 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoBiQuant: Mixture-of-Bits Quantization for Token-Adaptive Elastic LLMs
Feb 21, 2026Changing runtime complexity on cloud and edge devices necessitates elastic large language model (LLM) deployment, where an LLM can be inferred with various quantization precisions based on available computational resources. However, it has been observed that the calibration parameters for quantization are typically linked to specific precisions, which presents challenges during elastic-precision calibration and precision switching at runtime. In this work, we attribute the source of varying calibration parameters to the varying token-level sensitivity caused by a precision-dependent outlier migration phenomenon.Motivated by this observation, we propose \texttt{MoBiQuant}, a novel Mixture-of-Bits quantization framework that adjusts weight precision for elastic LLM inference based on token sensitivity. Specifically, we propose the many-in-one recursive residual quantization that can iteratively reconstruct higher-precision weights and the token-aware router to dynamically select the number of residual bit slices. MoBiQuant enables smooth precision switching while improving generalization for the distribution of token outliers. Experimental results demonstrate that MoBiQuant exhibits strong elasticity, enabling it to match the performance of bit-specific calibrated PTQ on LLaMA3-8B without repeated calibration.
Dynamic Mix Precision Routing for Efficient Multi-step LLM Interaction
Feb 02, 2026Large language models (LLM) achieve strong performance in long-horizon decision-making tasks through multi-step interaction and reasoning at test time. While practitioners commonly believe a higher task success rate necessitates the use of a larger and stronger LLM model, multi-step interaction with a large LLM incurs prohibitive inference cost. To address this problem, we explore the use of low-precision quantized LLM in the long-horizon decision-making process. Based on the observation of diverse sensitivities among interaction steps, we propose a dynamic mix-precision routing framework that adaptively selects between high-precision and low-precision LLMs at each decision step. The router is trained via a two-stage pipeline, consisting of KL-divergence-based supervised learning that identifies precision-sensitive steps, followed by Group-Relative Policy Optimization (GRPO) to further improve task success rates. Experiments on ALFWorld demonstrate that our approach achieves a great improvement on accuracy-cost trade-off over single-precision baselines and heuristic routing methods.
Bridging Structure and Appearance: Topological Features for Robust Self-Supervised Segmentation
Dec 30, 2025Self-supervised semantic segmentation methods often fail when faced with appearance ambiguities. We argue that this is due to an over-reliance on unstable, appearance-based features such as shadows, glare, and local textures. We propose \textbf{GASeg}, a novel framework that bridges appearance and geometry by leveraging stable topological information. The core of our method is Differentiable Box-Counting (\textbf{DBC}) module, which quantifies multi-scale topological statistics from two parallel streams: geometric-based features and appearance-based features. To force the model to learn these stable structural representations, we introduce Topological Augmentation (\textbf{TopoAug}), an adversarial strategy that simulates real-world ambiguities by applying morphological operators to the input images. A multi-objective loss, \textbf{GALoss}, then explicitly enforces cross-modal alignment between geometric-based and appearance-based features. Extensive experiments demonstrate that GASeg achieves state-of-the-art performance on four benchmarks, including COCO-Stuff, Cityscapes, and PASCAL, validating our approach of bridging geometry and appearance via topological information.
