 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Graph Transformer with Serialized Graph Tokens
Feb 09, 2026Transformers have demonstrated success in graph learning, particularly for node-level tasks. However, existing methods encounter an information bottleneck when generating graph-level representations. The prevalent single token paradigm fails to fully leverage the inherent strength of self-attention in encoding token sequences, and degenerates into a weighted sum of node signals. To address this issue, we design a novel serialized token paradigm to encapsulate global signals more effectively. Specifically, a graph serialization method is proposed to aggregate node signals into serialized graph tokens, with positional encoding being automatically involved. Then, stacked self-attention layers are applied to encode this token sequence and capture its internal dependencies. Our method can yield more expressive graph representations by modeling complex interactions among multiple graph tokens. Experimental results show that our method achieves state-of-the-art results on several graph-level benchmarks. Ablation studies verify the effectiveness of the proposed modules.
IF-Bench: Benchmarking and Enhancing MLLMs for Infrared Images with Generative Visual Prompting
Dec 10, 2025Recent advances in multimodal large language models (MLLMs) have led to impressive progress across various benchmarks. However, their capability in understanding infrared images remains unexplored. To address this gap, we introduce IF-Bench, the first high-quality benchmark designed for evaluating multimodal understanding of infrared images. IF-Bench consists of 499 images sourced from 23 infrared datasets and 680 carefully curated visual question-answer pairs, covering 10 essential dimensions of image understanding. Based on this benchmark, we systematically evaluate over 40 open-source and closed-source MLLMs, employing cyclic evaluation, bilingual assessment, and hybrid judgment strategies to enhance the reliability of the results. Our analysis reveals how model scale, architecture, and inference paradigms affect infrared image comprehension, providing valuable insights for this area. Furthermore, we propose a training-free generative visual prompting (GenViP) method, which leverages advanced image editing models to translate infrared images into semantically and spatially aligned RGB counterparts, thereby mitigating domain distribution shifts. Extensive experiments demonstrate that our method consistently yields significant performance improvements across a wide range of MLLMs. The benchmark and code are available at https://github.com/casiatao/IF-Bench.
UNIP: Rethinking Pre-trained Attention Patterns for Infrared Semantic Segmentation
Feb 04, 2025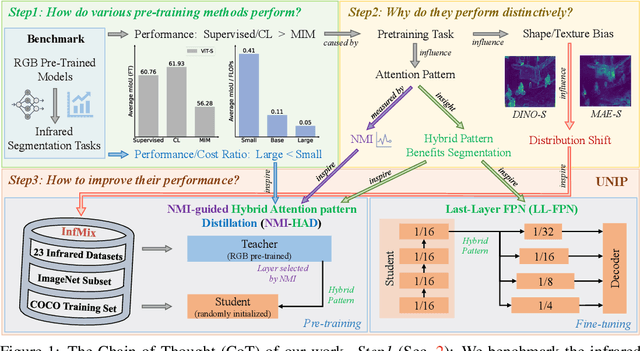
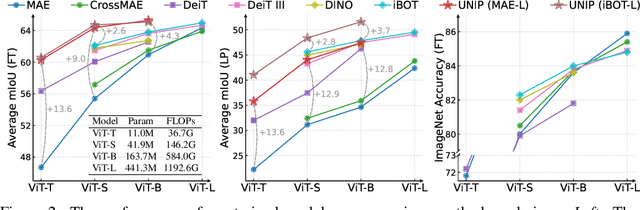
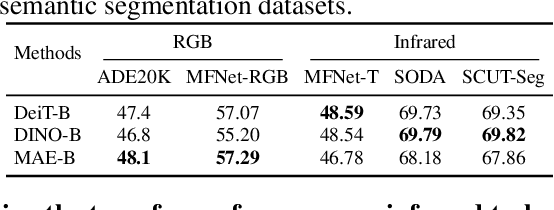
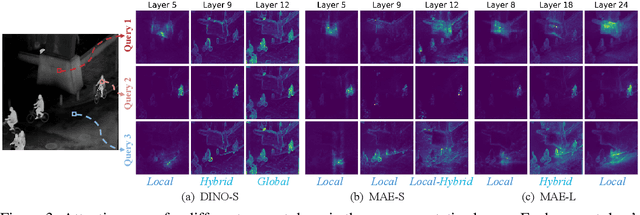
Pre-training techniques significantly enhance the performance of semantic segmentation tasks with limited training data. However, the efficacy under a large domain gap between pre-training (e.g. RGB) and fine-tuning (e.g. infrared) remains underexplored. In this study, we first benchmark the infrared semantic segmentation performance of various pre-training methods and reveal several phenomena distinct from the RGB domain. Next, our layerwise analysis of pre-trained attention maps uncovers that: (1) There are three typical attention patterns (local, hybrid, and global); (2) Pre-training tasks notably influence the pattern distribution across layers; (3) The hybrid pattern is crucial for semantic segmentation as it attends to both nearby and foreground elements; (4) The texture bias impedes model generalization in infrared tasks. Building on these insights, we propose UNIP, a UNified Infrared Pre-training framework, to enhance the pre-trained model performance. This framework uses the hybrid-attention distillation NMI-HAD as the pre-training target, a large-scale mixed dataset InfMix for pre-training, and a last-layer feature pyramid network LL-FPN for fine-tuning. Experimental results show that UNIP outperforms various pre-training methods by up to 13.5\% in average mIoU on three infrared segmentation tasks, evaluated using fine-tuning and linear probing metrics. UNIP-S achieves performance on par with MAE-L while requiring only 1/10 of the computational cost. Furthermore, UNIP significantly surpasses state-of-the-art (SOTA) infrared or RGB segmentation methods and demonstrates broad potential for application in other modalities, such as RGB and depth. Our code is available at https://github.com/casiatao/UNIP.
Diffusion Model as a Noise-Aware Latent Reward Model for Step-Level Preference Optimization
Feb 03, 2025



