 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoadGIE: Towards A Global-Scale Aerial Benchmark for Generalizable Interactive Road Extraction
May 26, 2026Accurate road segmentation from aerial imagery is fundamental to many geospatial applications. However, existing datasets often suffer from limited scene diversity, low semantic granularity, and poor structural continuity, restricting their generalization across environments. To address these challenges, we introduce WorldRoadSeg-360K, the largest and most diverse road segmentation dataset to date, comprising 366,947 high-resolution images collected from 38 countries and 223 cities across various terrains and continents. WorldRoadSeg-360K serves as a comprehensive benchmark and reveals key challenges in handling diverse and structurally complex scenes. Automated approaches often struggle to preserve road connectivity, while current interactive methods lack efficient, topology-sensitive tools for real-world road editing. To this end, we present RoadGIE, establishing a novel interactive paradigm for road extraction in remote sensing. Unlike prior point- or box-based prompting strategies, RoadGIE supports connectivity-aware prompts, including clicks and scribbles, which inherently align with the topology of road networks. To improve structural consistency and mitigate performance degradation during iterative interactions, RoadGIE integrates an expert-guided prompting strategy and adapts the skeleton-based recall loss for interactive scenarios. RoadGIE achieves state-of-the-art performance in both segmentation accuracy and topological consistency on WorldRoadSeg-360K and other benchmarks, while maintaining efficient operation with only 3.7M parameters. The code are publicly available at: https://github.com/chaineypung/RoadGIE
NS-FPN: Improving Infrared Small Target Detection and Segmentation from Noise Suppression Perspective
Aug 09, 2025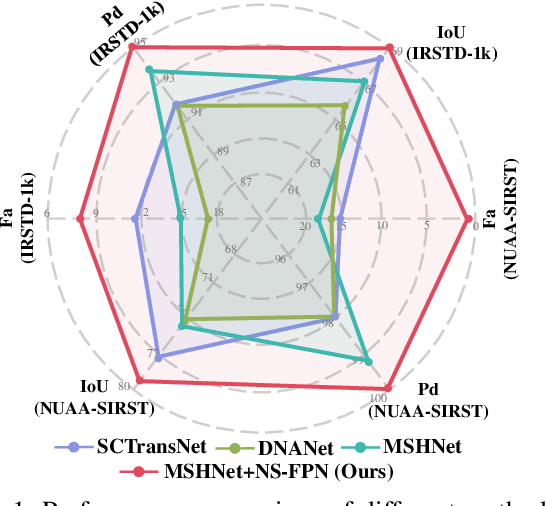

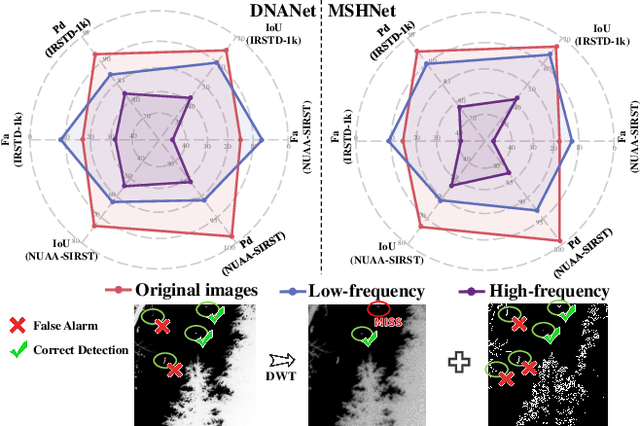
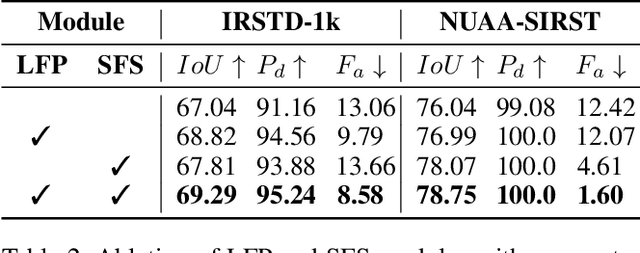
Infrared small target detection and segmentation (IRSTDS) is a critical yet challenging task in defense and civilian applications, owing to the dim, shapeless appearance of targets and severe background clutter. Recent CNN-based methods have achieved promising target perception results, but they only focus on enhancing feature representation to offset the impact of noise, which results in the increased false alarms problem. In this paper, through analyzing the problem from the frequency domain, we pioneer in improving performance from noise suppression perspective and propose a novel noise-suppression feature pyramid network (NS-FPN), which integrates a low-frequency guided feature purification (LFP) module and a spiral-aware feature sampling (SFS) module into the original FPN structure. The LFP module suppresses the noise features by purifying high-frequency components to achieve feature enhancement devoid of noise interference, while the SFS module further adopts spiral sampling to fuse target-relevant features in feature fusion process. Our NS-FPN is designed to be lightweight yet effective and can be easily plugged into existing IRSTDS frameworks. Extensive experiments on the public IRSTDS datasets demonstrate that our method significantly reduces false alarms and achieves superior performance on IRSTDS tasks.