SQAP-VLA: A Synergistic Quantization-Aware Pruning Framework for High-Performance Vision-Language-Action Models
Sep 11, 2025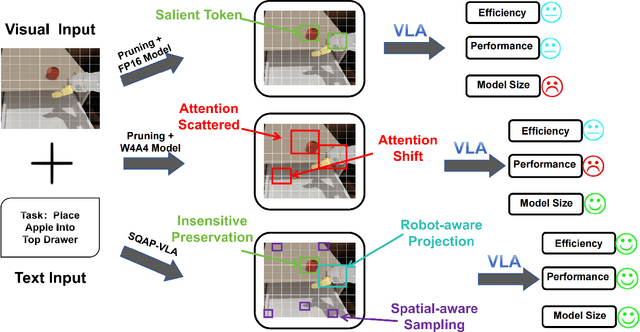
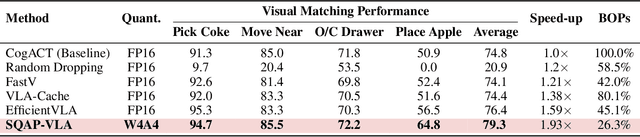
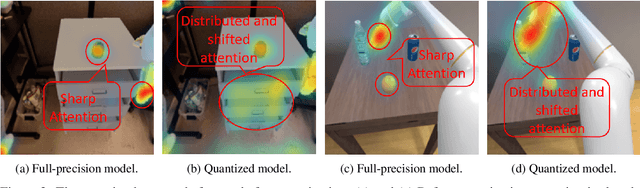
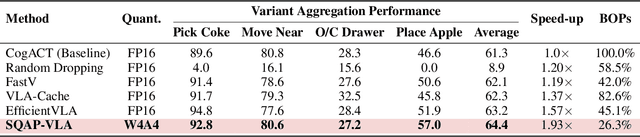
Vision-Language-Action (VLA) models exhibit unprecedented capabilities for embodied intelligence. However, their extensive computational and memory costs hinder their practical deployment. Existing VLA compression and acceleration approaches conduct quantization or token pruning in an ad-hoc manner but fail to enable both for a holistic efficiency improvement due to an observed incompatibility. This work introduces SQAP-VLA, the first structured, training-free VLA inference acceleration framework that simultaneously enables state-of-the-art quantization and token pruning. We overcome the incompatibility by co-designing the quantization and token pruning pipeline, where we propose new quantization-aware token pruning criteria that work on an aggressively quantized model while improving the quantizer design to enhance pruning effectiveness. When applied to standard VLA models, SQAP-VLA yields significant gains in computational efficiency and inference speed while successfully preserving core model performance, achieving a $\times$1.93 speedup and up to a 4.5\% average success rate enhancement compared to the original model.
MSQ: Memory-Efficient Bit Sparsification Quantization
Jul 30, 2025As deep neural networks (DNNs) see increased deployment on mobile and edge devices, optimizing model efficiency has become crucial. Mixed-precision quantization is widely favored, as it offers a superior balance between efficiency and accuracy compared to uniform quantization. However, finding the optimal precision for each layer is challenging. Recent studies utilizing bit-level sparsity have shown promise, yet they often introduce substantial training complexity and high GPU memory requirements. In this paper, we propose Memory-Efficient Bit Sparsification Quantization (MSQ), a novel approach that addresses these limitations. MSQ applies a round-clamp quantizer to enable differentiable computation of the least significant bits (LSBs) from model weights. It further employs regularization to induce sparsity in these LSBs, enabling effective precision reduction without explicit bit-level parameter splitting. Additionally, MSQ incorporates Hessian information, allowing the simultaneous pruning of multiple LSBs to further enhance training efficiency. Experimental results show that MSQ achieves up to 8.00x reduction in trainable parameters and up to 86% reduction in training time compared to previous bit-level quantization, while maintaining competitive accuracy and compression rates. This makes it a practical solution for training efficient DNNs on resource-constrained devices.
Is Attention Required for Transformer Inference? Explore Function-preserving Attention Replacement
May 29, 2025While transformers excel across vision and language pretraining tasks, their reliance on attention mechanisms poses challenges for inference efficiency, especially on edge and embedded accelerators with limited parallelism and memory bandwidth. Hinted by the observed redundancy of attention at inference time, we hypothesize that though the model learns complicated token dependency through pretraining, the inference-time sequence-to-sequence mapping in each attention layer is actually ''simple'' enough to be represented with a much cheaper function. In this work, we explore FAR, a Function-preserving Attention Replacement framework that replaces all attention blocks in pretrained transformers with learnable sequence-to-sequence modules, exemplified by an LSTM. FAR optimize a multi-head LSTM architecture with a block-wise distillation objective and a global structural pruning framework to achieve a family of efficient LSTM-based models from pretrained transformers. We validate FAR on the DeiT vision transformer family and demonstrate that it matches the accuracy of the original models on ImageNet and multiple downstream tasks with reduced parameters and latency. Further analysis shows that FAR preserves the semantic token relationships and the token-to-token correlation learned in the transformer's attention module.
