 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVP-Shapley: Feature-based Modeling for Evaluating the Most Valuable Player in Basketball
Jun 05, 2025The burgeoning growth of the esports and multiplayer online gaming community has highlighted the critical importance of evaluating the Most Valuable Player (MVP). The establishment of an explainable and practical MVP evaluation method is very challenging. In our study, we specifically focus on play-by-play data, which records related events during the game, such as assists and points. We aim to address the challenges by introducing a new MVP evaluation framework, denoted as \oursys, which leverages Shapley values. This approach encompasses feature processing, win-loss model training, Shapley value allocation, and MVP ranking determination based on players' contributions. Additionally, we optimize our algorithm to align with expert voting results from the perspective of causality. Finally, we substantiated the efficacy of our method through validation using the NBA dataset and the Dunk City Dynasty dataset and implemented online deployment in the industry.
Fast-DataShapley: Neural Modeling for Training Data Valuation
Jun 05, 2025The value and copyright of training data are crucial in the artificial intelligence industry. Service platforms should protect data providers' legitimate rights and fairly reward them for their contributions. Shapley value, a potent tool for evaluating contributions, outperforms other methods in theory, but its computational overhead escalates exponentially with the number of data providers. Recent works based on Shapley values attempt to mitigate computation complexity by approximation algorithms. However, they need to retrain for each test sample, leading to intolerable costs. We propose Fast-DataShapley, a one-pass training method that leverages the weighted least squares characterization of the Shapley value to train a reusable explainer model with real-time reasoning speed. Given new test samples, no retraining is required to calculate the Shapley values of the training data. Additionally, we propose three methods with theoretical guarantees to reduce training overhead from two aspects: the approximate calculation of the utility function and the group calculation of the training data. We analyze time complexity to show the efficiency of our methods. The experimental evaluations on various image datasets demonstrate superior performance and efficiency compared to baselines. Specifically, the performance is improved to more than 2.5 times, and the explainer's training speed can be increased by two orders of magnitude.
MiraData: A Large-Scale Video Dataset with Long Durations and Structured Captions
Jul 08, 2024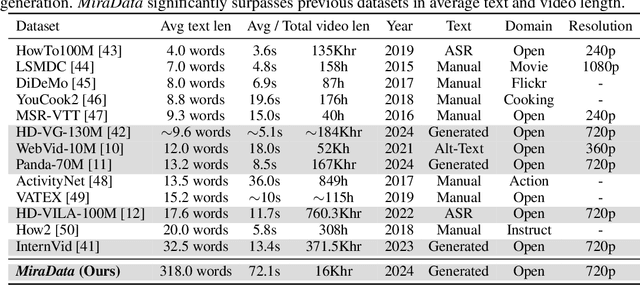
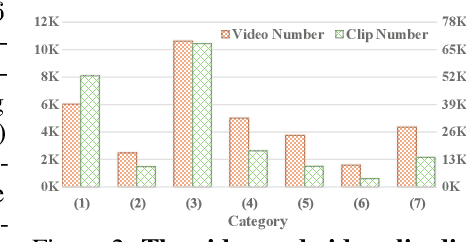


Sora's high-motion intensity and long consistent videos have significantly impacted the field of video generation, attracting unprecedented attention. However, existing publicly available datasets are inadequate for generating Sora-like videos, as they mainly contain short videos with low motion intensity and brief captions. To address these issues, we propose MiraData, a high-quality video dataset that surpasses previous ones in video duration, caption detail, motion strength, and visual quality. We curate MiraData from diverse, manually selected sources and meticulously process the data to obtain semantically consistent clips. GPT-4V is employed to annotate structured captions, providing detailed descriptions from four different perspectives along with a summarized dense caption. To better assess temporal consistency and motion intensity in video generation, we introduce MiraBench, which enhances existing benchmarks by adding 3D consistency and tracking-based motion strength metrics. MiraBench includes 150 evaluation prompts and 17 metrics covering temporal consistency, motion strength, 3D consistency, visual quality, text-video alignment, and distribution similarity. To demonstrate the utility and effectiveness of MiraData, we conduct experiments using our DiT-based video generation model, MiraDiT. The experimental results on MiraBench demonstrate the superiority of MiraData, especially in motion strength.