RPCANet++: Deep Interpretable Robust PCA for Sparse Object Segmentation
Aug 06, 2025
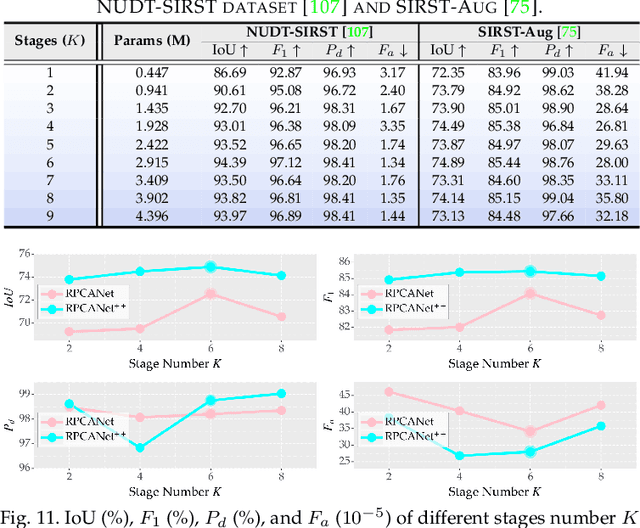

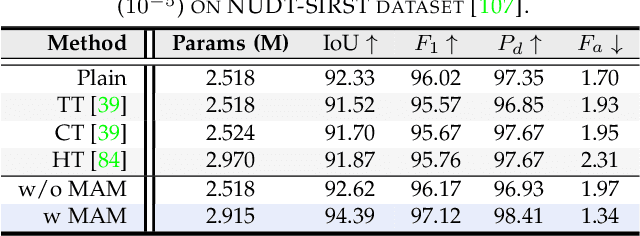
Robust principal component analysis (RPCA) decomposes an observation matrix into low-rank background and sparse object components. This capability has enabled its application in tasks ranging from image restoration to segmentation. However, traditional RPCA models suffer from computational burdens caused by matrix operations, reliance on finely tuned hyperparameters, and rigid priors that limit adaptability in dynamic scenarios. To solve these limitations, we propose RPCANet++, a sparse object segmentation framework that fuses the interpretability of RPCA with efficient deep architectures. Our approach unfolds a relaxed RPCA model into a structured network comprising a Background Approximation Module (BAM), an Object Extraction Module (OEM), and an Image Restoration Module (IRM). To mitigate inter-stage transmission loss in the BAM, we introduce a Memory-Augmented Module (MAM) to enhance background feature preservation, while a Deep Contrast Prior Module (DCPM) leverages saliency cues to expedite object extraction. Extensive experiments on diverse datasets demonstrate that RPCANet++ achieves state-of-the-art performance under various imaging scenarios. We further improve interpretability via visual and numerical low-rankness and sparsity measurements. By combining the theoretical strengths of RPCA with the efficiency of deep networks, our approach sets a new baseline for reliable and interpretable sparse object segmentation. Codes are available at our Project Webpage https://fengyiwu98.github.io/rpcanetx.