SAFER: Sharpness Aware layer-selective Finetuning for Enhanced Robustness in vision transformers
Jan 02, 2025



Vision transformers (ViTs) have become essential backbones in advanced computer vision applications and multi-modal foundation models. Despite their strengths, ViTs remain vulnerable to adversarial perturbations, comparable to or even exceeding the vulnerability of convolutional neural networks (CNNs). Furthermore, the large parameter count and complex architecture of ViTs make them particularly prone to adversarial overfitting, often compromising both clean and adversarial accuracy. This paper mitigates adversarial overfitting in ViTs through a novel, layer-selective fine-tuning approach: SAFER. Instead of optimizing the entire model, we identify and selectively fine-tune a small subset of layers most susceptible to overfitting, applying sharpness-aware minimization to these layers while freezing the rest of the model. Our method consistently enhances both clean and adversarial accuracy over baseline approaches. Typical improvements are around 5%, with some cases achieving gains as high as 20% across various ViT architectures and datasets.
Taming Sensitive Weights : Noise Perturbation Fine-tuning for Robust LLM Quantization
Dec 08, 2024Quantization is a critical step to enable efficient LLM serving under limited resource. However, previous research observes that certain weights in the LLM, known as outliers, are significantly sensitive to quantization noises. Existing quantization methods leave these outliers as floating points or higher precisions to retain performance, posting challenges on the efficient hardware deployment of the mixed-precision model. This work investigates an alternative way to tame the sensitive weights' impact on the quantization error, by reducing the loss Hessian trace with respect to outliers through an efficient fine-tuning process. We propose Noise Perturbation Fine-tuning (NPFT), which identifies outlier weights and add random weight perturbations on the outliers as the model going through a PEFT optimization. NPFT tames the sensitivity of outlier weights so that the quantized model performance can be improved without special treatment to the outliers. When applied to OPT and LLaMA models, our NPFT method achieves stable performance improvements for both uniform and non-uniform quantizers, while also offering better inference efficiency. Notably, the simplest RTN can achieve performance on par with GPTQ using our NPFT on LLaMA2-7B-4bits benchmark.
Personalized Multimodal Large Language Models: A Survey
Dec 03, 2024Multimodal Large Language Models (MLLMs) have become increasingly important due to their state-of-the-art performance and ability to integrate multiple data modalities, such as text, images, and audio, to perform complex tasks with high accuracy. This paper presents a comprehensive survey on personalized multimodal large language models, focusing on their architecture, training methods, and applications. We propose an intuitive taxonomy for categorizing the techniques used to personalize MLLMs to individual users, and discuss the techniques accordingly. Furthermore, we discuss how such techniques can be combined or adapted when appropriate, highlighting their advantages and underlying rationale. We also provide a succinct summary of personalization tasks investigated in existing research, along with the evaluation metrics commonly used. Additionally, we summarize the datasets that are useful for benchmarking personalized MLLMs. Finally, we outline critical open challenges. This survey aims to serve as a valuable resource for researchers and practitioners seeking to understand and advance the development of personalized multimodal large language models.
A Survey of Small Language Models
Oct 25, 2024


Small Language Models (SLMs) have become increasingly important due to their efficiency and performance to perform various language tasks with minimal computational resources, making them ideal for various settings including on-device, mobile, edge devices, among many others. In this article, we present a comprehensive survey on SLMs, focusing on their architectures, training techniques, and model compression techniques. We propose a novel taxonomy for categorizing the methods used to optimize SLMs, including model compression, pruning, and quantization techniques. We summarize the benchmark datasets that are useful for benchmarking SLMs along with the evaluation metrics commonly used. Additionally, we highlight key open challenges that remain to be addressed. Our survey aims to serve as a valuable resource for researchers and practitioners interested in developing and deploying small yet efficient language models.