 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAffinity Contrastive Learning for Skeleton-based Human Activity Understanding
Jan 23, 2026In skeleton-based human activity understanding, existing methods often adopt the contrastive learning paradigm to construct a discriminative feature space. However, many of these approaches fail to exploit the structural inter-class similarities and overlook the impact of anomalous positive samples. In this study, we introduce ACLNet, an Affinity Contrastive Learning Network that explores the intricate clustering relationships among human activity classes to improve feature discrimination. Specifically, we propose an affinity metric to refine similarity measurements, thereby forming activity superclasses that provide more informative contrastive signals. A dynamic temperature schedule is also introduced to adaptively adjust the penalty strength for various superclasses. In addition, we employ a margin-based contrastive strategy to improve the separation of hard positive and negative samples within classes. Extensive experiments on NTU RGB+D 60, NTU RGB+D 120, Kinetics-Skeleton, PKU-MMD, FineGYM, and CASIA-B demonstrate the superiority of our method in skeleton-based action recognition, gait recognition, and person re-identification. The source code is available at https://github.com/firework8/ACLNet.
* Accepted by TBIOM
Deploying Large AI Models on Resource-Limited Devices with Split Federated Learning
Apr 12, 2025Large Artificial Intelligence Models (LAMs) powered by massive datasets, extensive parameter scales, and extensive computational resources, leading to significant transformations across various industries. Yet, their practical deployment on resource-limited mobile edge devices is hindered by critical challenges such as data privacy, constrained resources, and high overhead costs. Addressing this gap, this paper proposes a novel framework, named Quantized Split Federated Fine-Tuning Large AI Model (SFLAM). By partitioning the training load between edge devices and servers using a split learning paradigm, SFLAM can facilitate the operation of large models on devices and significantly lowers the memory requirements on edge devices. Additionally, SFLAM incorporates quantization management, power control, and bandwidth allocation strategies to enhance training efficiency while concurrently reducing energy consumption and communication latency. A theoretical analysis exploring the latency-energy trade-off is presented, and the framework's efficacy is validated via comprehensive simulations. The findings indicate that SFLAM achieves superior performance in terms of learning efficiency and scalability compared to conventional methods, thereby providing a valuable approach for enabling advanced AI services in resource-constrained scenarios.
Pluggable Style Representation Learning for Multi-Style Transfer
Mar 26, 2025Due to the high diversity of image styles, the scalability to various styles plays a critical role in real-world applications. To accommodate a large amount of styles, previous multi-style transfer approaches rely on enlarging the model size while arbitrary-style transfer methods utilize heavy backbones. However, the additional computational cost introduced by more model parameters hinders these methods to be deployed on resource-limited devices. To address this challenge, in this paper, we develop a style transfer framework by decoupling the style modeling and transferring. Specifically, for style modeling, we propose a style representation learning scheme to encode the style information into a compact representation. Then, for style transferring, we develop a style-aware multi-style transfer network (SaMST) to adapt to diverse styles using pluggable style representations. In this way, our framework is able to accommodate diverse image styles in the learned style representations without introducing additional overhead during inference, thereby maintaining efficiency. Experiments show that our style representation can extract accurate style information. Moreover, qualitative and quantitative results demonstrate that our method achieves state-of-the-art performance in terms of both accuracy and efficiency. The codes are available in https://github.com/The-Learning-And-Vision-Atelier-LAVA/SaMST.
