 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskAlign: Token-Subset Representation Alignment for Efficient Diffusion Training
Jun 07, 2026Representation alignment with pretrained vision models has recently shown strong potential for accelerating diffusion transformer training. By aligning intermediate diffusion features with clean-image representations from self-supervised vision encoders, existing methods improve convergence and generation quality. However, such alignment also introduces a non-trivial constraint: diffusion models operate on noisy inputs whose usable information varies across timesteps, while the reference features are extracted from clean images. In this paper, we revisit this mismatch from a token-level perspective. We find that, under full-token representation alignment, tokens with large alignment-gradient norms exhibit a stable spatial preference, suggesting that the alignment objective does not affect all tokens uniformly and may encourage the model to rely on the complete set of clean-image tokens. To address this issue, we propose MaskAlign, a token-subset representation alignment method that applies alignment to randomly sampled token subsets during training. By exposing the model to different token subsets across iterations, MaskAlign reduces the dependence of representation alignment on the complete token set and encourages alignment behavior that is more stable under token-subset perturbations. To mitigate the information loss caused by directly dropping tokens, we further introduce a lightweight pre-mask token mixing block that shares information across tokens before masking.
Steering Visual Generation in Unified Multimodal Models with Understanding Supervision
May 07, 2026Unified multimodal models are envisioned to bridge the gap between understanding and generation. Yet, to achieve competitive performance, state-of-the-art models adopt largely decoupled understanding and generation components. This design, while effective for individual tasks, weakens the connection required for mutual enhancement, leaving the potential synergy empirically uncertain. We propose to explicitly restore this synergy by introducing Understanding-Oriented Post-Training (UNO), a lightweight framework that treats understanding not only as a distinct task, but also a direct supervisory signal to steer generative representations. By incorporating objectives that encode semantic abstraction (captioning) and structural details (visual regression), we enable effective gradient flow from understanding to generation. Extensive experiments on image generation and editing demonstrate that understanding can serve as an effective catalyst for generation.
ResTok: Learning Hierarchical Residuals in 1D Visual Tokenizers for Autoregressive Image Generation
Jan 07, 2026Existing 1D visual tokenizers for autoregressive (AR) generation largely follow the design principles of language modeling, as they are built directly upon transformers whose priors originate in language, yielding single-hierarchy latent tokens and treating visual data as flat sequential token streams. However, this language-like formulation overlooks key properties of vision, particularly the hierarchical and residual network designs that have long been essential for convergence and efficiency in visual models. To bring "vision" back to vision, we propose the Residual Tokenizer (ResTok), a 1D visual tokenizer that builds hierarchical residuals for both image tokens and latent tokens. The hierarchical representations obtained through progressively merging enable cross-level feature fusion at each layer, substantially enhancing representational capacity. Meanwhile, the semantic residuals between hierarchies prevent information overlap, yielding more concentrated latent distributions that are easier for AR modeling. Cross-level bindings consequently emerge without any explicit constraints. To accelerate the generation process, we further introduce a hierarchical AR generator that substantially reduces sampling steps by predicting an entire level of latent tokens at once rather than generating them strictly token-by-token. Extensive experiments demonstrate that restoring hierarchical residual priors in visual tokenization significantly improves AR image generation, achieving a gFID of 2.34 on ImageNet-256 with only 9 sampling steps. Code is available at https://github.com/Kwai-Kolors/ResTok.