Preference optimization for diffusion models aims to align them with human preferences for images. Previous methods typically leverage Vision-Language Models (VLMs) as pixel-level reward models to approximate human preferences. However, when used for step-level preference optimization, these models face challenges in handling noisy images of different timesteps and require complex transformations into pixel space. In this work, we demonstrate that diffusion models are inherently well-suited for step-level reward modeling in the latent space, as they can naturally extract features from noisy latent images. Accordingly, we propose the Latent Reward Model (LRM), which repurposes components of diffusion models to predict preferences of latent images at various timesteps. Building on LRM, we introduce Latent Preference Optimization (LPO), a method designed for step-level preference optimization directly in the latent space. Experimental results indicate that LPO not only significantly enhances performance in aligning diffusion models with general, aesthetic, and text-image alignment preferences, but also achieves 2.5-28$\times$ training speedup compared to existing preference optimization methods. Our code will be available at https://github.com/casiatao/LPO.
Weak Distribution Detectors Lead to Stronger Generalizability of Vision-Language Prompt Tuning
Mar 31, 2024



We propose a generalized method for boosting the generalization ability of pre-trained vision-language models (VLMs) while fine-tuning on downstream few-shot tasks. The idea is realized by exploiting out-of-distribution (OOD) detection to predict whether a sample belongs to a base distribution or a novel distribution and then using the score generated by a dedicated competition based scoring function to fuse the zero-shot and few-shot classifier. The fused classifier is dynamic, which will bias towards the zero-shot classifier if a sample is more likely from the distribution pre-trained on, leading to improved base-to-novel generalization ability. Our method is performed only in test stage, which is applicable to boost existing methods without time-consuming re-training. Extensive experiments show that even weak distribution detectors can still improve VLMs' generalization ability. Specifically, with the help of OOD detectors, the harmonic mean of CoOp and ProGrad increase by 2.6 and 1.5 percentage points over 11 recognition datasets in the base-to-novel setting.
Reusable Architecture Growth for Continual Stereo Matching
Mar 30, 2024



The remarkable performance of recent stereo depth estimation models benefits from the successful use of convolutional neural networks to regress dense disparity. Akin to most tasks, this needs gathering training data that covers a number of heterogeneous scenes at deployment time. However, training samples are typically acquired continuously in practical applications, making the capability to learn new scenes continually even more crucial. For this purpose, we propose to perform continual stereo matching where a model is tasked to 1) continually learn new scenes, 2) overcome forgetting previously learned scenes, and 3) continuously predict disparities at inference. We achieve this goal by introducing a Reusable Architecture Growth (RAG) framework. RAG leverages task-specific neural unit search and architecture growth to learn new scenes continually in both supervised and self-supervised manners. It can maintain high reusability during growth by reusing previous units while obtaining good performance. Additionally, we present a Scene Router module to adaptively select the scene-specific architecture path at inference. Comprehensive experiments on numerous datasets show that our framework performs impressively in various weather, road, and city circumstances and surpasses the state-of-the-art methods in more challenging cross-dataset settings. Further experiments also demonstrate the adaptability of our method to unseen scenes, which can facilitate end-to-end stereo architecture learning and practical deployment.
PAD: Self-Supervised Pre-Training with Patchwise-Scale Adapter for Infrared Images
Dec 13, 2023



