 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbability-density-aware Semi-supervised Learning
Dec 23, 2024Semi-supervised learning (SSL) assumes that neighbor points lie in the same category (neighbor assumption), and points in different clusters belong to various categories (cluster assumption). Existing methods usually rely on similarity measures to retrieve the similar neighbor points, ignoring cluster assumption, which may not utilize unlabeled information sufficiently and effectively. This paper first provides a systematical investigation into the significant role of probability density in SSL and lays a solid theoretical foundation for cluster assumption. To this end, we introduce a Probability-Density-Aware Measure (PM) to discern the similarity between neighbor points. To further improve Label Propagation, we also design a Probability-Density-Aware Measure Label Propagation (PMLP) algorithm to fully consider the cluster assumption in label propagation. Last but not least, we prove that traditional pseudo-labeling could be viewed as a particular case of PMLP, which provides a comprehensive theoretical understanding of PMLP's superior performance. Extensive experiments demonstrate that PMLP achieves outstanding performance compared with other recent methods.
Open-Set Video-based Facial Expression Recognition with Human Expression-sensitive Prompting
Apr 26, 2024In Video-based Facial Expression Recognition (V-FER), models are typically trained on closed-set datasets with a fixed number of known classes. However, these V-FER models cannot deal with unknown classes that are prevalent in real-world scenarios. In this paper, we introduce a challenging Open-set Video-based Facial Expression Recognition (OV-FER) task, aiming at identifying not only known classes but also new, unknown human facial expressions not encountered during training. While existing approaches address open-set recognition by leveraging large-scale vision-language models like CLIP to identify unseen classes, we argue that these methods may not adequately capture the nuanced and subtle human expression patterns required by the OV-FER task. To address this limitation, we propose a novel Human Expression-Sensitive Prompting (HESP) mechanism to significantly enhance CLIP's ability to model video-based facial expression details effectively, thereby presenting a new CLIP-based OV-FER approach. Our proposed HESP comprises three components: 1) a textual prompting module with learnable prompt representations to complement the original CLIP textual prompts and enhance the textual representations of both known and unknown emotions, 2) a visual prompting module that encodes temporal emotional information from video frames using expression-sensitive attention, equipping CLIP with a new visual modeling ability to extract emotion-rich information, 3) a delicately designed open-set multi-task learning scheme that facilitates prompt learning and encourages interactions between the textual and visual prompting modules. Extensive experiments conducted on four OV-FER task settings demonstrate that HESP can significantly boost CLIP's performance (a relative improvement of 17.93% on AUROC and 106.18% on OSCR) and outperform other state-of-the-art open-set video understanding methods by a large margin.
Rethink Baseline of Integrated Gradients from the Perspective of Shapley Value
Oct 10, 2023Numerous approaches have attempted to interpret deep neural networks (DNNs) by attributing the prediction of DNN to its input features. One of the well-studied attribution methods is Integrated Gradients (IG). Specifically, the choice of baselines for IG is a critical consideration for generating meaningful and unbiased explanations for model predictions in different scenarios. However, current practice of exploiting a single baseline fails to fulfill this ambition, thus demanding multiple baselines. Fortunately, the inherent connection between IG and Aumann-Shapley Value forms a unique perspective to rethink the design of baselines. Under certain hypothesis, we theoretically analyse that a set of baseline aligns with the coalitions in Shapley Value. Thus, we propose a novel baseline construction method called Shapley Integrated Gradients (SIG) that searches for a set of baselines by proportional sampling to partly simulate the computation path of Shapley Value. Simulations on GridWorld show that SIG approximates the proportion of Shapley Values. Furthermore, experiments conducted on various image tasks demonstrate that compared to IG using other baseline methods, SIG exhibits an improved estimation of feature's contribution, offers more consistent explanations across diverse applications, and is generic to distinct data types or instances with insignificant computational overhead.
