 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenGuanDan: A Large-Scale Imperfect Information Game Benchmark
Jan 31, 2026The advancement of data-driven artificial intelligence (AI), particularly machine learning, heavily depends on large-scale benchmarks. Despite remarkable progress across domains ranging from pattern recognition to intelligent decision-making in recent decades, exemplified by breakthroughs in board games, card games, and electronic sports games, there remains a pressing need for more challenging benchmarks to drive further research. To this end, this paper proposes OpenGuanDan, a novel benchmark that enables both efficient simulation of GuanDan (a popular four-player, multi-round Chinese card game) and comprehensive evaluation of both learning-based and rule-based GuanDan AI agents. OpenGuanDan poses a suite of nontrivial challenges, including imperfect information, large-scale information set and action spaces, a mixed learning objective involving cooperation and competition, long-horizon decision-making, variable action spaces, and dynamic team composition. These characteristics make it a demanding testbed for existing intelligent decision-making methods. Moreover, the independent API for each player allows human-AI interactions and supports integration with large language models. Empirically, we conduct two types of evaluations: (1) pairwise competitions among all GuanDan AI agents, and (2) human-AI matchups. Experimental results demonstrate that while current learning-based agents substantially outperform rule-based counterparts, they still fall short of achieving superhuman performance, underscoring the need for continued research in multi-agent intelligent decision-making domain. The project is publicly available at https://github.com/GameAI-NJUPT/OpenGuanDan.
DISTA-Net: Dynamic Closely-Spaced Infrared Small Target Unmixing
May 25, 2025Resolving closely-spaced small targets in dense clusters presents a significant challenge in infrared imaging, as the overlapping signals hinder precise determination of their quantity, sub-pixel positions, and radiation intensities. While deep learning has advanced the field of infrared small target detection, its application to closely-spaced infrared small targets has not yet been explored. This gap exists primarily due to the complexity of separating superimposed characteristics and the lack of an open-source infrastructure. In this work, we propose the Dynamic Iterative Shrinkage Thresholding Network (DISTA-Net), which reconceptualizes traditional sparse reconstruction within a dynamic framework. DISTA-Net adaptively generates convolution weights and thresholding parameters to tailor the reconstruction process in real time. To the best of our knowledge, DISTA-Net is the first deep learning model designed specifically for the unmixing of closely-spaced infrared small targets, achieving superior sub-pixel detection accuracy. Moreover, we have established the first open-source ecosystem to foster further research in this field. This ecosystem comprises three key components: (1) CSIST-100K, a publicly available benchmark dataset; (2) CSO-mAP, a custom evaluation metric for sub-pixel detection; and (3) GrokCSO, an open-source toolkit featuring DISTA-Net and other models. Our code and dataset are available at https://github.com/GrokCV/GrokCSO.
Bellman Error Centering
Feb 05, 2025



This paper revisits the recently proposed reward centering algorithms including simple reward centering (SRC) and value-based reward centering (VRC), and points out that SRC is indeed the reward centering, while VRC is essentially Bellman error centering (BEC). Based on BEC, we provide the centered fixpoint for tabular value functions, as well as the centered TD fixpoint for linear value function approximation. We design the on-policy CTD algorithm and the off-policy CTDC algorithm, and prove the convergence of both algorithms. Finally, we experimentally validate the stability of our proposed algorithms. Bellman error centering facilitates the extension to various reinforcement learning algorithms.
A Variance Minimization Approach to Temporal-Difference Learning
Nov 10, 2024Fast-converging algorithms are a contemporary requirement in reinforcement learning. In the context of linear function approximation, the magnitude of the smallest eigenvalue of the key matrix is a major factor reflecting the convergence speed. Traditional value-based RL algorithms focus on minimizing errors. This paper introduces a variance minimization (VM) approach for value-based RL instead of error minimization. Based on this approach, we proposed two objectives, the Variance of Bellman Error (VBE) and the Variance of Projected Bellman Error (VPBE), and derived the VMTD, VMTDC, and VMETD algorithms. We provided proofs of their convergence and optimal policy invariance of the variance minimization. Experimental studies validate the effectiveness of the proposed algorithms.
