 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDrive-JEPA: Video JEPA Meets Multimodal Trajectory Distillation for End-to-End Driving
Jan 29, 2026End-to-end autonomous driving increasingly leverages self-supervised video pretraining to learn transferable planning representations. However, pretraining video world models for scene understanding has so far brought only limited improvements. This limitation is compounded by the inherent ambiguity of driving: each scene typically provides only a single human trajectory, making it difficult to learn multimodal behaviors. In this work, we propose Drive-JEPA, a framework that integrates Video Joint-Embedding Predictive Architecture (V-JEPA) with multimodal trajectory distillation for end-to-end driving. First, we adapt V-JEPA for end-to-end driving, pretraining a ViT encoder on large-scale driving videos to produce predictive representations aligned with trajectory planning. Second, we introduce a proposal-centric planner that distills diverse simulator-generated trajectories alongside human trajectories, with a momentum-aware selection mechanism to promote stable and safe behavior. When evaluated on NAVSIM, the V-JEPA representation combined with a simple transformer-based decoder outperforms prior methods by 3 PDMS in the perception-free setting. The complete Drive-JEPA framework achieves 93.3 PDMS on v1 and 87.8 EPDMS on v2, setting a new state-of-the-art.
Will It Zero-Shot?: Predicting Zero-Shot Classification Performance For Arbitrary Queries
Jan 27, 2026Vision-Language Models like CLIP create aligned embedding spaces for text and images, making it possible for anyone to build a visual classifier by simply naming the classes they want to distinguish. However, a model that works well in one domain may fail in another, and non-expert users have no straightforward way to assess whether their chosen VLM will work on their problem. We build on prior work using text-only comparisons to evaluate how well a model works for a given natural language task, and explore approaches that also generate synthetic images relevant to that task to evaluate and refine the prediction of zero-shot accuracy. We show that generated imagery to the baseline text-only scores substantially improves the quality of these predictions. Additionally, it gives a user feedback on the kinds of images that were used to make the assessment. Experiments on standard CLIP benchmark datasets demonstrate that the image-based approach helps users predict, without any labeled examples, whether a VLM will be effective for their application.
Will It Zero-Shot?: Will It Zero-Shot?: Predicting Zero-Shot Classification Performance For Arbitrary Queries
Jan 24, 2026Vision-Language Models like CLIP create aligned embedding spaces for text and images, making it possible for anyone to build a visual classifier by simply naming the classes they want to distinguish. However, a model that works well in one domain may fail in another, and non-expert users have no straightforward way to assess whether their chosen VLM will work on their problem. We build on prior work using text-only comparisons to evaluate how well a model works for a given natural language task, and explore approaches that also generate synthetic images relevant to that task to evaluate and refine the prediction of zero-shot accuracy. We show that generated imagery to the baseline text-only scores substantially improves the quality of these predictions. Additionally, it gives a user feedback on the kinds of images that were used to make the assessment. Experiments on standard CLIP benchmark datasets demonstrate that the image-based approach helps users predict, without any labeled examples, whether a VLM will be effective for their application.
