 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOPDG: Popular 3D Dance Generation with PopDanceSet
May 06, 2024Generating dances that are both lifelike and well-aligned with music continues to be a challenging task in the cross-modal domain. This paper introduces PopDanceSet, the first dataset tailored to the preferences of young audiences, enabling the generation of aesthetically oriented dances. And it surpasses the AIST++ dataset in music genre diversity and the intricacy and depth of dance movements. Moreover, the proposed POPDG model within the iDDPM framework enhances dance diversity and, through the Space Augmentation Algorithm, strengthens spatial physical connections between human body joints, ensuring that increased diversity does not compromise generation quality. A streamlined Alignment Module is also designed to improve the temporal alignment between dance and music. Extensive experiments show that POPDG achieves SOTA results on two datasets. Furthermore, the paper also expands on current evaluation metrics. The dataset and code are available at https://github.com/Luke-Luo1/POPDG.
Disentangled Diffusion-Based 3D Human Pose Estimation with Hierarchical Spatial and Temporal Denoiser
Mar 07, 2024



Recently, diffusion-based methods for monocular 3D human pose estimation have achieved state-of-the-art (SOTA) performance by directly regressing the 3D joint coordinates from the 2D pose sequence. Although some methods decompose the task into bone length and bone direction prediction based on the human anatomical skeleton to explicitly incorporate more human body prior constraints, the performance of these methods is significantly lower than that of the SOTA diffusion-based methods. This can be attributed to the tree structure of the human skeleton. Direct application of the disentangled method could amplify the accumulation of hierarchical errors, propagating through each hierarchy. Meanwhile, the hierarchical information has not been fully explored by the previous methods. To address these problems, a Disentangled Diffusion-based 3D Human Pose Estimation method with Hierarchical Spatial and Temporal Denoiser is proposed, termed DDHPose. In our approach: (1) We disentangle the 3D pose and diffuse the bone length and bone direction during the forward process of the diffusion model to effectively model the human pose prior. A disentanglement loss is proposed to supervise diffusion model learning. (2) For the reverse process, we propose Hierarchical Spatial and Temporal Denoiser (HSTDenoiser) to improve the hierarchical modeling of each joint. Our HSTDenoiser comprises two components: the Hierarchical-Related Spatial Transformer (HRST) and the Hierarchical-Related Temporal Transformer (HRTT). HRST exploits joint spatial information and the influence of the parent joint on each joint for spatial modeling, while HRTT utilizes information from both the joint and its hierarchical adjacent joints to explore the hierarchical temporal correlations among joints.
Towards More Efficient Depression Risk Recognition via Gait
Oct 10, 2023



Depression, a highly prevalent mental illness, affects over 280 million individuals worldwide. Early detection and timely intervention are crucial for promoting remission, preventing relapse, and alleviating the emotional and financial burdens associated with depression. However, patients with depression often go undiagnosed in the primary care setting. Unlike many physiological illnesses, depression lacks objective indicators for recognizing depression risk, and existing methods for depression risk recognition are time-consuming and often encounter a shortage of trained medical professionals. The correlation between gait and depression risk has been empirically established. Gait can serve as a promising objective biomarker, offering the advantage of efficient and convenient data collection. However, current methods for recognizing depression risk based on gait have only been validated on small, private datasets, lacking large-scale publicly available datasets for research purposes. Additionally, these methods are primarily limited to hand-crafted approaches. Gait is a complex form of motion, and hand-crafted gait features often only capture a fraction of the intricate associations between gait and depression risk. Therefore, this study first constructs a large-scale gait database, encompassing over 1,200 individuals, 40,000 gait sequences, and covering six perspectives and three types of attire. Two commonly used psychological scales are provided as depression risk annotations. Subsequently, a deep learning-based depression risk recognition model is proposed, overcoming the limitations of hand-crafted approaches. Through experiments conducted on the constructed large-scale database, the effectiveness of the proposed method is validated, and numerous instructive insights are presented in the paper, highlighting the significant potential of gait-based depression risk recognition.
GPGait: Generalized Pose-based Gait Recognition
Mar 09, 2023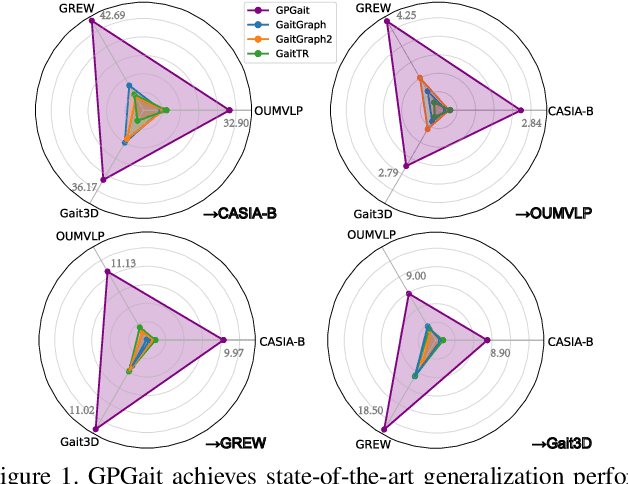
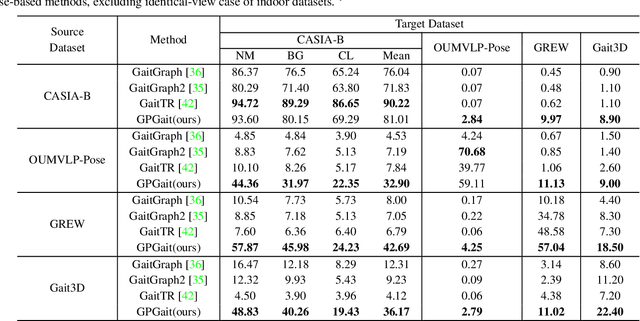