Probing Deep into Temporal Profile Makes the Infrared Small Target Detector Much Better
Jun 15, 2025Infrared small target (IRST) detection is challenging in simultaneously achieving precise, universal, robust and efficient performance due to extremely dim targets and strong interference. Current learning-based methods attempt to leverage ``more" information from both the spatial and the short-term temporal domains, but suffer from unreliable performance under complex conditions while incurring computational redundancy. In this paper, we explore the ``more essential" information from a more crucial domain for the detection. Through theoretical analysis, we reveal that the global temporal saliency and correlation information in the temporal profile demonstrate significant superiority in distinguishing target signals from other signals. To investigate whether such superiority is preferentially leveraged by well-trained networks, we built the first prediction attribution tool in this field and verified the importance of the temporal profile information. Inspired by the above conclusions, we remodel the IRST detection task as a one-dimensional signal anomaly detection task, and propose an efficient deep temporal probe network (DeepPro) that only performs calculations in the time dimension for IRST detection. We conducted extensive experiments to fully validate the effectiveness of our method. The experimental results are exciting, as our DeepPro outperforms existing state-of-the-art IRST detection methods on widely-used benchmarks with extremely high efficiency, and achieves a significant improvement on dim targets and in complex scenarios. We provide a new modeling domain, a new insight, a new method, and a new performance, which can promote the development of IRST detection. Codes are available at https://github.com/TinaLRJ/DeepPro.
DISTA-Net: Dynamic Closely-Spaced Infrared Small Target Unmixing
May 25, 2025Resolving closely-spaced small targets in dense clusters presents a significant challenge in infrared imaging, as the overlapping signals hinder precise determination of their quantity, sub-pixel positions, and radiation intensities. While deep learning has advanced the field of infrared small target detection, its application to closely-spaced infrared small targets has not yet been explored. This gap exists primarily due to the complexity of separating superimposed characteristics and the lack of an open-source infrastructure. In this work, we propose the Dynamic Iterative Shrinkage Thresholding Network (DISTA-Net), which reconceptualizes traditional sparse reconstruction within a dynamic framework. DISTA-Net adaptively generates convolution weights and thresholding