 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeqWalker: Sequential-Horizon Vision-and-Language Navigation with Hierarchical Planning
Jan 08, 2026Sequential-Horizon Vision-and-Language Navigation (SH-VLN) presents a challenging scenario where agents should sequentially execute multi-task navigation guided by complex, long-horizon language instructions. Current vision-and-language navigation models exhibit significant performance degradation with such multi-task instructions, as information overload impairs the agent's ability to attend to observationally relevant details. To address this problem, we propose SeqWalker, a navigation model built on a hierarchical planning framework. Our SeqWalker features: i) A High-Level Planner that dynamically selects global instructions into contextually relevant sub-instructions based on the agent's current visual observations, thus reducing cognitive load; ii) A Low-Level Planner incorporating an Exploration-Verification strategy that leverages the inherent logical structure of instructions for trajectory error correction. To evaluate SH-VLN performance, we also extend the IVLN dataset and establish a new benchmark. Extensive experiments are performed to demonstrate the superiority of the proposed SeqWalker.
CRISP: Contrastive Residual Injection and Semantic Prompting for Continual Video Instance Segmentation
Aug 14, 2025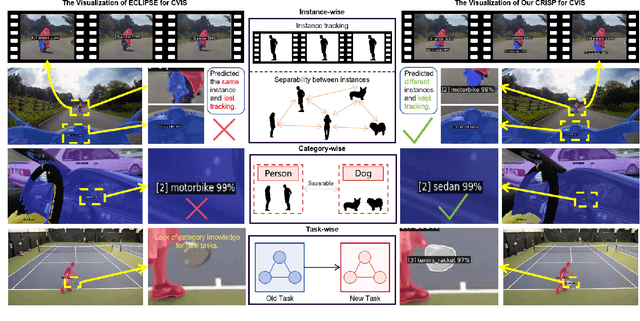
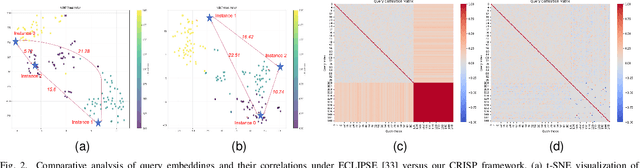
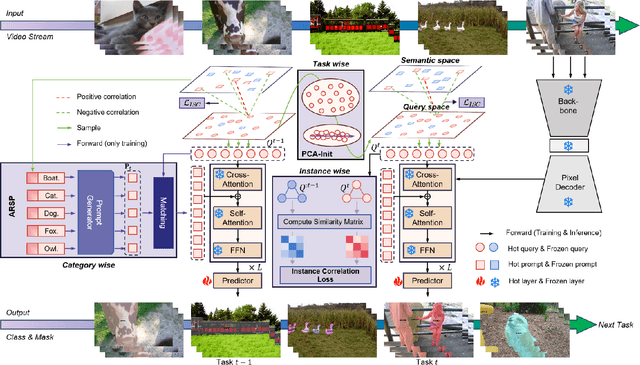
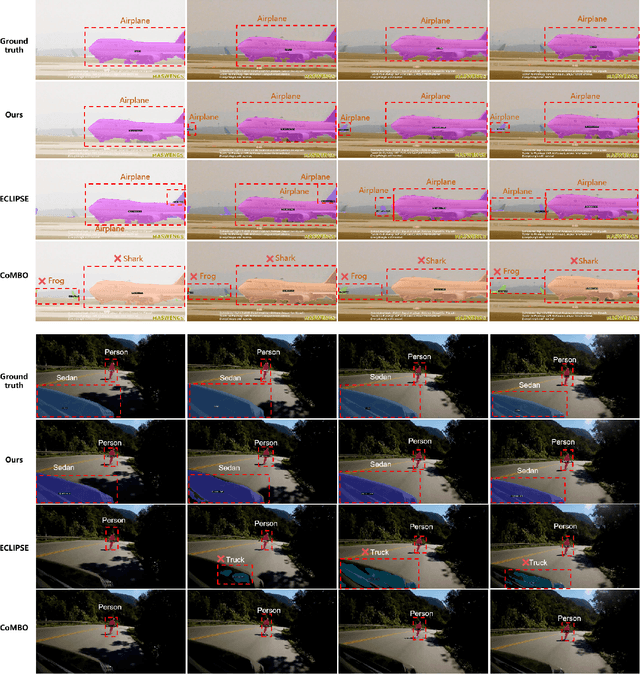
Continual video instance segmentation demands both the plasticity to absorb new object categories and the stability to retain previously learned ones, all while preserving temporal consistency across frames. In this work, we introduce Contrastive Residual Injection and Semantic Prompting (CRISP), an earlier attempt tailored to address the instance-wise, category-wise, and task-wise confusion in continual video instance segmentation. For instance-wise learning, we model instance tracking and construct instance correlation loss, which emphasizes the correlation with the prior query space while strengthening the specificity of the current task query. For category-wise learning, we build an adaptive residual semantic prompt (ARSP) learning framework, which constructs a learnable semantic residual prompt pool generated by category text and uses an adjustive query-prompt matching mechanism to build a mapping relationship between the query of the current task and the semantic residual prompt. Meanwhile, a semantic consistency loss based on the contrastive learning is introduced to maintain semantic coherence between object queries and residual prompts during incremental training. For task-wise learning, to ensure the correlation at the inter-task level within the query space, we introduce a concise yet powerful initialization strategy for incremental prompts. Extensive experiments on YouTube-VIS-2019 and YouTube-VIS-2021 datasets demonstrate that CRISP significantly outperforms existing continual segmentation methods in the long-term continual video instance segmentation task, avoiding catastrophic forgetting and effectively improving segmentation and classification performance. The code is available at https://github.com/01upup10/CRISP.