Recent works on pose-based gait recognition have demonstrated the potential of using such simple information to achieve results comparable to silhouette-based methods. However, the generalization ability of pose-based methods on different datasets is undesirably inferior to that of silhouette-based ones, which has received little attention but hinders the application of these methods in real-world scenarios. To improve the generalization ability of pose-based methods across datasets, we propose a Generalized Pose-based Gait recognition (GPGait) framework. First, a Human-Oriented Transformation (HOT) and a series of Human-Oriented Descriptors (HOD) are proposed to obtain a unified pose representation with discriminative multi-features. Then, given the slight variations in the unified representation after HOT and HOD, it becomes crucial for the network to extract local-global relationships between the keypoints. To this end, a Part-Aware Graph Convolutional Network (PAGCN) is proposed to enable efficient graph partition and local-global spatial feature extraction. Experiments on four public gait recognition datasets, CASIA-B, OUMVLP-Pose, Gait3D and GREW, show that our model demonstrates better and more stable cross-domain capabilities compared to existing skeleton-based methods, achieving comparable recognition results to silhouette-based ones. The code will be released.
Meta-SR: A Magnification-Arbitrary Network for Super-Resolution
Apr 03, 2019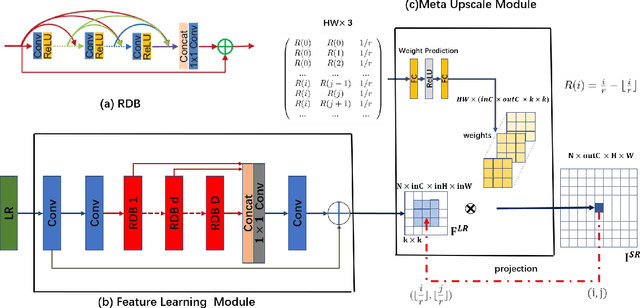
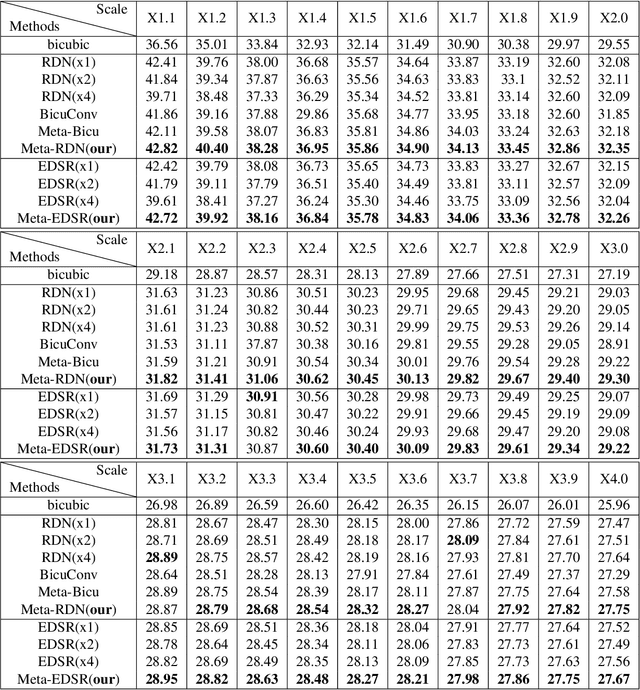
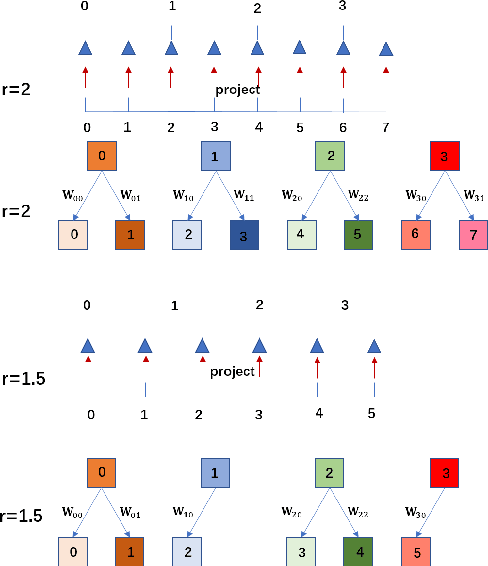
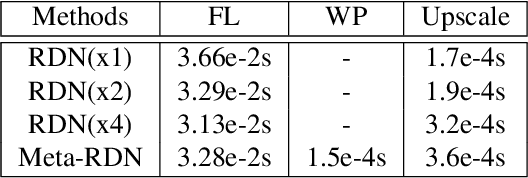
Recent research on super-resolution has achieved great success due to the development of deep convolutional neural networks (DCNNs). However, super-resolution of arbitrary scale factor has been ignored for a long time. Most previous researchers regard super-resolution of different scale factors as independent tasks. They train a specific model for each scale factor which is inefficient in computing, and prior work only take the super-resolution of several integer scale factors into consideration. In this work, we propose a novel method called Meta-SR to firstly solve super-resolution of arbitrary scale factor (including non-integer scale factors) with a single model. In our Meta-SR, the Meta-Upscale Module is proposed to replace the traditional upscale module. For arbitrary scale factor, the Meta-Upscale Module dynamically predicts the weights of the upscale filters by taking the scale factor as input and use these weights to generate the HR image of arbitrary size. For any low-resolution image, our Meta-SR can continuously zoom in it with arbitrary scale factor by only using a single model. We evaluated the proposed method through extensive experiments on widely used benchmark datasets on single image super-resolution. The experimental results show the superiority of our Meta-Upscale.