parameters to tailor the reconstruction process in real time. To the best of our knowledge, DISTA-Net is the first deep learning model designed specifically for the unmixing of closely-spaced infrared small targets, achieving superior sub-pixel detection accuracy. Moreover, we have established the first open-source ecosystem to foster further research in this field. This ecosystem comprises three key components: (1) CSIST-100K, a publicly available benchmark dataset; (2) CSO-mAP, a custom evaluation metric for sub-pixel detection; and (3) GrokCSO, an open-source toolkit featuring DISTA-Net and other models. Our code and dataset are available at https://github.com/GrokCV/GrokCSO.
AuxDet: Auxiliary Metadata Matters for Omni-Domain Infrared Small Target Detection
May 21, 2025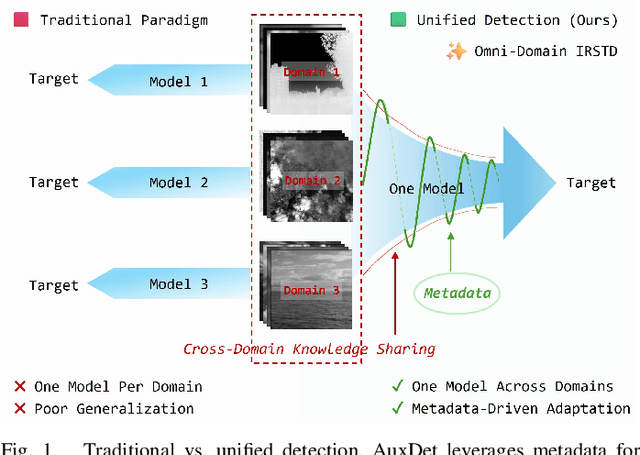
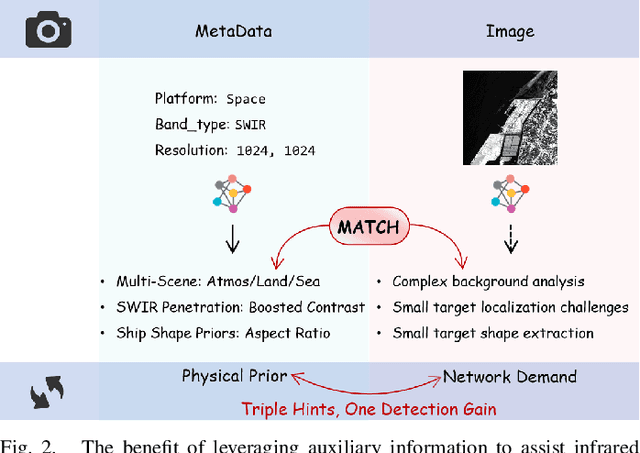
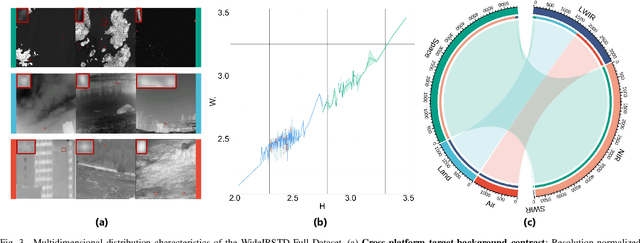
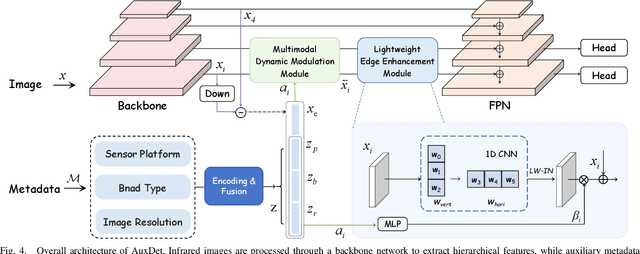
Omni-domain infrared small target detection (IRSTD) poses formidable challenges, as a single model must seamlessly adapt to diverse imaging systems, varying resolutions, and multiple spectral bands simultaneously. Current approaches predominantly rely on visual-only modeling paradigms that not only struggle with complex background interference and inherently scarce target features, but also exhibit limited generalization capabilities across complex omni-scene environments where significant domain shifts and appearance variations occur. In this work, we reveal a critical oversight in existing paradigms: the neglect of readily available auxiliary metadata describing imaging parameters and acquisition conditions, such as spectral bands, sensor platforms, resolution, and observation perspectives. To address this limitation, we propose the Auxiliary Metadata Driven Infrared Small Target Detector (AuxDet), a novel multi-modal framework that fundamentally reimagines the IRSTD paradigm by incorporating textual metadata for scene-aware optimization. Through a high-dimensional fusion module based on multi-layer perceptrons (MLPs), AuxDet dynamically integrates metadata semantics with visual features, guiding adaptive representation learning for each individual sample. Additionally, we design a lightweight prior-initialized enhancement module using 1D convolutional blocks to further refine fused features and recover fine-grained target cues. Extensive experiments on the challenging WideIRSTD-Full benchmark demonstrate that AuxDet consistently outperforms state-of-the-art methods, validating the critical role of auxiliary information in improving robustness and accuracy in omni-domain IRSTD tasks. Code is available at https://github.com/GrokCV/AuxDet.