CasIL: Cognizing and Imitating Skills via a Dual Cognition-Action Architecture
Sep 28, 2023Enabling robots to effectively imitate expert skills in longhorizon tasks such as locomotion, manipulation, and more, poses a long-standing challenge. Existing imitation learning (IL) approaches for robots still grapple with sub-optimal performance in complex tasks. In this paper, we consider how this challenge can be addressed within the human cognitive priors. Heuristically, we extend the usual notion of action to a dual Cognition (high-level)-Action (low-level) architecture by introducing intuitive human cognitive priors, and propose a novel skill IL framework through human-robot interaction, called Cognition-Action-based Skill Imitation Learning (CasIL), for the robotic agent to effectively cognize and imitate the critical skills from raw visual demonstrations. CasIL enables both cognition and action imitation, while high-level skill cognition explicitly guides low-level primitive actions, providing robustness and reliability to the entire skill IL process. We evaluated our method on MuJoCo and RLBench benchmarks, as well as on the obstacle avoidance and point-goal navigation tasks for quadrupedal robot locomotion. Experimental results show that our CasIL consistently achieves competitive and robust skill imitation capability compared to other counterparts in a variety of long-horizon robotic tasks.
Symmetry-Preserving Program Representations for Learning Code Semantics
Aug 07, 2023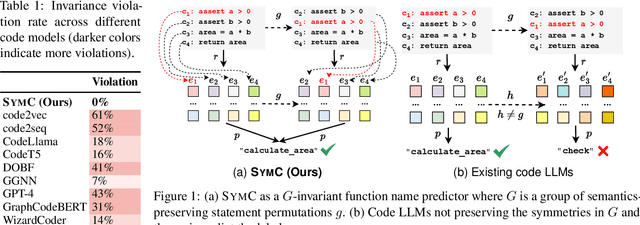
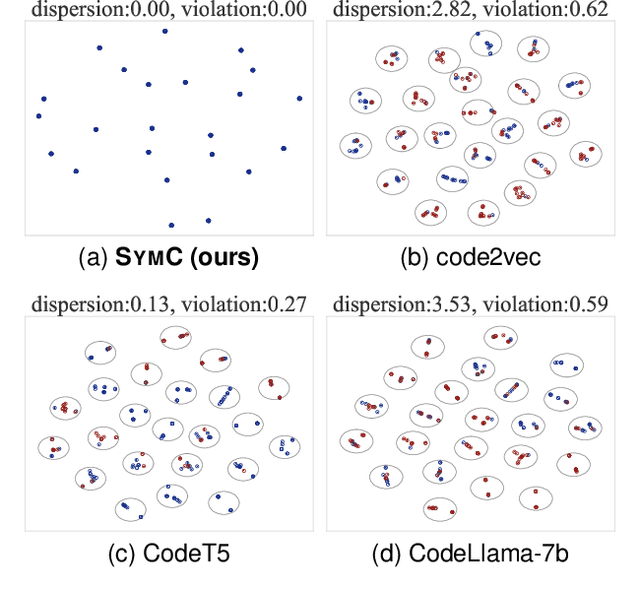
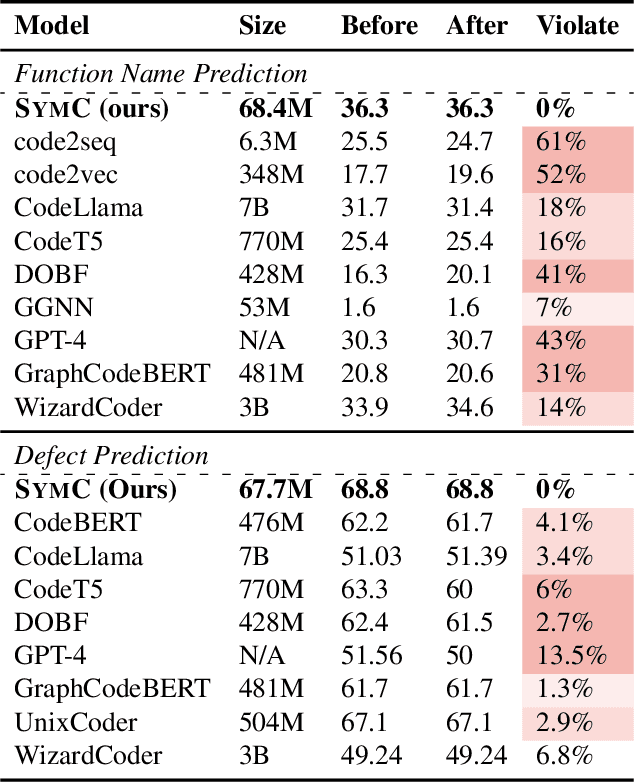
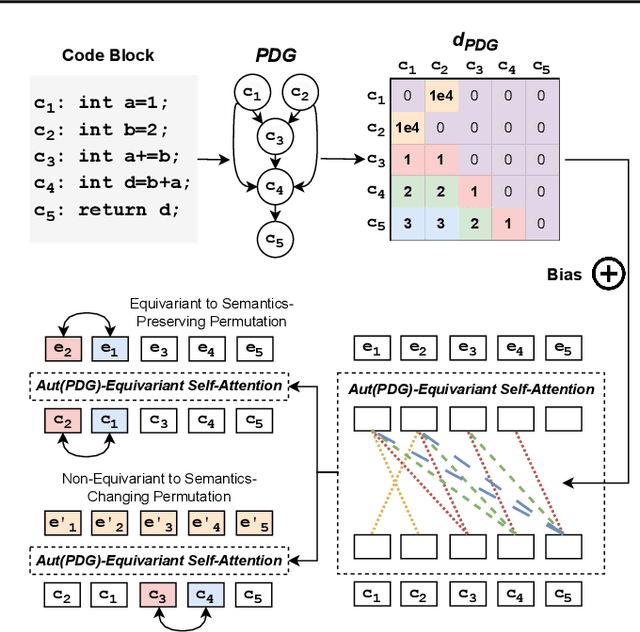
Large Language Models (LLMs) have shown promise in automated program reasoning, a crucial aspect of many security tasks. However, existing LLM architectures for code are often borrowed from other domains like natural language processing, raising concerns about their generalization and robustness to unseen code. A key generalization challenge is to incorporate the knowledge of code semantics, including control and data flow, into the LLM architectures. Drawing inspiration from examples of convolution layers exploiting translation symmetry, we explore how code symmetries can enhance LLM