Vision-based Wearable Steering Assistance for People with Impaired Vision in Jogging
Aug 01, 2024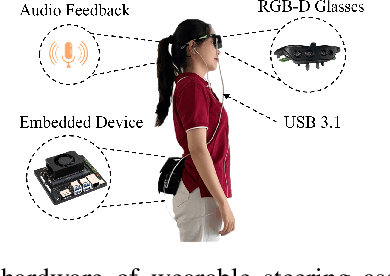



Outdoor sports pose a challenge for people with impaired vision. The demand for higher-speed mobility inspired us to develop a vision-based wearable steering assistance. To ensure broad applicability, we focused on a representative sports environment, the athletics track. Our efforts centered on improving the speed and accuracy of perception, enhancing planning adaptability for the real world, and providing swift and safe assistance for people with impaired vision. In perception, we engineered a lightweight multitask network capable of simultaneously detecting track lines and obstacles. Additionally, due to the limitations of existing datasets for supporting multi-task detection in athletics tracks, we diligently collected and annotated a new dataset (MAT) containing 1000 images. In planning, we integrated the methods of sampling and spline curves, addressing the planning challenges of curves. Meanwhile, we utilized the positions of the track lines and obstacles as constraints to guide people with impaired vision safely along the current track. Our system is deployed on an embedded device, Jetson Orin NX. Through outdoor experiments, it demonstrated adaptability in different sports scenarios, assisting users in achieving free movement of 400-meter at an average speed of 1.34 m/s, meeting the level of normal people in jogging. Our MAT dataset is publicly available from https://github.com/snoopy-l/MAT
Weighted Spectral Filters for Kernel Interpolation on Spheres: Estimates of Prediction Accuracy for Noisy Data
Jan 16, 2024
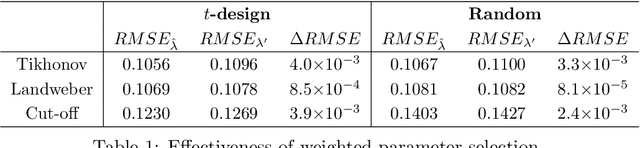


Spherical radial-basis-based kernel interpolation abounds in image sciences including geophysical image reconstruction, climate trends description and image rendering due to its excellent spatial localization property and perfect approximation performance. However, in dealing with noisy data, kernel interpolation frequently behaves not so well due to the large condition number of the kernel matrix and instability of the interpolation process. In this paper, we introduce a weighted spectral filter approach to reduce the condition number of the kernel matrix and then stabilize kernel interpolation. The main building blocks of the proposed method are the well developed spherical positive quadrature rules and high-pass spectral filters. Using a recently developed integral operator approach for spherical data analysis, we theoretically demonstrate that the proposed weighted spectral filter approach succeeds in breaking through the bottleneck of kernel interpolation, especially in fitting noisy data. We provide optimal approximation rates of the new method to show that our approach does not compromise the predicting accuracy. Furthermore, we conduct both toy simulations and two real-world data experiments with synthetically added noise in geophysical image reconstruction and climate image processing to verify our theoretical assertions and show the feasibility of the weighted spectral filter approach.
Data Drift Monitoring for Log Anomaly Detection Pipelines
Oct 17, 2023
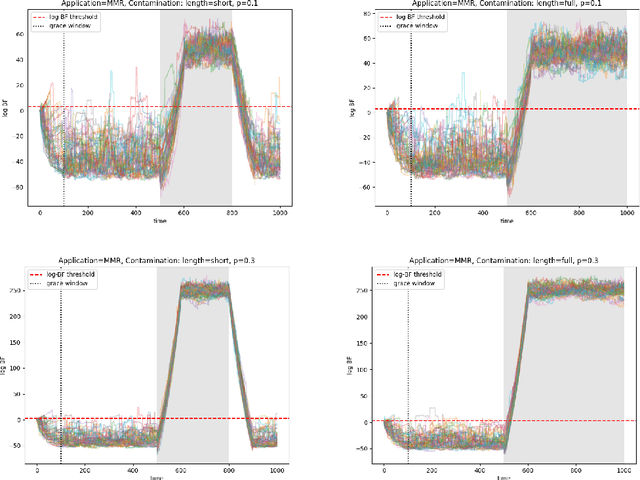
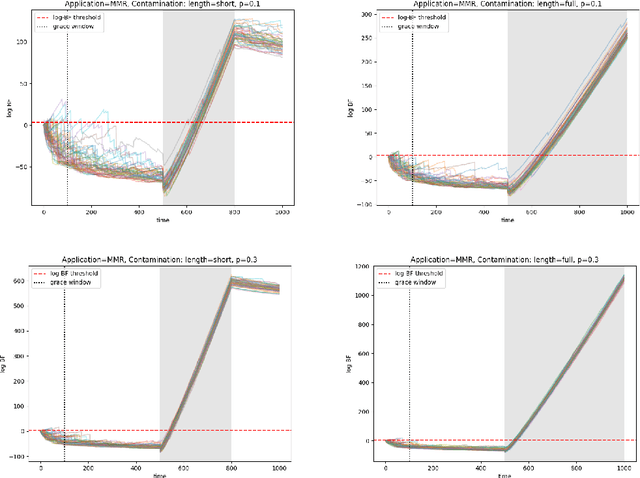
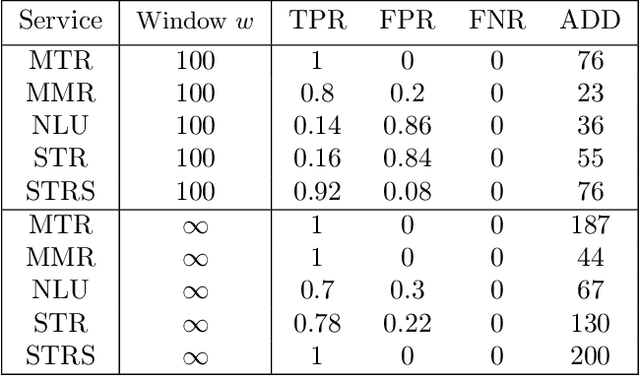
Logs enable the monitoring of infrastructure status and the performance of associated applications. Logs are also invaluable for diagnosing the root causes of any problems that may arise. Log Anomaly Detection (LAD) pipelines automate the detection of anomalies in logs, providing assistance to site reliability engineers (SREs) in system diagnosis. Log patterns change over time, necessitating updates to the LAD model defining the `normal' log activity profile. In this paper, we introduce a Bayes Factor-based drift detection method that identifies when intervention, retraining, and updating of the LAD model are required with human involvement. We illustrate our method using sequences of log activity, both from unaltered data, and simulated activity with controlled levels of anomaly contamination, based on real collected log data.