A dataset of primary nasopharyngeal carcinoma MRI with multi-modalities segmentation
Apr 04, 2024Multi-modality magnetic resonance imaging data with various sequences facilitate the early diagnosis, tumor segmentation, and disease staging in the management of nasopharyngeal carcinoma (NPC). The lack of publicly available, comprehensive datasets limits advancements in diagnosis, treatment planning, and the development of machine learning algorithms for NPC. Addressing this critical need, we introduce the first comprehensive NPC MRI dataset, encompassing MR axial imaging of 277 primary NPC patients. This dataset includes T1-weighted, T2-weighted, and contrast-enhanced T1-weighted sequences, totaling 831 scans. In addition to the corresponding clinical data, manually annotated and labeled segmentations by experienced radiologists offer high-quality data resources from untreated primary NPC.
XRL-Bench: A Benchmark for Evaluating and Comparing Explainable Reinforcement Learning Techniques
Feb 20, 2024



Reinforcement Learning (RL) has demonstrated substantial potential across diverse fields, yet understanding its decision-making process, especially in real-world scenarios where rationality and safety are paramount, is an ongoing challenge. This paper delves in to Explainable RL (XRL), a subfield of Explainable AI (XAI) aimed at unravelling the complexities of RL models. Our focus rests on state-explaining techniques, a crucial subset within XRL methods, as they reveal the underlying factors influencing an agent's actions at any given time. Despite their significant role, the lack of a unified evaluation framework hinders assessment of their accuracy and effectiveness. To address this, we introduce XRL-Bench, a unified standardized benchmark tailored for the evaluation and comparison of XRL methods, encompassing three main modules: standard RL environments, explainers based on state importance, and standard evaluators. XRL-Bench supports both tabular and image data for state explanation. We also propose TabularSHAP, an innovative and competitive XRL method. We demonstrate the practical utility of TabularSHAP in real-world online gaming services and offer an open-source benchmark platform for the straightforward implementation and evaluation of XRL methods. Our contributions facilitate the continued progression of XRL technology.
Sequential Model for Predicting Patient Adherence in Subcutaneous Immunotherapy for Allergic Rhinitis
Jan 23, 2024



Objective: Subcutaneous Immunotherapy (SCIT) is the long-lasting causal treatment of allergic rhinitis. How to enhance the adherence of patients to maximize the benefit of allergen immunotherapy (AIT) plays a crucial role in the management of AIT. This study aims to leverage novel machine learning models to precisely predict the risk of non-adherence of patients and related systematic symptom scores, to provide a novel approach in the management of long-term AIT. Methods: The research develops and analyzes two models, Sequential Latent Actor-Critic (SLAC) and Long Short-Term Memory (LSTM), evaluating them based on scoring and adherence prediction capabilities. Results: Excluding the biased samples at the first time step, the predictive adherence accuracy of the SLAC models is from $60\,\%$ to $72\%$, and for LSTM models, it is $66\,\%$ to $84\,\%$, varying according to the time steps. The range of Root Mean Square Error (RMSE) for SLAC models is between $0.93$ and $2.22$, while for LSTM models it is between $1.09$ and $1.77$. Notably, these RMSEs are significantly lower than the random prediction error of $4.55$. Conclusion: We creatively apply sequential models in the long-term management of SCIT with promising accuracy in the prediction of SCIT nonadherence in Allergic Rhinitis (AR) patients. While LSTM outperforms SLAC in adherence prediction, SLAC excels in score prediction for patients undergoing SCIT for AR. The state-action-based SLAC adds flexibility, presenting a novel and effective approach for managing long-term AIT.
Robust Beamforming for Downlink Multi-Cell Systems: A Bilevel Optimization Perspective
Jan 21, 2024Utilization of inter-base station cooperation for information processing has shown great potential in enhancing the overall quality of communication services (QoS) in wireless communication networks. Nevertheless, such cooperations require the knowledge of channel state information (CSI) at base stations (BSs), which is assumed to be perfectly known. However, CSI errors are inevitable in practice which necessitates beamforming techniques that can achieve robust performance in the presence of channel estimation errors. Existing approaches relax the robust beamforming design problems into semidefinite programming (SDP), which can only achieve a solution that is far from being optimal. To this end, this paper views robust beamforming design problems from a bilevel optimization perspective. In particular, we focus on maximizing the worst-case weighted sum-rate (WSR) in the downlink multi-cell multi-user multiple-input single-output (MISO) system considering bounded CSI errors. We first reformulate this problem into a bilevel optimization problem and then develop an efficient algorithm based on the cutting plane method. A distributed optimization algorithm has also been developed to facilitate the parallel processing in practical settings. Numerical results are provided to confirm the effectiveness of the proposed algorithm in terms of performance and complexity, particularly in the presence of CSI uncertainties.
