 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeature-aligned Motion Transformation for Efficient Dynamic Point Cloud Compression
Sep 18, 2025Dynamic point clouds are widely used in applications such as immersive reality, robotics, and autonomous driving. Efficient compression largely depends on accurate motion estimation and compensation, yet the irregular structure and significant local variations of point clouds make this task highly challenging. Current methods often rely on explicit motion estimation, whose encoded vectors struggle to capture intricate dynamics and fail to fully exploit temporal correlations. To overcome these limitations, we introduce a Feature-aligned Motion Transformation (FMT) framework for dynamic point cloud compression. FMT replaces explicit motion vectors with a spatiotemporal alignment strategy that implicitly models continuous temporal variations, using aligned features as temporal context within a latent-space conditional encoding framework. Furthermore, we design a random access (RA) reference strategy that enables bidirectional motion referencing and layered encoding, thereby supporting frame-level parallel compression. Extensive experiments demonstrate that our method surpasses D-DPCC and AdaDPCC in both encoding and decoding efficiency, while also achieving BD-Rate reductions of 20% and 9.4%, respectively. These results highlight the effectiveness of FMT in jointly improving compression efficiency and processing performance.
Probing Deep into Temporal Profile Makes the Infrared Small Target Detector Much Better
Jun 15, 2025Infrared small target (IRST) detection is challenging in simultaneously achieving precise, universal, robust and efficient performance due to extremely dim targets and strong interference. Current learning-based methods attempt to leverage ``more" information from both the spatial and the short-term temporal domains, but suffer from unreliable performance under complex conditions while incurring computational redundancy. In this paper, we explore the ``more essential" information from a more crucial domain for the detection. Through theoretical analysis, we reveal that the global temporal saliency and correlation information in the temporal profile demonstrate significant superiority in distinguishing target signals from other signals. To investigate whether such superiority is preferentially leveraged by well-trained networks, we built the first prediction attribution tool in this field and verified the importance of the temporal profile information. Inspired by the above conclusions, we remodel the IRST detection task as a one-dimensional signal anomaly detection task, and propose an efficient deep temporal probe network (DeepPro) that only performs calculations in the time dimension for IRST detection. We conducted extensive experiments to fully validate the effectiveness of our method. The experimental results are exciting, as our DeepPro outperforms existing state-of-the-art IRST detection methods on widely-used benchmarks with extremely high efficiency, and achieves a significant improvement on dim targets and in complex scenarios. We provide a new modeling domain, a new insight, a new method, and a new performance, which can promote the development of IRST detection. Codes are available at https://github.com/TinaLRJ/DeepPro.
A Unified Hierarchical Framework for Fine-grained Cross-view Geo-localization over Large-scale Scenarios
May 12, 2025Cross-view geo-localization is a promising solution for large-scale localization problems, requiring the sequential execution of retrieval and metric localization tasks to achieve fine-grained predictions. However, existing methods typically focus on designing standalone models for these two tasks, resulting in inefficient collaboration and increased training overhead. In this paper, we propose UnifyGeo, a novel unified hierarchical geo-localization framework that integrates retrieval and metric localization tasks into a single network. Specifically, we first employ a unified learning strategy with shared parameters to jointly learn multi-granularity representation, facilitating mutual reinforcement between these two tasks. Subsequently, we design a re-ranking mechanism guided by a dedicated loss function, which enhances geo-localization performance by improving both retrieval accuracy and metric localization references. Extensive experiments demonstrate that UnifyGeo significantly outperforms the state-of-the-arts in both task-isolated and task-associated settings. Remarkably, on the challenging VIGOR benchmark, which supports fine-grained localization evaluation, the 1-meter-level localization recall rate improves from 1.53\% to 39.64\% and from 0.43\% to 25.58\% under same-area and cross-area evaluations, respectively. Code will be made publicly available.
