 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoBiQuant: Mixture-of-Bits Quantization for Token-Adaptive Elastic LLMs
Feb 21, 2026Changing runtime complexity on cloud and edge devices necessitates elastic large language model (LLM) deployment, where an LLM can be inferred with various quantization precisions based on available computational resources. However, it has been observed that the calibration parameters for quantization are typically linked to specific precisions, which presents challenges during elastic-precision calibration and precision switching at runtime. In this work, we attribute the source of varying calibration parameters to the varying token-level sensitivity caused by a precision-dependent outlier migration phenomenon.Motivated by this observation, we propose \texttt{MoBiQuant}, a novel Mixture-of-Bits quantization framework that adjusts weight precision for elastic LLM inference based on token sensitivity. Specifically, we propose the many-in-one recursive residual quantization that can iteratively reconstruct higher-precision weights and the token-aware router to dynamically select the number of residual bit slices. MoBiQuant enables smooth precision switching while improving generalization for the distribution of token outliers. Experimental results demonstrate that MoBiQuant exhibits strong elasticity, enabling it to match the performance of bit-specific calibrated PTQ on LLaMA3-8B without repeated calibration.
MSQ: Memory-Efficient Bit Sparsification Quantization
Jul 30, 2025As deep neural networks (DNNs) see increased deployment on mobile and edge devices, optimizing model efficiency has become crucial. Mixed-precision quantization is widely favored, as it offers a superior balance between efficiency and accuracy compared to uniform quantization. However, finding the optimal precision for each layer is challenging. Recent studies utilizing bit-level sparsity have shown promise, yet they often introduce substantial training complexity and high GPU memory requirements. In this paper, we propose Memory-Efficient Bit Sparsification Quantization (MSQ), a novel approach that addresses these limitations. MSQ applies a round-clamp quantizer to enable differentiable computation of the least significant bits (LSBs) from model weights. It further employs regularization to induce sparsity in these LSBs, enabling effective precision reduction without explicit bit-level parameter splitting. Additionally, MSQ incorporates Hessian information, allowing the simultaneous pruning of multiple LSBs to further enhance training efficiency. Experimental results show that MSQ achieves up to 8.00x reduction in trainable parameters and up to 86% reduction in training time compared to previous bit-level quantization, while maintaining competitive accuracy and compression rates. This makes it a practical solution for training efficient DNNs on resource-constrained devices.
Taming Sensitive Weights : Noise Perturbation Fine-tuning for Robust LLM Quantization
Dec 08, 2024Quantization is a critical step to enable efficient LLM serving under limited resource. However, previous research observes that certain weights in the LLM, known as outliers, are significantly sensitive to quantization noises. Existing quantization methods leave these outliers as floating points or higher precisions to retain performance, posting challenges on the efficient hardware deployment of the mixed-precision model. This work investigates an alternative way to tame the sensitive weights' impact on the quantization error, by reducing the loss Hessian trace with respect to outliers through an efficient fine-tuning process. We propose Noise Perturbation Fine-tuning (NPFT), which identifies outlier weights and add random weight perturbations on the outliers as the model going through a PEFT optimization. NPFT tames the sensitivity of outlier weights so that the quantized model performance can be improved without special treatment to the outliers. When applied to OPT and LLaMA models, our NPFT method achieves stable performance improvements for both uniform and non-uniform quantizers, while also offering better inference efficiency. Notably, the simplest RTN can achieve performance on par with GPTQ using our NPFT on LLaMA2-7B-4bits benchmark.
Review helps learn better: Temporal Supervised Knowledge Distillation
Jul 03, 2023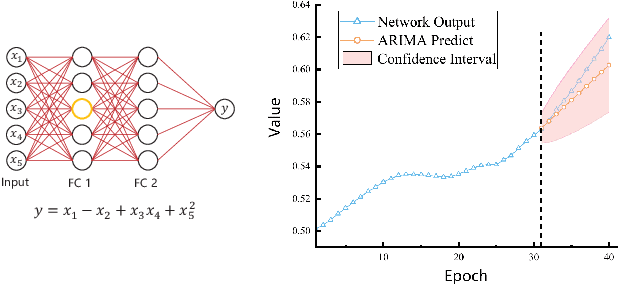
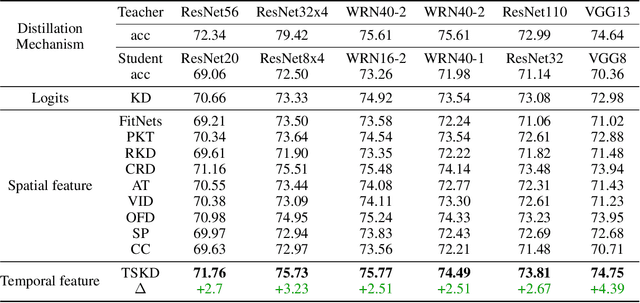
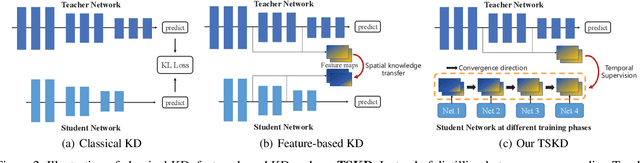

Reviewing plays an important role when learning knowledge. The knowledge acquisition at a certain time point may be strongly inspired with the help of previous experience. Thus the knowledge growing procedure should show strong relationship along the temporal dimension. In our research, we find that during the network training, the evolution of feature map follows temporal sequence property. A proper temporal supervision may further improve the network training performance. Inspired by this observation, we design a novel knowledge distillation method. Specifically, we extract the spatiotemporal features in the different training phases of student by convolutional Long Short-term memory network (Conv-LSTM). Then, we train the student net through a dynamic target, rather than static teacher network features. This process realizes the refinement of old knowledge in student network, and utilizes them to assist current learning. Extensive experiments verify the effectiveness and advantages of our method over existing knowledge distillation methods, including various network architectures, different tasks (image classification and object detection) .