Deep Convolutional Neural Networks with Zero-Padding: Feature Extraction and Learning
Jul 30, 2023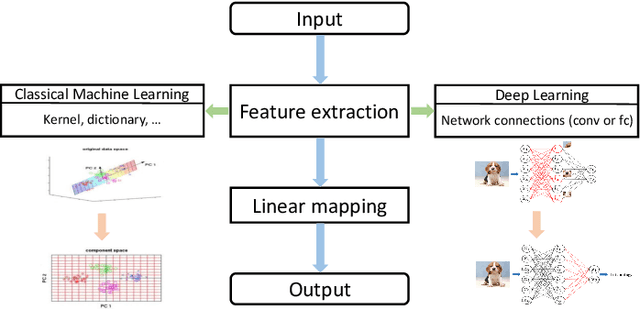

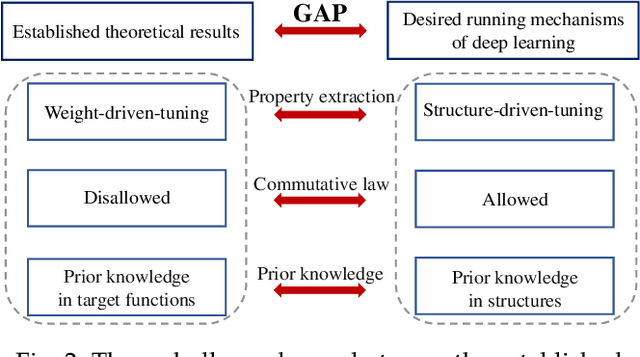
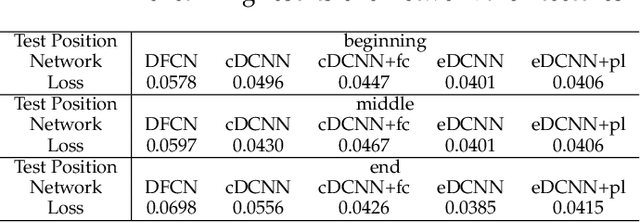
This paper studies the performance of deep convolutional neural networks (DCNNs) with zero-padding in feature extraction and learning. After verifying the roles of zero-padding in enabling translation-equivalence, and pooling in its translation-invariance driven nature, we show that with similar number of free parameters, any deep fully connected networks (DFCNs) can be represented by DCNNs with zero-padding. This demonstrates that DCNNs with zero-padding is essentially better than DFCNs in feature extraction. Consequently, we derive universal consistency of DCNNs with zero-padding and show its translation-invariance in the learning process. All our theoretical results are verified by numerical experiments including both toy simulations and real-data running.
Review helps learn better: Temporal Supervised Knowledge Distillation
Jul 03, 2023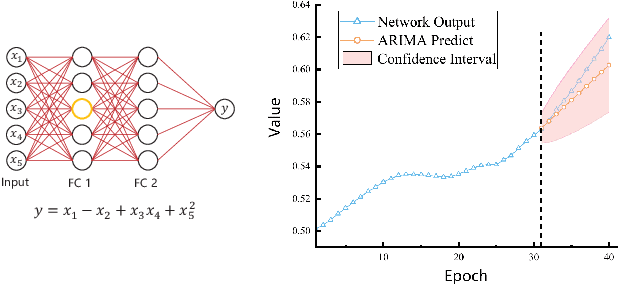
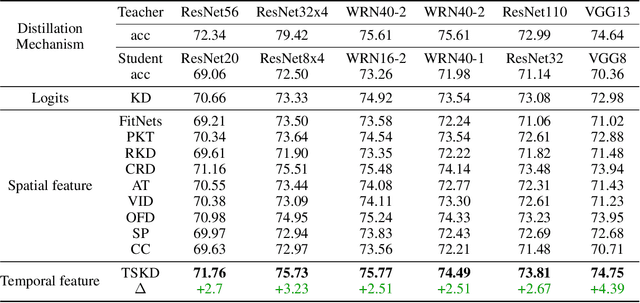
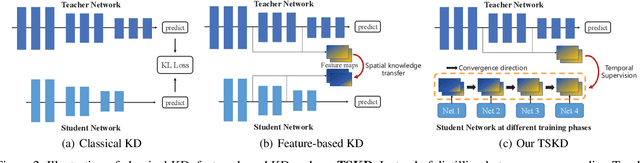

Reviewing plays an important role when learning knowledge. The knowledge acquisition at a certain time point may be strongly inspired with the help of previous experience. Thus the knowledge growing procedure should show strong relationship along the temporal dimension. In our research, we find that during the network training, the evolution of feature map follows temporal sequence property. A proper temporal supervision may further improve the network training performance. Inspired by this observation, we design a novel knowledge distillation method. Specifically, we extract the spatiotemporal features in the different training phases of student by convolutional Long Short-term memory network (Conv-LSTM). Then, we train the student net through a dynamic target, rather than static teacher network features. This process realizes the refinement of old knowledge in student network, and utilizes them to assist current learning. Extensive experiments verify the effectiveness and advantages of our method over existing knowledge distillation methods, including various network architectures, different tasks (image classification and object detection) .