 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffinity Contrastive Learning for Skeleton-based Human Activity Understanding
Jan 23, 2026In skeleton-based human activity understanding, existing methods often adopt the contrastive learning paradigm to construct a discriminative feature space. However, many of these approaches fail to exploit the structural inter-class similarities and overlook the impact of anomalous positive samples. In this study, we introduce ACLNet, an Affinity Contrastive Learning Network that explores the intricate clustering relationships among human activity classes to improve feature discrimination. Specifically, we propose an affinity metric to refine similarity measurements, thereby forming activity superclasses that provide more informative contrastive signals. A dynamic temperature schedule is also introduced to adaptively adjust the penalty strength for various superclasses. In addition, we employ a margin-based contrastive strategy to improve the separation of hard positive and negative samples within classes. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, Kinetics-Skeleton, PKU-MMD, FineGYM, and CASIA-B demonstrate the superiority of our method in skeleton-based action recognition, gait recognition, and person re-identification. The source code is available at https://github.com/firework8/ACLNet.
* Accepted by TBIOM
Beyond Face Swapping: A Diffusion-Based Digital Human Benchmark for Multimodal Deepfake Detection
May 22, 2025In recent years, the rapid development of deepfake technology has given rise to an emerging and serious threat to public security: diffusion model-based digital human generation. Unlike traditional face manipulation methods, such models can generate highly realistic videos with consistency through multimodal control signals. Their flexibility and covertness pose severe challenges to existing detection strategies. To bridge this gap, we introduce DigiFakeAV, the first large-scale multimodal digital human forgery dataset based on diffusion models. Employing five latest digital human generation methods (Sonic, Hallo, etc.) and voice cloning method, we systematically produce a dataset comprising 60,000 videos (8.4 million frames), covering multiple nationalities, skin tones, genders, and real-world scenarios, significantly enhancing data diversity and realism. User studies show that the confusion rate between forged and real videos reaches 68%, and existing state-of-the-art (SOTA) detection models exhibit large drops in AUC values on DigiFakeAV, highlighting the challenge of the dataset. To address this problem, we further propose DigiShield, a detection baseline based on spatiotemporal and cross-modal fusion. By jointly modeling the 3D spatiotemporal features of videos and the semantic-acoustic features of audio, DigiShield achieves SOTA performance on both the DigiFakeAV and DF-TIMIT datasets. Experiments show that this method effectively identifies covert artifacts through fine-grained analysis of the temporal evolution of facial features in synthetic videos.
Revealing Key Details to See Differences: A Novel Prototypical Perspective for Skeleton-based Action Recognition
Nov 28, 2024In skeleton-based action recognition, a key challenge is distinguishing between actions with similar trajectories of joints due to the lack of image-level details in skeletal representations. Recognizing that the differentiation of similar actions relies on subtle motion details in specific body parts, we direct our approach to focus on the fine-grained motion of local skeleton components. To this end, we introduce ProtoGCN, a Graph Convolutional Network (GCN)-based model that breaks down the dynamics of entire skeleton sequences into a combination of learnable prototypes representing core motion patterns of action units. By contrasting the reconstruction of prototypes, ProtoGCN can effectively identify and enhance the discriminative representation of similar actions. Without bells and whistles, ProtoGCN achieves state-of-the-art performance on multiple benchmark datasets, including NTU RGB+D, NTU RGB+D 120, Kinetics-Skeleton, and FineGYM, which demonstrates the effectiveness of the proposed method. The code is available at https://github.com/firework8/ProtoGCN.
Artificial Immune System of Secure Face Recognition Against Adversarial Attacks
Jun 26, 2024Insect production for food and feed presents a promising supplement to ensure food safety and address the adverse impacts of agriculture on climate and environment in the future. However, optimisation is required for insect production to realise its full potential. This can be by targeted improvement of traits of interest through selective breeding, an approach which has so far been underexplored and underutilised in insect farming. Here we present a comprehensive review of the selective breeding framework in the context of insect production. We systematically evaluate adjustments of selective breeding techniques to the realm of insects and highlight the essential components integral to the breeding process. The discussion covers every step of a conventional breeding scheme, such as formulation of breeding objectives, phenotyping, estimation of genetic parameters and breeding values, selection of appropriate breeding strategies, and mitigation of issues associated with genetic diversity depletion and inbreeding. This review combines knowledge from diverse disciplines, bridging the gap between animal breeding, quantitative genetics, evolutionary biology, and entomology, offering an integrated view of the insect breeding research area and uniting knowledge which has previously remained scattered across diverse fields of expertise.