DropoutGS: Dropping Out Gaussians for Better Sparse-view Rendering
Apr 13, 2025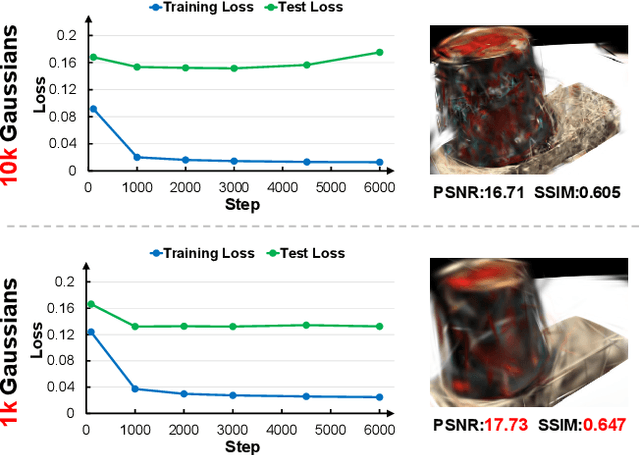
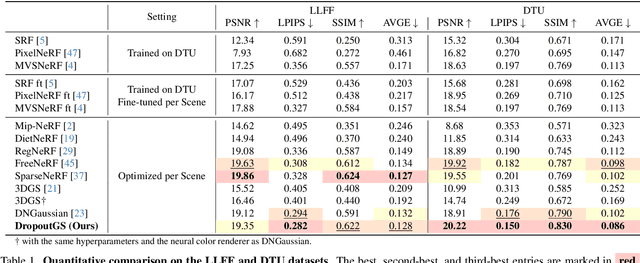

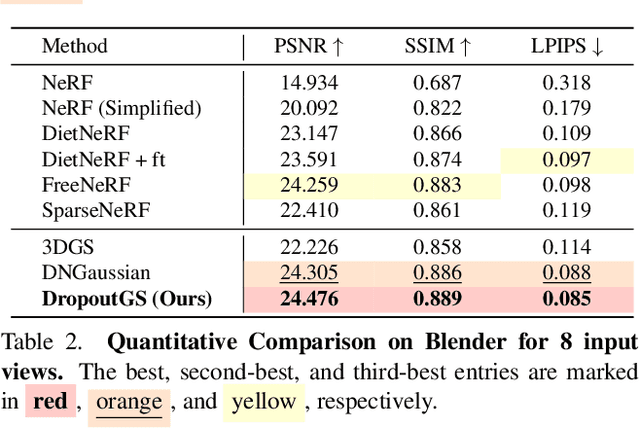
Although 3D Gaussian Splatting (3DGS) has demonstrated promising results in novel view synthesis, its performance degrades dramatically with sparse inputs and generates undesirable artifacts. As the number of training views decreases, the novel view synthesis task degrades to a highly under-determined problem such that existing methods suffer from the notorious overfitting issue. Interestingly, we observe that models with fewer Gaussian primitives exhibit less overfitting under sparse inputs. Inspired by this observation, we propose a Random Dropout Regularization (RDR) to exploit the advantages of low-complexity models to alleviate overfitting. In addition, to remedy the lack of high-frequency details for these models, an Edge-guided Splitting Strategy (ESS) is developed. With these two techniques, our method (termed DropoutGS) provides a simple yet effective plug-in approach to improve the generalization performance of existing 3DGS methods. Extensive experiments show that our DropoutGS produces state-of-the-art performance under sparse views on benchmark datasets including Blender, LLFF, and DTU. The project page is at: https://xuyx55.github.io/DropoutGS/.
Pluggable Style Representation Learning for Multi-Style Transfer
Mar 26, 2025Due to the high diversity of image styles, the scalability to various styles plays a critical role in real-world applications. To accommodate a large amount of styles, previous multi-style transfer approaches rely on enlarging the model size while arbitrary-style transfer methods utilize heavy backbones. However, the additional computational cost introduced by more model parameters hinders these methods to be deployed on resource-limited devices. To address this challenge, in this paper, we develop a style transfer framework by decoupling the style modeling and transferring. Specifically, for style modeling, we propose a style representation learning scheme to encode the style information into a compact representation. Then, for style transferring, we develop a style-aware multi-style transfer network (SaMST) to adapt to diverse styles using pluggable style representations. In this way, our framework is able to accommodate diverse image styles in the learned style representations without introducing additional overhead during inference, thereby maintaining efficiency. Experiments show that our style representation can extract accurate style information. Moreover, qualitative and quantitative results demonstrate that our method achieves state-of-the-art performance in terms of both accuracy and efficiency. The codes are available in https://github.com/The-Learning-And-Vision-Atelier-LAVA/SaMST.