A Simple Detector with Frame Dynamics is a Strong Tracker
May 08, 2025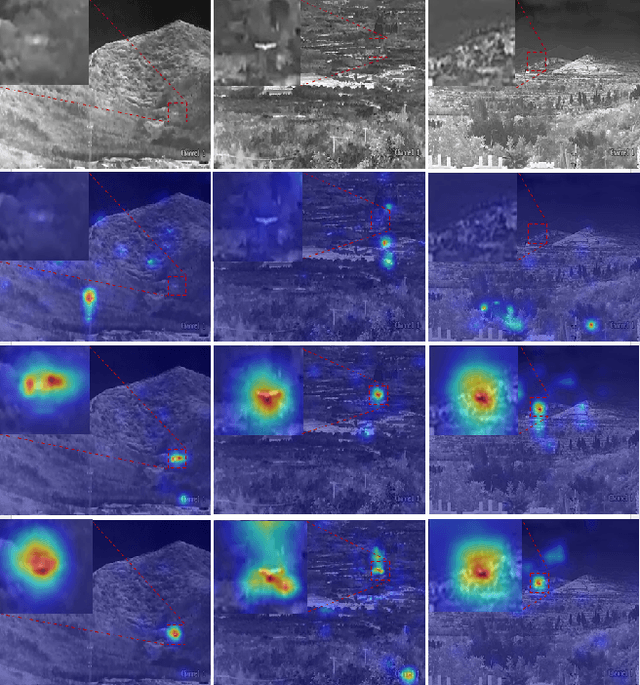
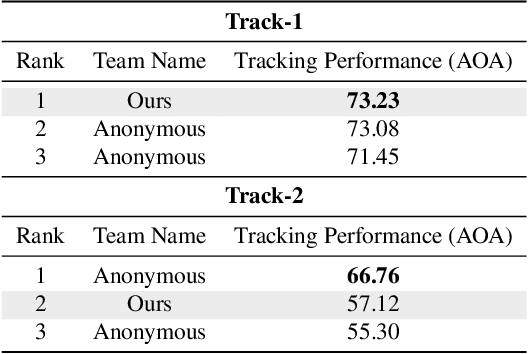
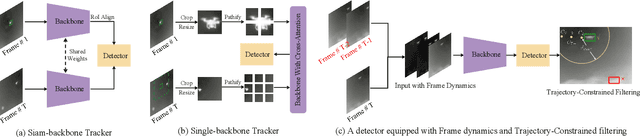
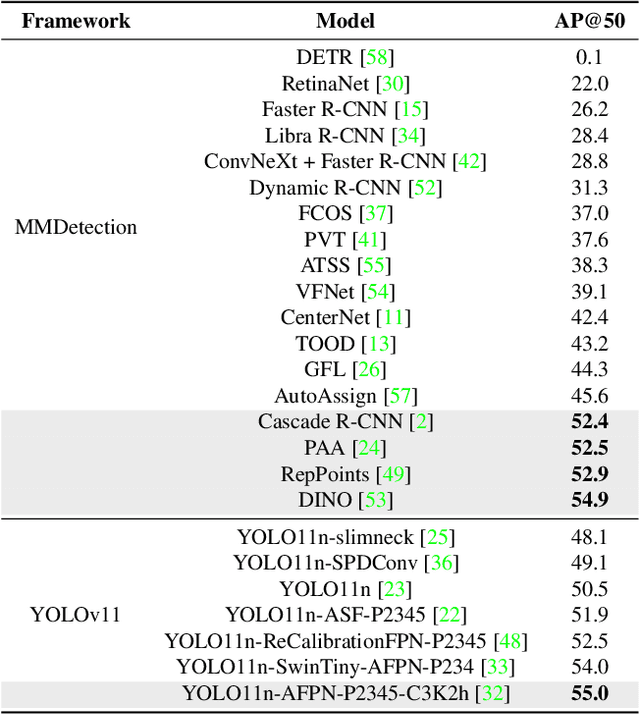
Infrared object tracking plays a crucial role in Anti-Unmanned Aerial Vehicle (Anti-UAV) applications. Existing trackers often depend on cropped template regions and have limited motion modeling capabilities, which pose challenges when dealing with tiny targets. To address this, we propose a simple yet effective infrared tiny-object tracker that enhances tracking performance by integrating global detection and motion-aware learning with temporal priors. Our method is based on object detection and achieves significant improvements through two key innovations. First, we introduce frame dynamics, leveraging frame difference and optical flow to encode both prior target features and motion characteristics at the input level, enabling the model to better distinguish the target from background clutter. Second, we propose a trajectory constraint filtering strategy in the post-processing stage, utilizing spatio-temporal priors to suppress false positives and enhance tracking robustness. Extensive experiments show that our method consistently outperforms existing approaches across multiple metrics in challenging infrared UAV tracking scenarios. Notably, we achieve state-of-the-art performance in the 4th Anti-UAV Challenge, securing 1st place in Track 1 and 2nd place in Track 2.