POPDG: Popular 3D Dance Generation with PopDanceSet
May 06, 2024Generating dances that are both lifelike and well-aligned with music continues to be a challenging task in the cross-modal domain. This paper introduces PopDanceSet, the first dataset tailored to the preferences of young audiences, enabling the generation of aesthetically oriented dances. And it surpasses the AIST++ dataset in music genre diversity and the intricacy and depth of dance movements. Moreover, the proposed POPDG model within the iDDPM framework enhances dance diversity and, through the Space Augmentation Algorithm, strengthens spatial physical connections between human body joints, ensuring that increased diversity does not compromise generation quality. A streamlined Alignment Module is also designed to improve the temporal alignment between dance and music. Extensive experiments show that POPDG achieves SOTA results on two datasets. Furthermore, the paper also expands on current evaluation metrics. The dataset and code are available at https://github.com/Luke-Luo1/POPDG.
Towards More Efficient Depression Risk Recognition via Gait
Oct 10, 2023



Depression, a highly prevalent mental illness, affects over 280 million individuals worldwide. Early detection and timely intervention are crucial for promoting remission, preventing relapse, and alleviating the emotional and financial burdens associated with depression. However, patients with depression often go undiagnosed in the primary care setting. Unlike many physiological illnesses, depression lacks objective indicators for recognizing depression risk, and existing methods for depression risk recognition are time-consuming and often encounter a shortage of trained medical professionals. The correlation between gait and depression risk has been empirically established. Gait can serve as a promising objective biomarker, offering the advantage of efficient and convenient data collection. However, current methods for recognizing depression risk based on gait have only been validated on small, private datasets, lacking large-scale publicly available datasets for research purposes. Additionally, these methods are primarily limited to hand-crafted approaches. Gait is a complex form of motion, and hand-crafted gait features often only capture a fraction of the intricate associations between gait and depression risk. Therefore, this study first constructs a large-scale gait database, encompassing over 1,200 individuals, 40,000 gait sequences, and covering six perspectives and three types of attire. Two commonly used psychological scales are provided as depression risk annotations. Subsequently, a deep learning-based depression risk recognition model is proposed, overcoming the limitations of hand-crafted approaches. Through experiments conducted on the constructed large-scale database, the effectiveness of the proposed method is validated, and numerous instructive insights are presented in the paper, highlighting the significant potential of gait-based depression risk recognition.
Balanced Representation Learning for Long-tailed Skeleton-based Action Recognition
Aug 27, 2023Skeleton-based action recognition has recently made significant progress. However, data imbalance is still a great challenge in real-world scenarios. The performance of current action recognition algorithms declines sharply when training data suffers from heavy class imbalance. The imbalanced data actually degrades the representations learned by these methods and becomes the bottleneck for action recognition. How to learn unbiased representations from imbalanced action data is the key to long-tailed action recognition. In this paper, we propose a novel balanced representation learning method to address the long-tailed problem in action recognition. Firstly, a spatial-temporal action exploration strategy is presented to expand the sample space effectively, generating more valuable samples in a rebalanced manner. Secondly, we design a detached action-aware learning schedule to further mitigate the bias in the representation space. The schedule detaches the representation learning of tail classes from training and proposes an action-aware loss to impose more effective constraints. Additionally, a skip-modal representation is proposed to provide complementary structural information. The proposed method is validated on four skeleton datasets, NTU RGB+D 60, NTU RGB+D 120, NW-UCLA, and Kinetics. It not only achieves consistently large improvement compared to the state-of-the-art (SOTA) methods, but also demonstrates a superior generalization capacity through extensive experiments. Our code is available at https://github.com/firework8/BRL.
Multiscale Dynamic Graph Representation for Biometric Recognition with Occlusions
Jul 27, 2023



Occlusion is a common problem with biometric recognition in the wild. The generalization ability of CNNs greatly decreases due to the adverse effects of various occlusions. To this end, we propose a novel unified framework integrating the merits of both CNNs and graph models to overcome occlusion problems in biometric recognition, called multiscale dynamic graph representation (MS-DGR). More specifically, a group of deep features reflected on certain subregions is recrafted into a feature graph (FG). Each node inside the FG is deemed to characterize a specific local region of the input sample, and the edges imply the co-occurrence of non-occluded regions. By analyzing the similarities of the node representations and measuring the topological structures stored in the adjacent matrix, the proposed framework leverages dynamic graph matching to judiciously discard the nodes corresponding to the occluded parts. The multiscale strategy is further incorporated to attain more diverse nodes representing regions of various sizes. Furthermore, the proposed framework exhibits a more illustrative and reasonable inference by showing the paired nodes. Extensive experiments demonstrate the superiority of the proposed framework, which boosts the accuracy in both natural and occlusion-simulated cases by a large margin compared with that of baseline methods.