Self-supervised learning (SSL) for RGB images has achieved significant success, yet there is still limited research on SSL for infrared images, primarily due to three prominent challenges: 1) the lack of a suitable large-scale infrared pre-training dataset, 2) the distinctiveness of non-iconic infrared images rendering common pre-training tasks like masked image modeling (MIM) less effective, and 3) the scarcity of fine-grained textures making it particularly challenging to learn general image features. To address these issues, we construct a Multi-Scene Infrared Pre-training (MSIP) dataset comprising 178,756 images, and introduce object-sensitive random RoI cropping, an image preprocessing method, to tackle the challenge posed by non-iconic images. To alleviate the impact of weak textures on feature learning, we propose a pre-training paradigm called Pre-training with ADapter (PAD), which uses adapters to learn domain-specific features while freezing parameters pre-trained on ImageNet to retain the general feature extraction capability. This new paradigm is applicable to any transformer-based SSL method. Furthermore, to achieve more flexible coordination between pre-trained and newly-learned features in different layers and patches, a patchwise-scale adapter with dynamically learnable scale factors is introduced. Extensive experiments on three downstream tasks show that PAD, with only 1.23M pre-trainable parameters, outperforms other baseline paradigms including continual full pre-training on MSIP. Our code and dataset are available at https://github.com/casiatao/PAD.
Prompt Tuning with Soft Context Sharing for Vision-Language Models
Aug 29, 2022

Vision-language models have recently shown great potential on many computer vision tasks. Meanwhile, prior work demonstrates prompt tuning designed for vision-language models could acquire superior performance on few-shot image recognition compared to linear probe, a strong baseline. In real-world applications, many few-shot tasks are correlated, particularly in a specialized area. However, such information is ignored by previous work. Inspired by the fact that modeling task relationships by multi-task learning can usually boost performance, we propose a novel method SoftCPT (Soft Context Sharing for Prompt Tuning) to fine-tune pre-trained vision-language models on multiple target few-shot tasks, simultaneously. Specifically, we design a task-shared meta network to generate prompt vector for each task using pre-defined task name together with a learnable meta prompt as input. As such, the prompt vectors of all tasks will be shared in a soft manner. The parameters of this shared meta network as well as the meta prompt vector are tuned on the joint training set of all target tasks. Extensive experiments on three multi-task few-shot datasets show that SoftCPT outperforms the representative single-task prompt tuning method CoOp [78] by a large margin, implying the effectiveness of multi-task learning in vision-language prompt tuning. The source code and data will be made publicly available.
Pro-tuning: Unified Prompt Tuning for Vision Tasks
Aug 14, 2022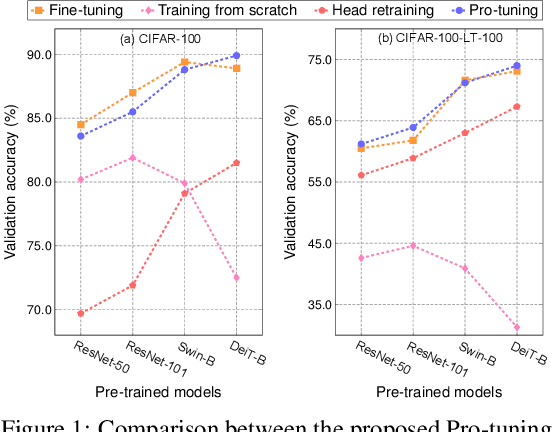
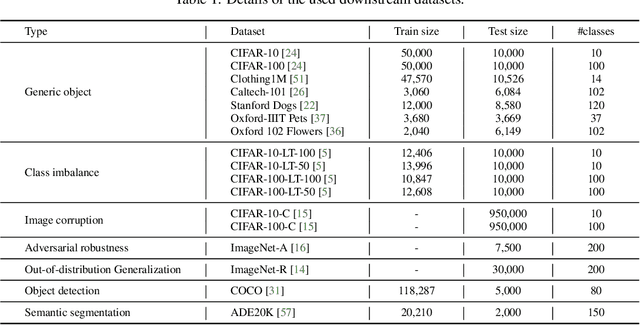
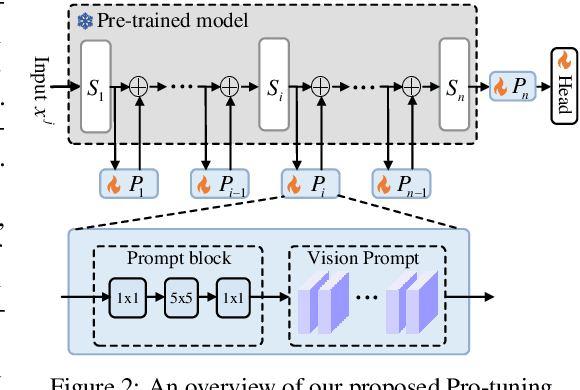
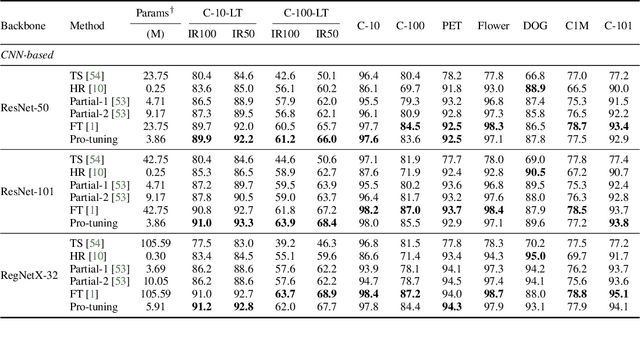
In computer vision, fine-tuning is the de-facto approach to leverage pre-trained vision models to perform downstream tasks. However, deploying it in practice is quite challenging, due to adopting parameter inefficient global update and heavily relying on high-quality downstream data. Recently, prompt-based learning, which adds a task-relevant prompt to adapt the downstream tasks to pre-trained models, has drastically boosted the performance of many natural language downstream tasks. In this work, we extend this notable transfer ability benefited from prompt into vision models as an alternative to fine-tuning. To this end, we propose parameter-efficient Prompt tuning (Pro-tuning) to adapt frozen vision models to various downstream vision tasks. The key to Pro-tuning is prompt-based tuning, i.e., learning task-specific vision prompts for downstream input images with the pre-trained model frozen. By only training a few additional parameters, it can work on diverse CNN-based and Transformer-based architectures. Extensive experiments evidence that Pro-tuning outperforms fine-tuning in a broad range of vision tasks and scenarios, including image classification (generic objects, class imbalance, image corruption, adversarial robustness, and out-of-distribution generalization), and dense prediction tasks such as object detection and semantic segmentation.
Differentiable Convolution Search for Point Cloud Processing
Aug 29, 2021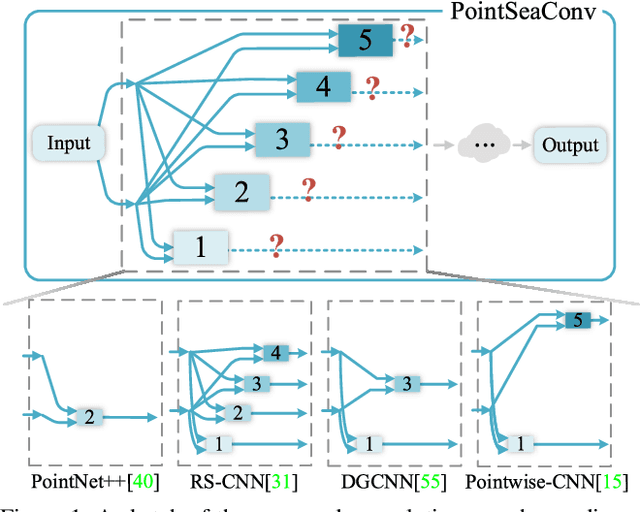

