 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNon-Rival Data as Rival Products: An Encapsulation-Forging Approach for Data Synthesis
Nov 10, 2025

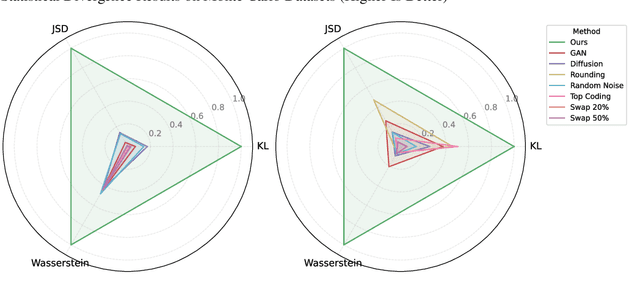

The non-rival nature of data creates a dilemma for firms: sharing data unlocks value but risks eroding competitive advantage. Existing data synthesis methods often exacerbate this problem by creating data with symmetric utility, allowing any party to extract its value. This paper introduces the Encapsulation-Forging (EnFo) framework, a novel approach to generate rival synthetic data with asymmetric utility. EnFo operates in two stages: it first encapsulates predictive knowledge from the original data into a designated ``key'' model, and then forges a synthetic dataset by optimizing the data to intentionally overfit this key model. This process transforms non-rival data into a rival product, ensuring its value is accessible only to the intended model, thereby preventing unauthorized use and preserving the data owner's competitive edge. Our framework demonstrates remarkable sample efficiency, matching the original data's performance with a fraction of its size, while providing robust privacy protection and resistance to misuse. EnFo offers a practical solution for firms to collaborate strategically without compromising their core analytical advantage.
Feature Qualification by Deep Nets: A Constructive Approach
Mar 24, 2025The great success of deep learning has stimulated avid research activities in verifying the power of depth in theory, a common consensus of which is that deep net are versatile in approximating and learning numerous functions. Such a versatility certainly enhances the understanding of the power of depth, but makes it difficult to judge which data features are crucial in a specific learning task. This paper proposes a constructive approach to equip deep nets for the feature qualification purpose. Using the product-gate nature and localized approximation property of deep nets with sigmoid activation (deep sigmoid nets), we succeed in constructing a linear deep net operator that possesses optimal approximation performance in approximating smooth and radial functions. Furthermore, we provide theoretical evidences that the constructed deep net operator is capable of qualifying multiple features such as the smoothness and radialness of the target functions.
Component-based Sketching for Deep ReLU Nets
Sep 21, 2024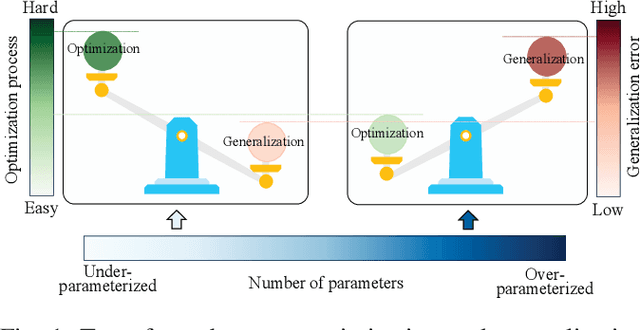
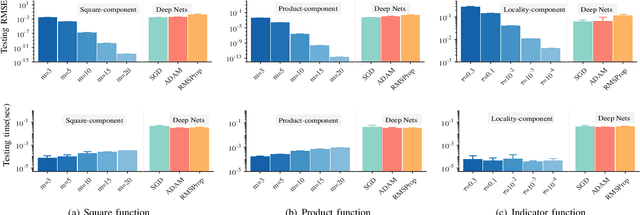
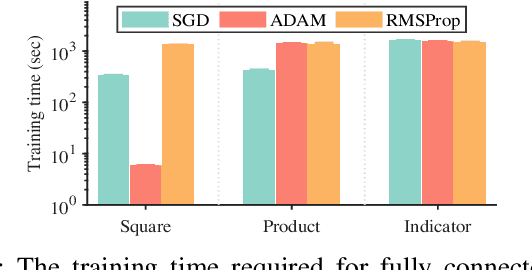
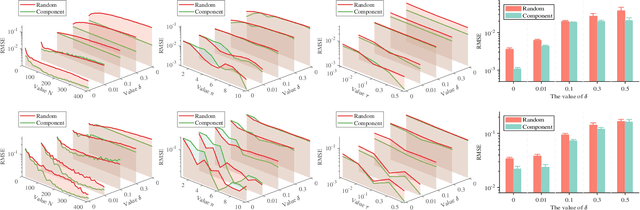
Deep learning has made profound impacts in the domains of data mining and AI, distinguished by the groundbreaking achievements in numerous real-world applications and the innovative algorithm design philosophy. However, it suffers from the inconsistency issue between optimization and generalization, as achieving good generalization, guided by the bias-variance trade-off principle, favors under-parameterized networks, whereas ensuring effective convergence of gradient-based algorithms demands over-parameterized networks. To address this issue, we develop a novel sketching scheme based on deep net components for various tasks. Specifically, we use deep net components with specific efficacy to build a sketching basis that embodies the advantages of deep networks. Subsequently, we transform deep net training into a linear empirical risk minimization problem based on the constructed basis, successfully avoiding the complicated convergence analysis of iterative algorithms. The efficacy of the proposed component-based sketching is validated through both theoretical analysis and numerical experiments. Theoretically, we show that the proposed component-based sketching provides almost optimal rates in approximating saturated functions for shallow nets and also achieves almost optimal generalization error bounds. Numerically, we demonstrate that, compared with the existing gradient-based training methods, component-based sketching possesses superior generalization performance with reduced training costs.
