 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaMam: Style-aware State Space Model for Arbitrary Image Style Transfer
Mar 20, 2025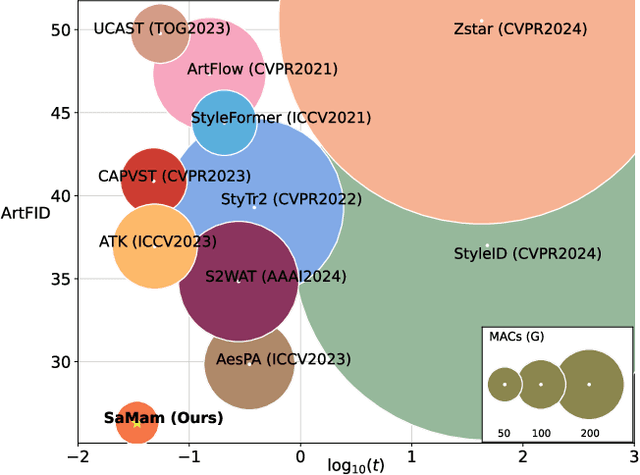

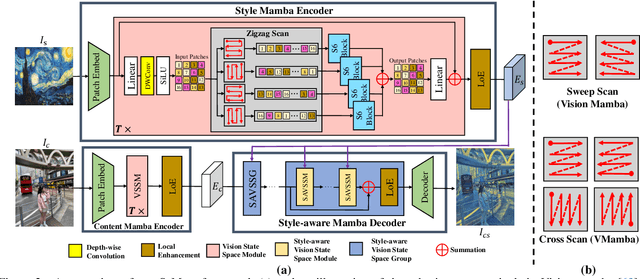

Global effective receptive field plays a crucial role for image style transfer (ST) to obtain high-quality stylized results. However, existing ST backbones (e.g., CNNs and Transformers) suffer huge computational complexity to achieve global receptive fields. Recently, the State Space Model (SSM), especially the improved variant Mamba, has shown great potential for long-range dependency modeling with linear complexity, which offers a approach to resolve the above dilemma. In this paper, we develop a Mamba-based style transfer framework, termed SaMam. Specifically, a mamba encoder is designed to efficiently extract content and style information. In addition, a style-aware mamba decoder is developed to flexibly adapt to various styles. Moreover, to address the problems of local pixel forgetting, channel redundancy and spatial discontinuity of existing SSMs, we introduce both local enhancement and zigzag scan. Qualitative and quantitative results demonstrate that our SaMam outperforms state-of-the-art methods in terms of both accuracy and efficiency.
A Quick, trustworthy spectral detection Q&A system based on the SDAAP Dataset and large language model
Aug 21, 2024



Large Language Model (LLM) has demonstrated significant success in a range of natural language processing (NLP) tasks within general domain. The emergence of LLM has introduced innovative methodologies across diverse fields, including the natural sciences. Researchers aim to implement automated, concurrent process driven by LLM to supplant conventional manual, repetitive and labor-intensive work. In the domain of spectral analysis and detection, it is imperative for researchers to autonomously acquire pertinent knowledge across various research objects, which encompasses the spectroscopic techniques and the chemometric methods that are employed in experiments and analysis. Paradoxically, despite the recognition of spectroscopic detection as an effective analytical method, the fundamental process of knowledge retrieval remains both time-intensive and repetitive. In response to this challenge, we first introduced the Spectral Detection and Analysis Based Paper(SDAAP) dataset, which is the first open-source textual knowledge dataset for spectral analysis and detection and contains annotated literature data as well as corresponding knowledge instruction data. Subsequently, we also designed an automated Q\&A framework based on the SDAAP dataset, which can retrieve relevant knowledge and generate high-quality responses by extracting entities in the input as retrieval parameters. It is worth noting that: within this framework, LLM is only used as a tool to provide generalizability, while RAG technique is used to accurately capture the source of the knowledge.This approach not only improves the quality of the generated responses, but also ensures the traceability of the knowledge. Experimental results show that our framework generates responses with more reliable expertise compared to the baseline.