Learning Credit Assignment for Cooperative Reinforcement Learning
Oct 10, 2022
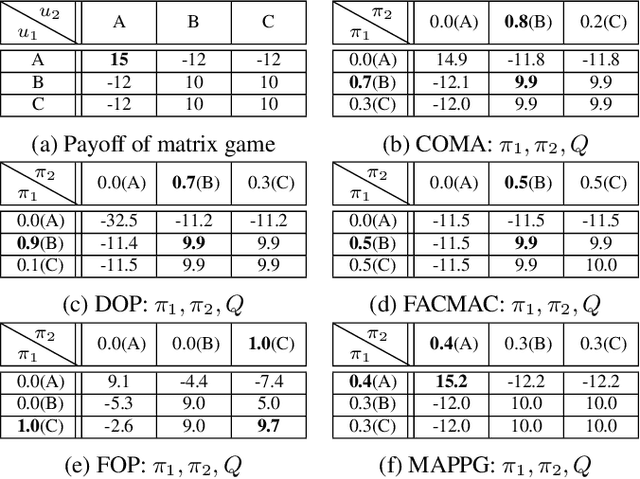
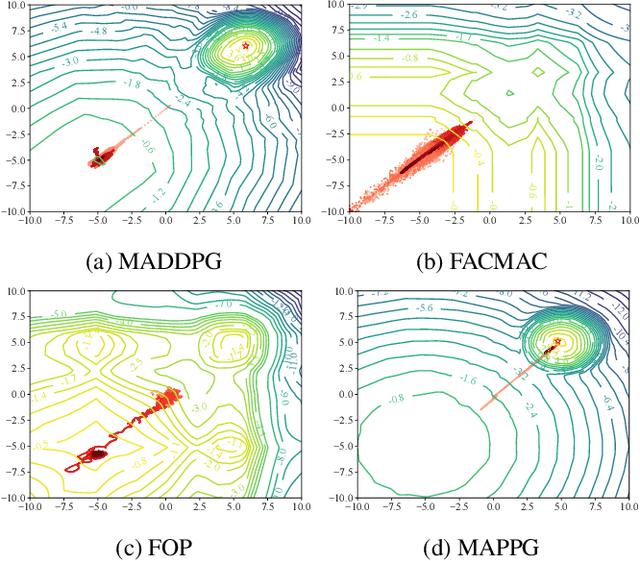
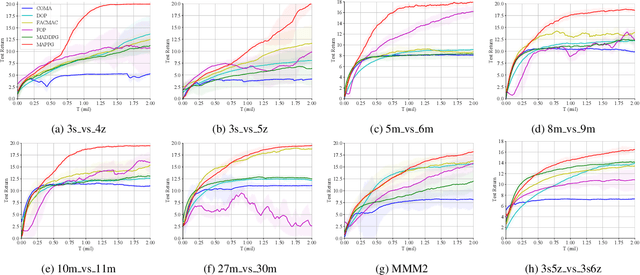
Cooperative multi-agent policy gradient (MAPG) algorithms have recently attracted wide attention and are regarded as a general scheme for the multi-agent system. Credit assignment plays an important role in MAPG and can induce cooperation among multiple agents. However, most MAPG algorithms cannot achieve good credit assignment because of the game-theoretic pathology known as \textit{centralized-decentralized mismatch}. To address this issue, this paper presents a novel method, \textit{\underline{M}ulti-\underline{A}gent \underline{P}olarization \underline{P}olicy \underline{G}radient} (MAPPG). MAPPG takes a simple but efficient polarization function to transform the optimal consistency of joint and individual actions into easily realized constraints, thus enabling efficient credit assignment in MAPG. Theoretically, we prove that individual policies of MAPPG can converge to the global optimum. Empirically, we evaluate MAPPG on the well-known matrix game and differential game, and verify that MAPPG can converge to the global optimum for both discrete and continuous action spaces. We also evaluate MAPPG on a set of StarCraft II micromanagement tasks and demonstrate that MAPPG outperforms the state-of-the-art MAPG algorithms.