SaMam: Style-aware State Space Model for Arbitrary Image Style Transfer
Mar 20, 2025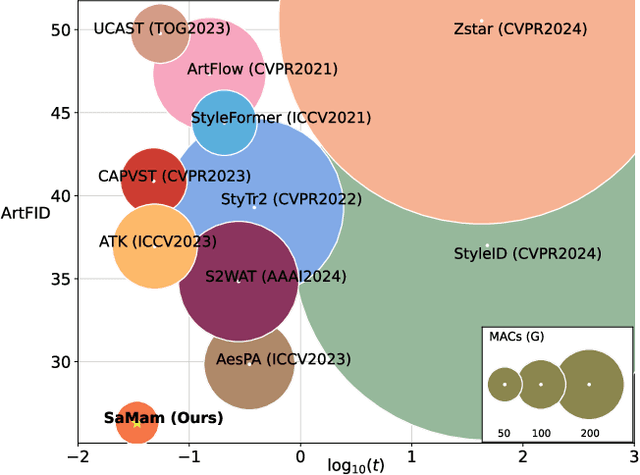

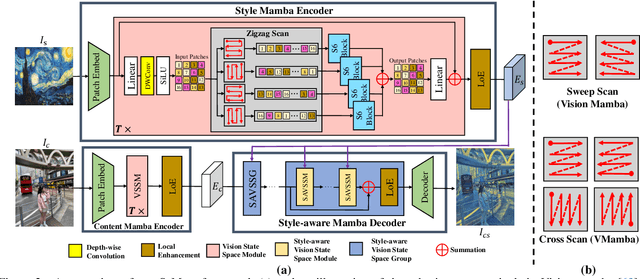

Global effective receptive field plays a crucial role for image style transfer (ST) to obtain high-quality stylized results. However, existing ST backbones (e.g., CNNs and Transformers) suffer huge computational complexity to achieve global receptive fields. Recently, the State Space Model (SSM), especially the improved variant Mamba, has shown great potential for long-range dependency modeling with linear complexity, which offers a approach to resolve the above dilemma. In this paper, we develop a Mamba-based style transfer framework, termed SaMam. Specifically, a mamba encoder is designed to efficiently extract content and style information. In addition, a style-aware mamba decoder is developed to flexibly adapt to various styles. Moreover, to address the problems of local pixel forgetting, channel redundancy and spatial discontinuity of existing SSMs, we introduce both local enhancement and zigzag scan. Qualitative and quantitative results demonstrate that our SaMam outperforms state-of-the-art methods in terms of both accuracy and efficiency.
Simulating the Real World: A Unified Survey of Multimodal Generative Models
Mar 06, 2025



Understanding and replicating the real world is a critical challenge in Artificial General Intelligence (AGI) research. To achieve this, many existing approaches, such as world models, aim to capture the fundamental principles governing the physical world, enabling more accurate simulations and meaningful interactions. However, current methods often treat different modalities, including 2D (images), videos, 3D, and 4D representations, as independent domains, overlooking their interdependencies. Additionally, these methods typically focus on isolated dimensions of reality without systematically integrating their connections. In this survey, we present a unified survey for multimodal generative models that investigate the progression of data dimensionality in real-world simulation. Specifically, this survey starts from 2D generation (appearance), then moves to video (appearance+dynamics) and 3D generation (appearance+geometry), and finally culminates in 4D generation that integrate all dimensions. To the best of our knowledge, this is the first attempt to systematically unify the study of 2D, video, 3D and 4D generation within a single framework. To guide future research, we provide a comprehensive review of datasets, evaluation metrics and future directions, and fostering insights for newcomers. This survey serves as a bridge to advance the study of multimodal generative models and real-world simulation within a unified framework.