Towards More Efficient Depression Risk Recognition via Gait
Oct 10, 2023



Depression, a highly prevalent mental illness, affects over 280 million individuals worldwide. Early detection and timely intervention are crucial for promoting remission, preventing relapse, and alleviating the emotional and financial burdens associated with depression. However, patients with depression often go undiagnosed in the primary care setting. Unlike many physiological illnesses, depression lacks objective indicators for recognizing depression risk, and existing methods for depression risk recognition are time-consuming and often encounter a shortage of trained medical professionals. The correlation between gait and depression risk has been empirically established. Gait can serve as a promising objective biomarker, offering the advantage of efficient and convenient data collection. However, current methods for recognizing depression risk based on gait have only been validated on small, private datasets, lacking large-scale publicly available datasets for research purposes. Additionally, these methods are primarily limited to hand-crafted approaches. Gait is a complex form of motion, and hand-crafted gait features often only capture a fraction of the intricate associations between gait and depression risk. Therefore, this study first constructs a large-scale gait database, encompassing over 1,200 individuals, 40,000 gait sequences, and covering six perspectives and three types of attire. Two commonly used psychological scales are provided as depression risk annotations. Subsequently, a deep learning-based depression risk recognition model is proposed, overcoming the limitations of hand-crafted approaches. Through experiments conducted on the constructed large-scale database, the effectiveness of the proposed method is validated, and numerous instructive insights are presented in the paper, highlighting the significant potential of gait-based depression risk recognition.
Adaptive Distributed Kernel Ridge Regression: A Feasible Distributed Learning Scheme for Data Silos
Sep 08, 2023



Data silos, mainly caused by privacy and interoperability, significantly constrain collaborations among different organizations with similar data for the same purpose. Distributed learning based on divide-and-conquer provides a promising way to settle the data silos, but it suffers from several challenges, including autonomy, privacy guarantees, and the necessity of collaborations. This paper focuses on developing an adaptive distributed kernel ridge regression (AdaDKRR) by taking autonomy in parameter selection, privacy in communicating non-sensitive information, and the necessity of collaborations in performance improvement into account. We provide both solid theoretical verification and comprehensive experiments for AdaDKRR to demonstrate its feasibility and effectiveness. Theoretically, we prove that under some mild conditions, AdaDKRR performs similarly to running the optimal learning algorithms on the whole data, verifying the necessity of collaborations and showing that no other distributed learning scheme can essentially beat AdaDKRR under the same conditions. Numerically, we test AdaDKRR on both toy simulations and two real-world applications to show that AdaDKRR is superior to other existing distributed learning schemes. All these results show that AdaDKRR is a feasible scheme to defend against data silos, which are highly desired in numerous application regions such as intelligent decision-making, pricing forecasting, and performance prediction for products.