SM3Det: A Unified Model for Multi-Modal Remote Sensing Object Detection
Dec 30, 2024With the rapid advancement of remote sensing technology, high-resolution multi-modal imagery is now more widely accessible. Conventional Object detection models are trained on a single dataset, often restricted to a specific imaging modality and annotation format. However, such an approach overlooks the valuable shared knowledge across multi-modalities and limits the model's applicability in more versatile scenarios. This paper introduces a new task called Multi-Modal Datasets and Multi-Task Object Detection (M2Det) for remote sensing, designed to accurately detect horizontal or oriented objects from any sensor modality. This task poses challenges due to 1) the trade-offs involved in managing multi-modal modelling and 2) the complexities of multi-task optimization. To address these, we establish a benchmark dataset and propose a unified model, SM3Det (Single Model for Multi-Modal datasets and Multi-Task object Detection). SM3Det leverages a grid-level sparse MoE backbone to enable joint knowledge learning while preserving distinct feature representations for different modalities. Furthermore, it integrates a consistency and synchronization optimization strategy using dynamic learning rate adjustment, allowing it to effectively handle varying levels of learning difficulty across modalities and tasks. Extensive experiments demonstrate SM3Det's effectiveness and generalizability, consistently outperforming specialized models on individual datasets. The code is available at https://github.com/zcablii/SM3Det.
GrokLST: Towards High-Resolution Benchmark and Toolkit for Land Surface Temperature Downscaling
Sep 30, 2024



Land Surface Temperature (LST) is a critical parameter for environmental studies, but obtaining high-resolution LST data remains challenging due to the spatio-temporal trade-off in satellite remote sensing. Guided LST downscaling has emerged as a solution, but current methods often neglect spatial non-stationarity and lack a open-source ecosystem for deep learning methods. To address these limitations, we propose the Modality-Conditional Large Selective Kernel (MoCoLSK) Networks, a novel architecture that dynamically fuses multi-modal data through modality-conditioned projections. MoCoLSK re-engineers our previous LSKNet to achieve a confluence of dynamic receptive field adjustment and multi-modal feature integration, leading to enhanced LST prediction accuracy. Furthermore, we establish the GrokLST project, a comprehensive open-source ecosystem featuring the GrokLST dataset, a high-resolution benchmark, and the GrokLST toolkit, an open-source PyTorch-based toolkit encapsulating MoCoLSK alongside 40+ state-of-the-art approaches. Extensive experimental results validate MoCoLSK's effectiveness in capturing complex dependencies and subtle variations within multispectral data, outperforming existing methods in LST downscaling. Our code, dataset, and toolkit are available at https://github.com/GrokCV/GrokLST.
HazyDet: Open-source Benchmark for Drone-view Object Detection with Depth-cues in Hazy Scenes
Sep 30, 2024



Drone-based object detection in adverse weather conditions is crucial for enhancing drones' environmental perception, yet it remains largely unexplored due to the lack of relevant benchmarks. To bridge this gap, we introduce HazyDet, a large-scale dataset tailored for drone-based object detection in hazy scenes. It encompasses 383,000 real-world instances, collected from both naturally hazy environments and normal scenes with synthetically imposed haze effects to simulate adverse weather conditions. By observing the significant variations in object scale and clarity under different depth and haze conditions, we designed a Depth Conditioned Detector (DeCoDet) to incorporate this prior knowledge. DeCoDet features a Multi-scale Depth-aware Detection Head that seamlessly integrates depth perception, with the resulting depth cues harnessed by a dynamic Depth Condition Kernel module. Furthermore, we propose a Scale Invariant Refurbishment Loss to facilitate the learning of robust depth cues from pseudo-labels. Extensive evaluations on the HazyDet dataset demonstrate the flexibility and effectiveness of our method, yielding significant performance improvements. Our dataset and toolkit are available at https://github.com/GrokCV/HazyDet.