AIQViT: Architecture-Informed Post-Training Quantization for Vision Transformers
Feb 07, 2025Post-training quantization (PTQ) has emerged as a promising solution for reducing the storage and computational cost of vision transformers (ViTs). Recent advances primarily target at crafting quantizers to deal with peculiar activations characterized by ViTs. However, most existing methods underestimate the information loss incurred by weight quantization, resulting in significant performance deterioration, particularly in low-bit cases. Furthermore, a common practice in quantizing post-Softmax activations of ViTs is to employ logarithmic transformations, which unfortunately prioritize less informative values around zero. This approach introduces additional redundancies, ultimately leading to suboptimal quantization efficacy. To handle these, this paper proposes an innovative PTQ method tailored for ViTs, termed AIQViT (Architecture-Informed Post-training Quantization for ViTs). First, we design an architecture-informed low rank compensation mechanism, wherein learnable low-rank weights are introduced to compensate for the degradation caused by weight quantization. Second, we design a dynamic focusing quantizer to accommodate the unbalanced distribution of post-Softmax activations, which dynamically selects the most valuable interval for higher quantization resolution. Extensive experiments on five vision tasks, including image classification, object detection, instance segmentation, point cloud classification, and point cloud part segmentation, demonstrate the superiority of AIQViT over state-of-the-art PTQ methods.
Layout2Scene: 3D Semantic Layout Guided Scene Generation via Geometry and Appearance Diffusion Priors
Jan 05, 20253D scene generation conditioned on text prompts has significantly progressed due to the development of 2D diffusion generation models. However, the textual description of 3D scenes is inherently inaccurate and lacks fine-grained control during training, leading to implausible scene generation. As an intuitive and feasible solution, the 3D layout allows for precise specification of object locations within the scene. To this end, we present a text-to-scene generation method (namely, Layout2Scene) using additional semantic layout as the prompt to inject precise control of 3D object positions. Specifically, we first introduce a scene hybrid representation to decouple objects and backgrounds, which is initialized via a pre-trained text-to-3D model. Then, we propose a two-stage scheme to optimize the geometry and appearance of the initialized scene separately. To fully leverage 2D diffusion priors in geometry and appearance generation, we introduce a semantic-guided geometry diffusion model and a semantic-geometry guided diffusion model which are finetuned on a scene dataset. Extensive experiments demonstrate that our method can generate more plausible and realistic scenes as compared to state-of-the-art approaches. Furthermore, the generated scene allows for flexible yet precise editing, thereby facilitating multiple downstream applications.
Heterogeneous Graph Transformer for Multiple Tiny Object Tracking in RGB-T Videos
Dec 14, 2024



Tracking multiple tiny objects is highly challenging due to their weak appearance and limited features. Existing multi-object tracking algorithms generally focus on single-modality scenes, and overlook the complementary characteristics of tiny objects captured by multiple remote sensors. To enhance tracking performance by integrating complementary information from multiple sources, we propose a novel framework called {HGT-Track (Heterogeneous Graph Transformer based Multi-Tiny-Object Tracking)}. Specifically, we first employ a Transformer-based encoder to embed images from different modalities. Subsequently, we utilize Heterogeneous Graph Transformer to aggregate spatial and temporal information from multiple modalities to generate detection and tracking features. Additionally, we introduce a target re-detection module (ReDet) to ensure tracklet continuity by maintaining consistency across different modalities. Furthermore, this paper introduces the first benchmark VT-Tiny-MOT (Visible-Thermal Tiny Multi-Object Tracking) for RGB-T fused multiple tiny object tracking. Extensive experiments are conducted on VT-Tiny-MOT, and the results have demonstrated the effectiveness of our method. Compared to other state-of-the-art methods, our method achieves better performance in terms of MOTA (Multiple-Object Tracking Accuracy) and ID-F1 score. The code and dataset will be made available at https://github.com/xuqingyu26/HGTMT.