SaMam: Style-aware State Space Model for Arbitrary Image Style Transfer
Mar 20, 2025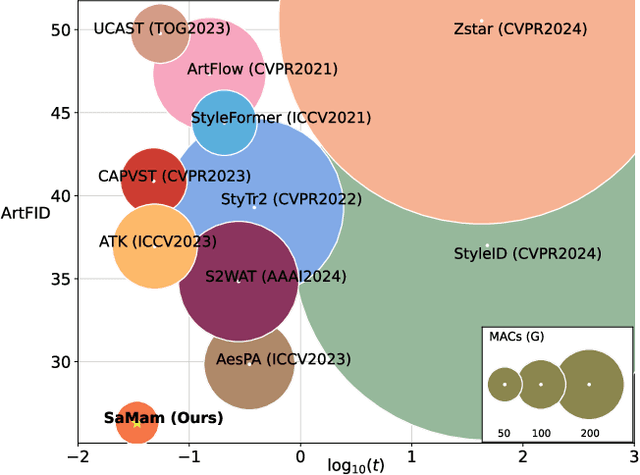

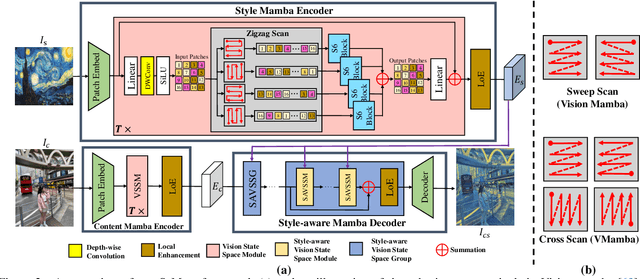

Global effective receptive field plays a crucial role for image style transfer (ST) to obtain high-quality stylized results. However, existing ST backbones (e.g., CNNs and Transformers) suffer huge computational complexity to achieve global receptive fields. Recently, the State Space Model (SSM), especially the improved variant Mamba, has shown great potential for long-range dependency modeling with linear complexity, which offers a approach to resolve the above dilemma. In this paper, we develop a Mamba-based style transfer framework, termed SaMam. Specifically, a mamba encoder is designed to efficiently extract content and style information. In addition, a style-aware mamba decoder is developed to flexibly adapt to various styles. Moreover, to address the problems of local pixel forgetting, channel redundancy and spatial discontinuity of existing SSMs, we introduce both local enhancement and zigzag scan. Qualitative and quantitative results demonstrate that our SaMam outperforms state-of-the-art methods in terms of both accuracy and efficiency.
Revealing Key Details to See Differences: A Novel Prototypical Perspective for Skeleton-based Action Recognition
Nov 28, 2024In skeleton-based action recognition, a key challenge is distinguishing between actions with similar trajectories of joints due to the lack of image-level details in skeletal representations. Recognizing that the differentiation of similar actions relies on subtle motion details in specific body parts, we direct our approach to focus on the fine-grained motion of local skeleton components. To this end, we introduce ProtoGCN, a Graph Convolutional Network (GCN)-based model that breaks down the dynamics of entire skeleton sequences into a combination of learnable prototypes representing core motion patterns of action units. By contrasting the reconstruction of prototypes, ProtoGCN can effectively identify and enhance the discriminative representation of similar actions. Without bells and whistles, ProtoGCN achieves state-of-the-art performance on multiple benchmark datasets, including NTU RGB+D, NTU RGB+D 120, Kinetics-Skeleton, and FineGYM, which demonstrates the effectiveness of the proposed method. The code is available at https://github.com/firework8/ProtoGCN.
NTIRE 2024 Challenge on Stereo Image Super-Resolution: Methods and Results
Sep 25, 2024



This paper summarizes the 3rd NTIRE challenge on stereo image super-resolution (SR) with a focus on new solutions and results. The task of this challenge is to super-resolve a low-resolution stereo image pair to a high-resolution one with a magnification factor of x4 under a limited computational budget. Compared with single image SR, the major challenge of this challenge lies in how to exploit additional information in another viewpoint and how to maintain stereo consistency in the results. This challenge has 2 tracks, including one track on bicubic degradation and one track on real degradations. In total, 108 and 70 participants were successfully registered for each track, respectively. In the test phase, 14 and 13 teams successfully submitted valid results with PSNR (RGB) scores better than the baseline. This challenge establishes a new benchmark for stereo image SR.