Keeping Minimal Experience to Achieve Efficient Interpretable Policy Distillation
Mar 02, 2022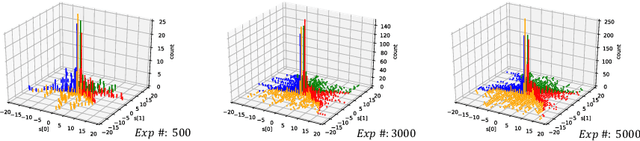

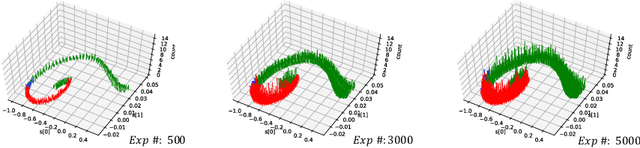
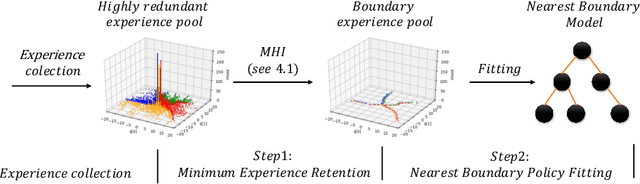
Although deep reinforcement learning has become a universal solution for complex control tasks, its real-world applicability is still limited because lacking security guarantees for policies. To address this problem, we propose Boundary Characterization via the Minimum Experience Retention (BCMER), an end-to-end Interpretable Policy Distillation (IPD) framework. Unlike previous IPD approaches, BCMER distinguishes the importance of experiences and keeps a minimal but critical experience pool with almost no loss of policy similarity. Specifically, the proposed BCMER contains two basic steps. Firstly, we propose a novel multidimensional hyperspheres intersection (MHI) approach to divide experience points into boundary points and internal points, and reserve the crucial boundary points. Secondly, we develop a nearest-neighbor-based model to generate robust and interpretable decision rules based on the boundary points. Extensive experiments show that the proposed BCMER is able to reduce the amount of experience to 1.4%~19.1% (when the count of the naive experiences is 10k) and maintain high IPD performance. In general, the proposed BCMER is more suitable for the experience storage limited regime because it discovers the critical experience and eliminates redundant experience.
Online Attentive Kernel-Based Temporal Difference Learning
Jan 22, 2022



With rising uncertainty in the real world, online Reinforcement Learning (RL) has been receiving increasing attention due to its fast learning capability and improving data efficiency. However, online RL often suffers from complex Value Function Approximation (VFA) and catastrophic interference, creating difficulty for the deep neural network to be applied to an online RL algorithm in a fully online setting. Therefore, a simpler and more adaptive approach is introduced to evaluate value function with the kernel-based model. Sparse representations are superior at handling interference, indicating that competitive sparse representations should be learnable, non-prior, non-truncated and explicit when compared with current sparse representation methods. Moreover, in learning sparse representations, attention mechanisms are utilized to represent the degree of sparsification, and a smooth attentive function is introduced into the kernel-based VFA. In this paper, we propose an Online Attentive Kernel-Based Temporal Difference (OAKTD) algorithm using two-timescale optimization and provide convergence analysis of our proposed algorithm. Experimental evaluations showed that OAKTD outperformed several Online Kernel-based Temporal Difference (OKTD) learning algorithms in addition to the Temporal Difference (TD) learning algorithm with Tile Coding on public Mountain Car, Acrobot, CartPole and Puddle World tasks.