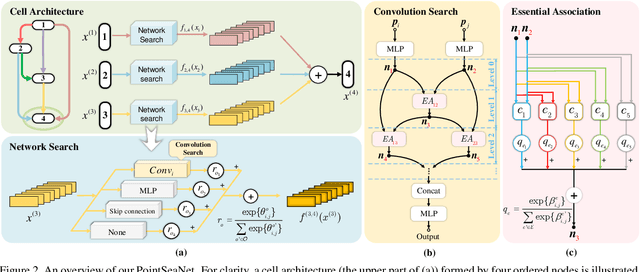

Exploiting convolutional neural networks for point cloud processing is quite challenging, due to the inherent irregular distribution and discrete shape representation of point clouds. To address these problems, many handcrafted convolution variants have sprung up in recent years. Though with elaborate design, these variants could be far from optimal in sufficiently capturing diverse shapes formed by discrete points. In this paper, we propose PointSeaConv, i.e., a novel differential convolution search paradigm on point clouds. It can work in a purely data-driven manner and thus is capable of auto-creating a group of suitable convolutions for geometric shape modeling. We also propose a joint optimization framework for simultaneous search of internal convolution and external architecture, and introduce epsilon-greedy algorithm to alleviate the effect of discretization error. As a result, PointSeaNet, a deep network that is sufficient to capture geometric shapes at both convolution level and architecture level, can be searched out for point cloud processing. Extensive experiments strongly evidence that our proposed PointSeaNet surpasses current handcrafted deep models on challenging benchmarks across multiple tasks with remarkable margins.