A reconfigurable multiple-format coherent-dual-band signal generator based on a single optoelectronic oscillation cavity
Aug 06, 2023An optoelectronic oscillation method with reconfigurable multiple formats for simultaneous generation of coherent dual-band signals is proposed and experimentally demonstrated. By introducing a compatible filtering mechanism based on stimulated Brillouin scattering (SBS) effect into a typical Phase-shifted grating Bragg fiber (PS-FBG) notch filtering cavity, dual mode-selection mechanisms which have independent frequency and time tuning mechanism can be constructed. By regulating three controllers, the proposed scheme can work in different states, named mode 1, mode 2 and mode 3. At mode 1 state, a dual single-frequency hopping signals is achieved with 50 ns hopping speed and flexible central frequency and pulse duration ratio. The mode 2 state is realized by applying the Fourier domain mode-locked (FDML) technology into the proposed optoelectrical oscillator, in which dual coherent pulsed single-frequency signal and broadband signal is generated simultaneously. The adjustability of the time duration of the single-frequency signal and the bandwidth of the broadband signal are shown and discussed. The mode 3 state is a dual broadband signal generator which is realized by injecting a triangular wave into the signal laser. The detection performance of the generated broadband signals has also been evaluated by the pulse compression and the phase noise figure. The proposed method may provide a multifunctional radar system signal generator based on the simply external controllers, which can realize low-phase-noise or multifunctional detection with high resolution imaging ability, especially in a complex interference environment.
Hard negative examples are hard, but useful
Jul 24, 2020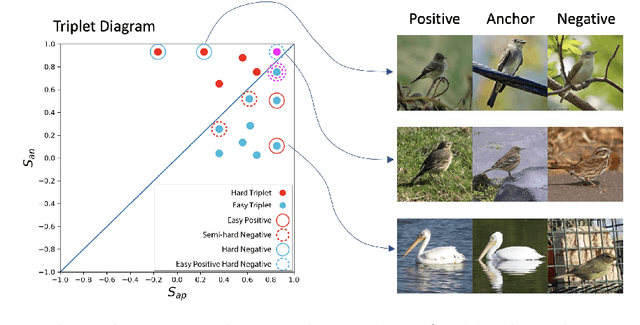
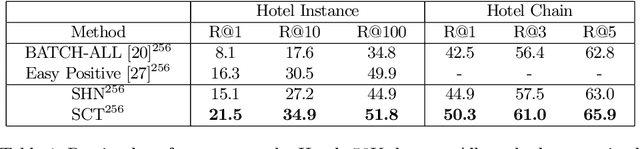
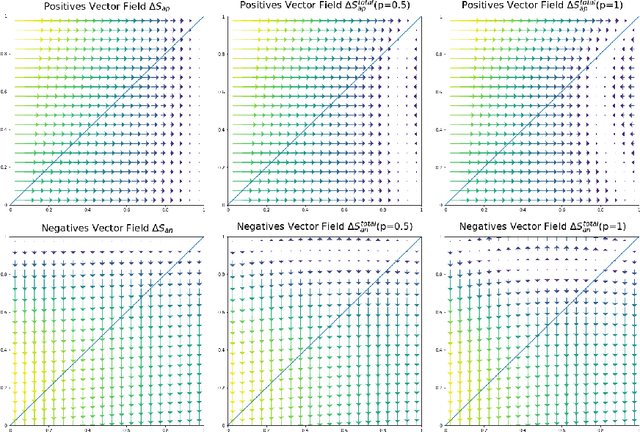
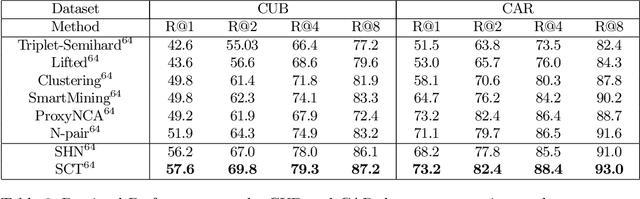
Triplet loss is an extremely common approach to distance metric learning. Representations of images from the same class are optimized to be mapped closer together in an embedding space than representations of images from different classes. Much work on triplet losses focuses on selecting the most useful triplets of images to consider, with strategies that select dissimilar examples from the same class or similar examples from different classes. The consensus of previous research is that optimizing with the \textit{hardest} negative examples leads to bad training behavior. That's a problem -- these hardest negatives are literally the cases where the distance metric fails to capture semantic similarity. In this paper, we characterize the space of triplets and derive why hard negatives make triplet loss training fail. We offer a simple fix to the loss function and show that, with this fix, optimizing with hard negative examples becomes feasible. This leads to more generalizable features, and image retrieval results that outperform state of the art for datasets with high intra-class variance.