Robust and Efficient Segmentation of Cross-domain Medical Images
Jul 26, 2022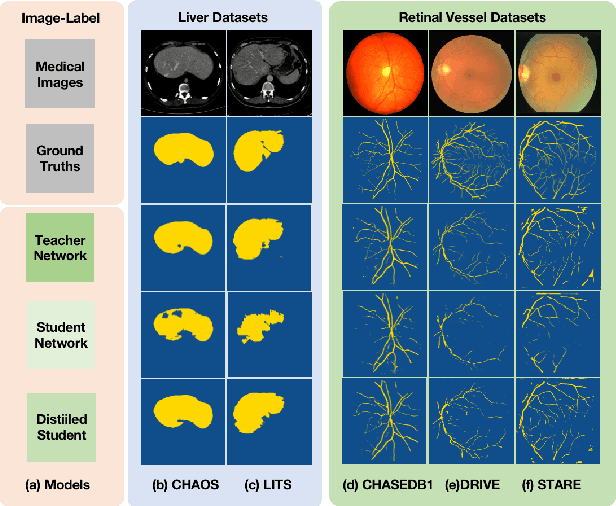
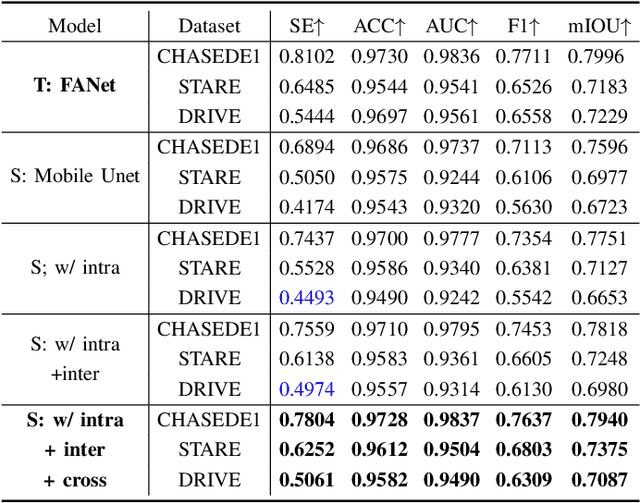
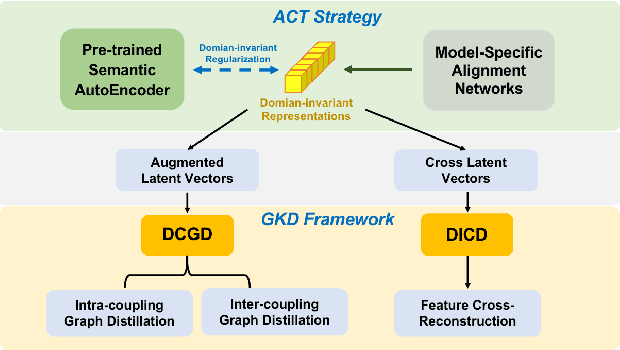
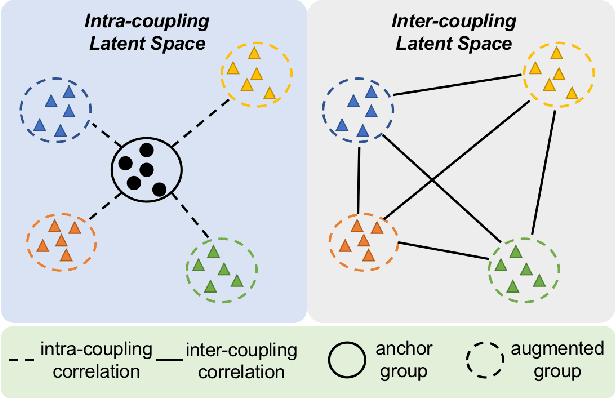
Efficient medical image segmentation aims to provide accurate pixel-wise prediction for the medical images with the lightweight implementation framework. However, lightweight frameworks generally fail to achieve high performance, and suffer from the poor generalizable ability on cross-domain tasks.In this paper, we propose a generalizable knowledge distillation method for robust and efficient segmentation of cross-domain medical images. Primarily, we propose the Model-Specific Alignment Networks (MSAN) to provide the domain-invariant representations which are regularized by a Pre-trained Semantic AutoEncoder (P-SAE). Meanwhile, a customized Alignment Consistency Training (ACT) strategy is designed to promote the MSAN training. With the domain-invariant representative vectors in MSAN, we propose two generalizable knowledge distillation schemes, Dual Contrastive Graph Distillation (DCGD) and Domain-Invariant Cross Distillation (DICD). Specifically, in DCGD, two types of implicit contrastive graphs are designed to represent the intra-coupling and inter-coupling semantic correlations from the perspective of data distribution. In DICD, the domain-invariant semantic vectors from the two models (i.e., teacher and student) are leveraged to cross-reconstruct features by the header exchange of MSAN, which achieves generalizable improvement for both the encoder and decoder in the student model. Furthermore, a metric named Fr\'echet Semantic Distance (FSD) is tailored to verify the effectiveness of the regularized domain-invariant features. Extensive experiments conducted on the Liver and Retinal Vessel Segmentation datasets demonstrate the priority of our method, in terms of performance and generalization on lightweight frameworks.