PAD: Self-Supervised Pre-Training with Patchwise-Scale Adapter for Infrared Images
Dec 13, 2023



Self-supervised learning (SSL) for RGB images has achieved significant success, yet there is still limited research on SSL for infrared images, primarily due to three prominent challenges: 1) the lack of a suitable large-scale infrared pre-training dataset, 2) the distinctiveness of non-iconic infrared images rendering common pre-training tasks like masked image modeling (MIM) less effective, and 3) the scarcity of fine-grained textures making it particularly challenging to learn general image features. To address these issues, we construct a Multi-Scene Infrared Pre-training (MSIP) dataset comprising 178,756 images, and introduce object-sensitive random RoI cropping, an image preprocessing method, to tackle the challenge posed by non-iconic images. To alleviate the impact of weak textures on feature learning, we propose a pre-training paradigm called Pre-training with ADapter (PAD), which uses adapters to learn domain-specific features while freezing parameters pre-trained on ImageNet to retain the general feature extraction capability. This new paradigm is applicable to any transformer-based SSL method. Furthermore, to achieve more flexible coordination between pre-trained and newly-learned features in different layers and patches, a patchwise-scale adapter with dynamically learnable scale factors is introduced. Extensive experiments on three downstream tasks show that PAD, with only 1.23M pre-trainable parameters, outperforms other baseline paradigms including continual full pre-training on MSIP. Our code and dataset are available at https://github.com/casiatao/PAD.
Rethink Baseline of Integrated Gradients from the Perspective of Shapley Value
Oct 10, 2023Numerous approaches have attempted to interpret deep neural networks (DNNs) by attributing the prediction of DNN to its input features. One of the well-studied attribution methods is Integrated Gradients (IG). Specifically, the choice of baselines for IG is a critical consideration for generating meaningful and unbiased explanations for model predictions in different scenarios. However, current practice of exploiting a single baseline fails to fulfill this ambition, thus demanding multiple baselines. Fortunately, the inherent connection between IG and Aumann-Shapley Value forms a unique perspective to rethink the design of baselines. Under certain hypothesis, we theoretically analyse that a set of baseline aligns with the coalitions in Shapley Value. Thus, we propose a novel baseline construction method called Shapley Integrated Gradients (SIG) that searches for a set of baselines by proportional sampling to partly simulate the computation path of Shapley Value. Simulations on GridWorld show that SIG approximates the proportion of Shapley Values. Furthermore, experiments conducted on various image tasks demonstrate that compared to IG using other baseline methods, SIG exhibits an improved estimation of feature's contribution, offers more consistent explanations across diverse applications, and is generic to distinct data types or instances with insignificant computational overhead.
A Model-Agnostic Framework for Recommendation via Interest-aware Item Embeddings
Aug 17, 2023Item representation holds significant importance in recommendation systems, which encompasses domains such as news, retail, and videos. Retrieval and ranking models utilise item representation to capture the user-item relationship based on user behaviours. While existing representation learning methods primarily focus on optimising item-based mechanisms, such as attention and sequential modelling. However, these methods lack a modelling mechanism to directly reflect user interests within the learned item representations. Consequently, these methods may be less effective in capturing user interests indirectly. To address this challenge, we propose a novel Interest-aware Capsule network (IaCN) recommendation model, a model-agnostic framework that directly learns interest-oriented item representations. IaCN serves as an auxiliary task, enabling the joint learning of both item-based and interest-based representations. This framework adopts existing recommendation models without requiring substantial redesign. We evaluate the proposed approach on benchmark datasets, exploring various scenarios involving different deep neural networks, behaviour sequence lengths, and joint learning ratios of interest-oriented item representations. Experimental results demonstrate significant performance enhancements across diverse recommendation models, validating the effectiveness of our approach.