architectures for program analysis and modeling. We present a rigorous group-theoretic framework that formally defines code symmetries as semantics-preserving transformations and provides techniques for precisely reasoning about symmetry preservation within LLM architectures. Using this framework, we introduce a novel variant of self-attention that preserves program symmetries, demonstrating its effectiveness in generalization and robustness through detailed experimental evaluations across different binary and source code analysis tasks. Overall, our code symmetry framework offers rigorous and powerful reasoning techniques that can guide the future development of specialized LLMs for code and advance LLM-guided program reasoning tasks.
Keeping Minimal Experience to Achieve Efficient Interpretable Policy Distillation
Mar 02, 2022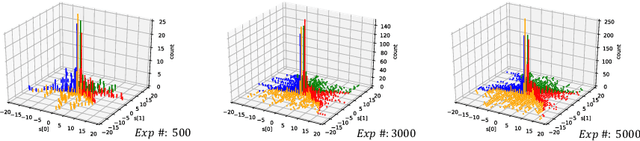

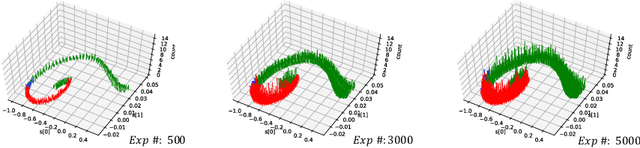
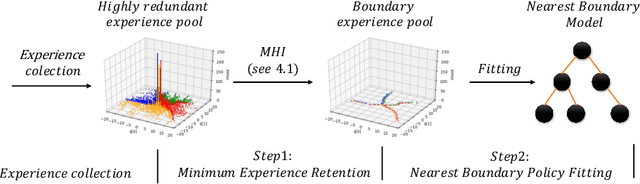
Although deep reinforcement learning has become a universal solution for complex control tasks, its real-world applicability is still limited because lacking security guarantees for policies. To address this problem, we propose Boundary Characterization via the Minimum Experience Retention (BCMER), an end-to-end Interpretable Policy Distillation (IPD) framework. Unlike previous IPD approaches, BCMER distinguishes the importance of experiences and keeps a minimal but critical experience pool with almost no loss of policy similarity. Specifically, the proposed BCMER contains two basic steps. Firstly, we propose a novel multidimensional hyperspheres intersection (MHI) approach to divide experience points into boundary points and internal points, and reserve the crucial boundary points. Secondly, we develop a nearest-neighbor-based model to generate robust and interpretable decision rules based on the boundary points. Extensive experiments show that the proposed BCMER is able to reduce the amount of experience to 1.4%~19.1% (when the count of the naive experiences is 10k) and maintain high IPD performance. In general, the proposed BCMER is more suitable for the experience storage limited regime because it discovers the critical experience and eliminates redundant experience.