 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComponent-based Sketching for Deep ReLU Nets
Paper and Code
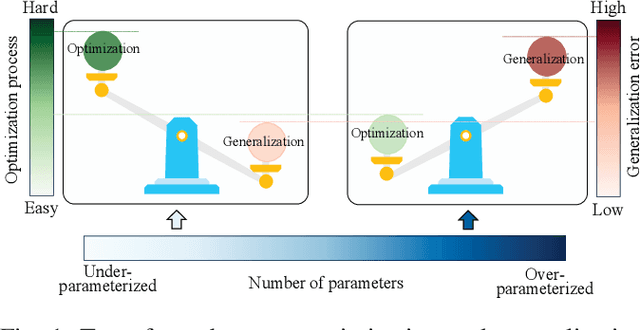
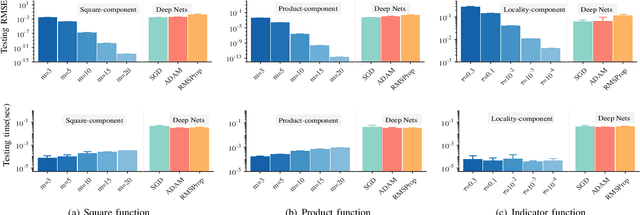
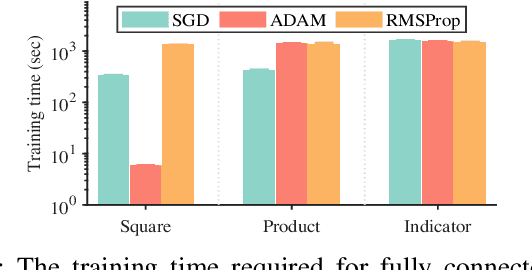
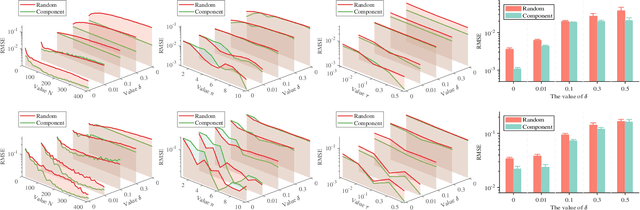
Deep learning has made profound impacts in the domains of data mining and AI, distinguished by the groundbreaking achievements in numerous real-world applications and the innovative algorithm design philosophy. However, it suffers from the inconsistency issue between optimization and generalization, as achieving good generalization, guided by the bias-variance trade-off principle, favors under-parameterized networks, whereas ensuring effective convergence of gradient-based algorithms demands over-parameterized networks. To address this issue, we develop a novel sketching scheme based on deep net components for various tasks. Specifically, we use deep net components with specific efficacy to build a sketching basis that embodies the advantages of deep networks. Subsequently, we transform deep net training into a linear empirical risk minimization problem based on the constructed basis, successfully avoiding the complicated convergence analysis of iterative algorithms. The efficacy of the proposed component-based sketching is validated through both theoretical analysis and numerical experiments. Theoretically, we show that the proposed component-based sketching provides almost optimal rates in approximating saturated functions for shallow nets and also achieves almost optimal generalization error bounds. Numerically, we demonstrate that, compared with the existing gradient-based training methods, component-based sketching possesses superior generalization performance with reduced training costs.