Preserving Full Degradation Details for Blind Image Super-Resolution
Jul 02, 2024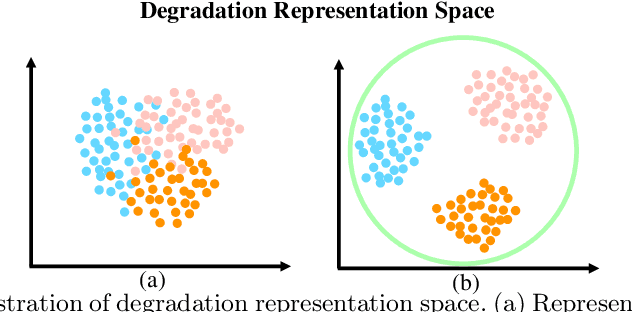
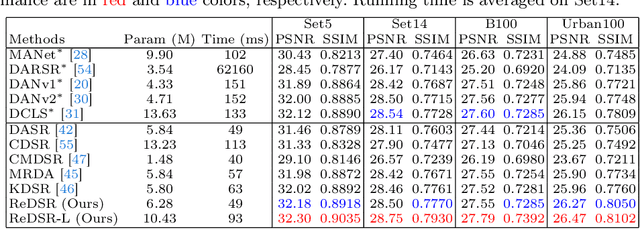
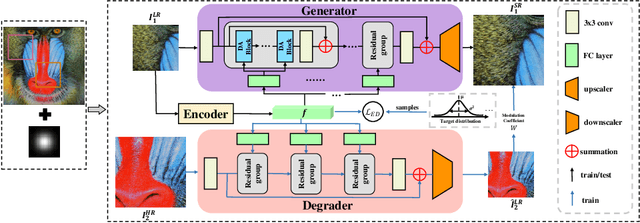
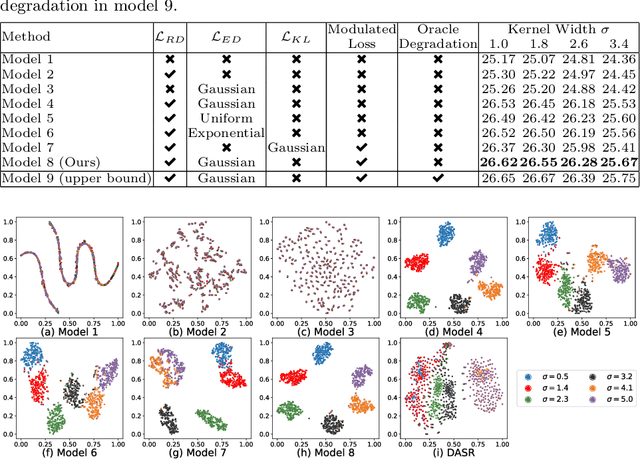
The performance of image super-resolution relies heavily on the accuracy of degradation information, especially under blind settings. Due to absence of true degradation models in real-world scenarios, previous methods learn distinct representations by distinguishing different degradations in a batch. However, the most significant degradation differences may provide shortcuts for the learning of representations such that subtle difference may be discarded. In this paper, we propose an alternative to learn degradation representations through reproducing degraded low-resolution (LR) images. By guiding the degrader to reconstruct input LR images, full degradation information can be encoded into the representations. In addition, we develop an energy distance loss to facilitate the learning of the degradation representations by introducing a bounded constraint. Experiments show that our representations can extract accurate and highly robust degradation information. Moreover, evaluations on both synthetic and real images demonstrate that our ReDSR achieves state-of-the-art performance for the blind SR tasks.
Balanced Representation Learning for Long-tailed Skeleton-based Action Recognition
Aug 27, 2023Skeleton-based action recognition has recently made significant progress. However, data imbalance is still a great challenge in real-world scenarios. The performance of current action recognition algorithms declines sharply when training data suffers from heavy class imbalance. The imbalanced data actually degrades the representations learned by these methods and becomes the bottleneck for action recognition. How to learn unbiased representations from imbalanced action data is the key to long-tailed action recognition. In this paper, we propose a novel balanced representation learning method to address the long-tailed problem in action recognition. Firstly, a spatial-temporal action exploration strategy is presented to expand the sample space effectively, generating more valuable samples in a rebalanced manner. Secondly, we design a detached action-aware learning schedule to further mitigate the bias in the representation space. The schedule detaches the representation learning of tail classes from training and proposes an action-aware loss to impose more effective constraints. Additionally, a skip-modal representation is proposed to provide complementary structural information. The proposed method is validated on four skeleton datasets, NTU RGB+D 60, NTU RGB+D 120, NW-UCLA, and Kinetics. It not only achieves consistently large improvement compared to the state-of-the-art (SOTA) methods, but also demonstrates a superior generalization capacity through extensive experiments. Our code is available at https://github.com/firework8/BRL.