Lepskii Principle for Distributed Kernel Ridge Regression
Sep 08, 2024Parameter selection without communicating local data is quite challenging in distributed learning, exhibing an inconsistency between theoretical analysis and practical application of it in tackling distributively stored data. Motivated by the recently developed Lepskii principle and non-privacy communication protocol for kernel learning, we propose a Lepskii principle to equip distributed kernel ridge regression (DKRR) and consequently develop an adaptive DKRR with Lepskii principle (Lep-AdaDKRR for short) by using a double weighted averaging synthesization scheme. We deduce optimal learning rates for Lep-AdaDKRR and theoretically show that Lep-AdaDKRR succeeds in adapting to the regularity of regression functions, effective dimension decaying rate of kernels and different metrics of generalization, which fills the gap of the mentioned inconsistency between theory and application.
Integral Operator Approaches for Scattered Data Fitting on Spheres
Jan 31, 2024
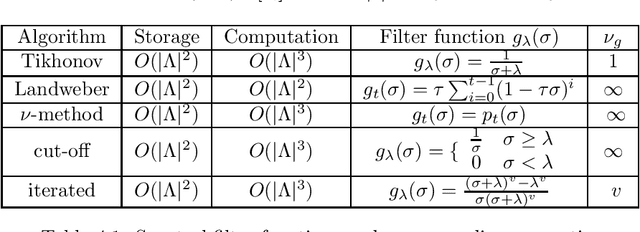
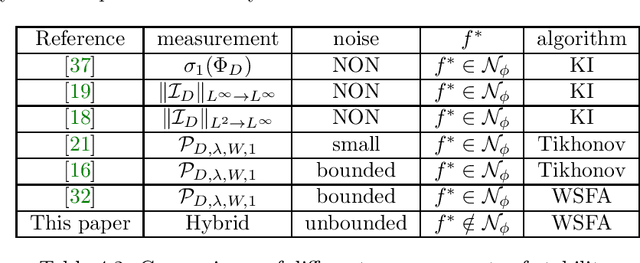
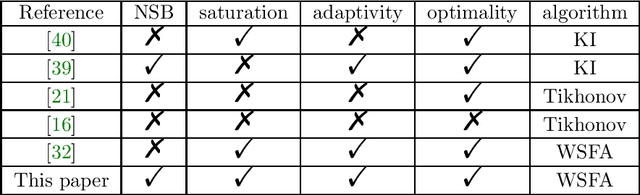
This paper focuses on scattered data fitting problems on spheres. We study the approximation performance of a class of weighted spectral filter algorithms, including Tikhonov regularization, Landaweber iteration, spectral cut-off, and iterated Tikhonov, in fitting noisy data with possibly unbounded random noise. For the analysis, we develop an integral operator approach that can be regarded as an extension of the widely used sampling inequality approach and norming set method in the community of scattered data fitting. After providing an equivalence between the operator differences and quadrature rules, we succeed in deriving optimal Sobolev-type error estimates of weighted spectral filter algorithms. Our derived error estimates do not suffer from the saturation phenomenon for Tikhonov regularization in the literature, native-space-barrier for existing error analysis and adapts to different embedding spaces. We also propose a divide-and-conquer scheme to equip weighted spectral filter algorithms to reduce their computational burden and present the optimal approximation error bounds.