Perturbation Inactivation Based Adversarial Defense for Face Recognition
Jul 13, 2022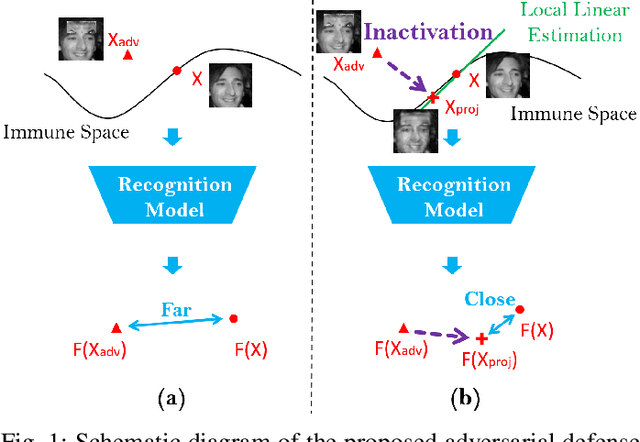
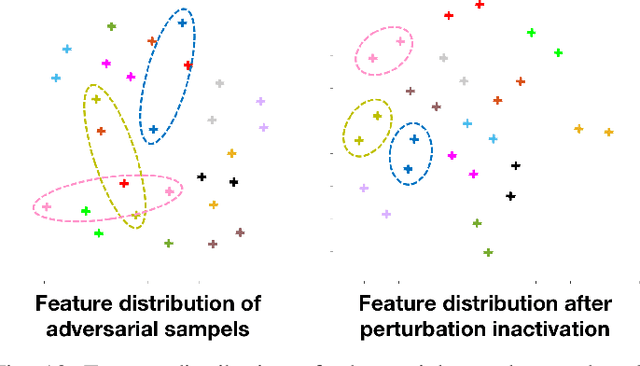

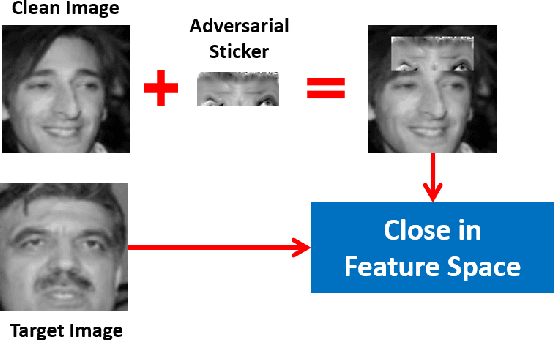
Deep learning-based face recognition models are vulnerable to adversarial attacks. To curb these attacks, most defense methods aim to improve the robustness of recognition models against adversarial perturbations. However, the generalization capacities of these methods are quite limited. In practice, they are still vulnerable to unseen adversarial attacks. Deep learning models are fairly robust to general perturbations, such as Gaussian noises. A straightforward approach is to inactivate the adversarial perturbations so that they can be easily handled as general perturbations. In this paper, a plug-and-play adversarial defense method, named perturbation inactivation (PIN), is proposed to inactivate adversarial perturbations for adversarial defense. We discover that the perturbations in different subspaces have different influences on the recognition model. There should be a subspace, called the immune space, in which the perturbations have fewer adverse impacts on the recognition model than in other subspaces. Hence, our method estimates the immune space and inactivates the adversarial perturbations by restricting them to this subspace. The proposed method can be generalized to unseen adversarial perturbations since it does not rely on a specific kind of adversarial attack method. This approach not only outperforms several state-of-the-art adversarial defense methods but also demonstrates a superior generalization capacity through exhaustive experiments. Moreover, the proposed method can be successfully applied to four commercial APIs without additional training, indicating that it can be easily generalized to existing face recognition systems. The source code is available at https://github.com/RenMin1991/Perturbation-Inactivate