixel-wise decompression. We demonstrated on a wide range of microscopy images from real applications that our workflow not only achieved high, controllable compression ratios (e.g., 512x) but also preserved detailed information critical for downstream analysis.