Weighted Spectral Filters for Kernel Interpolation on Spheres: Estimates of Prediction Accuracy for Noisy Data
Jan 16, 2024
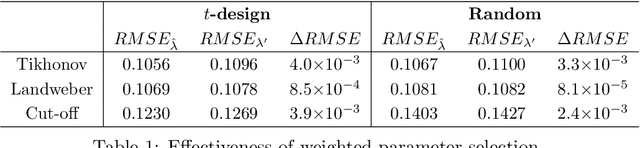


Spherical radial-basis-based kernel interpolation abounds in image sciences including geophysical image reconstruction, climate trends description and image rendering due to its excellent spatial localization property and perfect approximation performance. However, in dealing with noisy data, kernel interpolation frequently behaves not so well due to the large condition number of the kernel matrix and instability of the interpolation process. In this paper, we introduce a weighted spectral filter approach to reduce the condition number of the kernel matrix and then stabilize kernel interpolation. The main building blocks of the proposed method are the well developed spherical positive quadrature rules and high-pass spectral filters. Using a recently developed integral operator approach for spherical data analysis, we theoretically demonstrate that the proposed weighted spectral filter approach succeeds in breaking through the bottleneck of kernel interpolation, especially in fitting noisy data. We provide optimal approximation rates of the new method to show that our approach does not compromise the predicting accuracy. Furthermore, we conduct both toy simulations and two real-world data experiments with synthetically added noise in geophysical image reconstruction and climate image processing to verify our theoretical assertions and show the feasibility of the weighted spectral filter approach.
Adaptive Parameter Selection for Kernel Ridge Regression
Dec 10, 2023This paper focuses on parameter selection issues of kernel ridge regression (KRR). Due to special spectral properties of KRR, we find that delicate subdivision of the parameter interval shrinks the difference between two successive KRR estimates. Based on this observation, we develop an early-stopping type parameter selection strategy for KRR according to the so-called Lepskii-type principle. Theoretical verifications are presented in the framework of learning theory to show that KRR equipped with the proposed parameter selection strategy succeeds in achieving optimal learning rates and adapts to different norms, providing a new record of parameter selection for kernel methods.
Lifting the Veil: Unlocking the Power of Depth in Q-learning
Oct 27, 2023With the help of massive data and rich computational resources, deep Q-learning has been widely used in operations research and management science and has contributed to great success in numerous applications, including recommender systems, supply chains, games, and robotic manipulation. However, the success of deep Q-learning lacks solid theoretical verification and interpretability. The aim of this paper is to theoretically verify the power of depth in deep Q-learning. Within the framework of statistical learning theory, we rigorously prove that deep Q-learning outperforms its traditional version by demonstrating its good generalization error bound. Our results reveal that the main reason for the success of deep Q-learning is the excellent performance of deep neural networks (deep nets) in capturing the special properties of rewards namely, spatial sparseness and piecewise constancy, rather than their large capacities. In this paper, we make fundamental contributions to the field of reinforcement learning by answering to the following three questions: Why does deep Q-learning perform so well? When does deep Q-learning perform better than traditional Q-learning? How many samples are required to achieve a specific prediction accuracy for deep Q-learning? Our theoretical assertions are verified by applying deep Q-learning in the well-known beer game in supply chain management and a simulated recommender system.
Distributed Uncertainty Quantification of Kernel Interpolation on Spheres
Oct 25, 2023For radial basis function (RBF) kernel interpolation of scattered data, Schaback in 1995 proved that the attainable approximation error and the condition number of the underlying interpolation matrix cannot be made small simultaneously. He referred to this finding as an "uncertainty relation", an undesirable consequence of which is that RBF kernel interpolation is susceptible to noisy data. In this paper, we propose and study a distributed interpolation method to manage and quantify the uncertainty brought on by interpolating noisy spherical data of non-negligible magnitude. We also present numerical simulation results showing that our method is practical and robust in terms of handling noisy data from challenging computing environments.
Adaptive Distributed Kernel Ridge Regression: A Feasible Distributed Learning Scheme for Data Silos
Sep 08, 2023



Data silos, mainly caused by privacy and interoperability, significantly constrain collaborations among different organizations with similar data for the same purpose. Distributed learning based on divide-and-conquer provides a promising way to settle the data silos, but it suffers from several challenges, including autonomy, privacy guarantees, and the necessity of collaborations. This paper focuses on developing an adaptive distributed kernel ridge regression (AdaDKRR) by taking autonomy in parameter selection, privacy in communicating non-sensitive information, and the necessity of collaborations in performance improvement into account. We provide both solid theoretical verification and comprehensive experiments for AdaDKRR to demonstrate its feasibility and effectiveness. Theoretically, we prove that under some mild conditions, AdaDKRR performs similarly to running the optimal learning algorithms on the whole data, verifying the necessity of collaborations and showing that no other distributed learning scheme can essentially beat AdaDKRR under the same conditions. Numerically, we test AdaDKRR on both toy simulations and two real-world applications to show that AdaDKRR is superior to other existing distributed learning schemes. All these results show that AdaDKRR is a feasible scheme to defend against data silos, which are highly desired in numerous application regions such as intelligent decision-making, pricing forecasting, and performance prediction for products.