Diffusion Model as a Noise-Aware Latent Reward Model for Step-Level Preference Optimization
Feb 03, 2025



Preference optimization for diffusion models aims to align them with human preferences for images. Previous methods typically leverage Vision-Language Models (VLMs) as pixel-level reward models to approximate human preferences. However, when used for step-level preference optimization, these models face challenges in handling noisy images of different timesteps and require complex transformations into pixel space. In this work, we demonstrate that diffusion models are inherently well-suited for step-level reward modeling in the latent space, as they can naturally extract features from noisy latent images. Accordingly, we propose the Latent Reward Model (LRM), which repurposes components of diffusion models to predict preferences of latent images at various timesteps. Building on LRM, we introduce Latent Preference Optimization (LPO), a method designed for step-level preference optimization directly in the latent space. Experimental results indicate that LPO not only significantly enhances performance in aligning diffusion models with general, aesthetic, and text-image alignment preferences, but also achieves 2.5-28$\times$ training speedup compared to existing preference optimization methods. Our code will be available at https://github.com/casiatao/LPO.
Vision Grid Transformer for Document Layout Analysis
Aug 29, 2023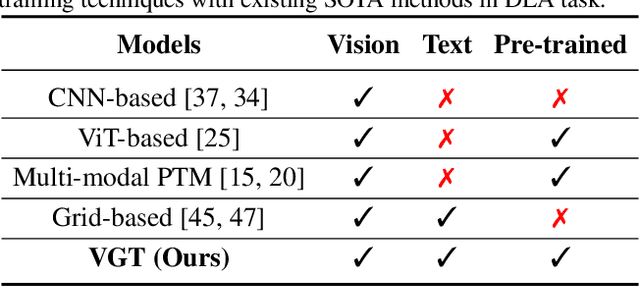



Document pre-trained models and grid-based models have proven to be very effective on various tasks in Document AI. However, for the document layout analysis (DLA) task, existing document pre-trained models, even those pre-trained in a multi-modal fashion, usually rely on either textual features or visual features. Grid-based models for DLA are multi-modality but largely neglect the effect of pre-training. To fully leverage multi-modal information and exploit pre-training techniques to learn better representation for DLA, in this paper, we present VGT, a two-stream Vision Grid Transformer, in which Grid Transformer (GiT) is proposed and pre-trained for 2D token-level and segment-level semantic understanding. Furthermore, a new dataset named D$^4$LA, which is so far the most diverse and detailed manually-annotated benchmark for document layout analysis, is curated and released. Experiment results have illustrated that the proposed VGT model achieves new state-of-the-art results on DLA tasks, e.g. PubLayNet ($95.7\%$$\rightarrow$$96.2\%$), DocBank ($79.6\%$$\rightarrow$$84.1\%$), and D$^4$LA ($67.7\%$$\rightarrow$$68.8\%$). The code and models as well as the D$^4$LA dataset will be made publicly available ~\url{https://github.com/AlibabaResearch/AdvancedLiterateMachinery}.
LISTER: Neighbor Decoding for Length-Insensitive Scene Text Recognition
Aug 24, 2023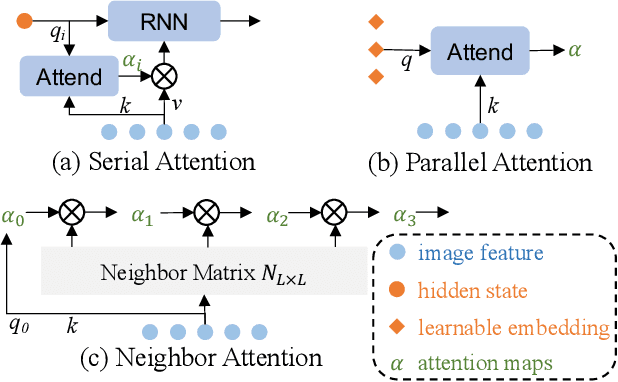
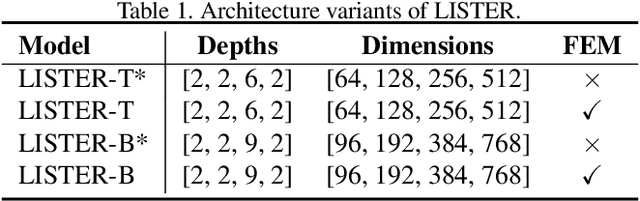
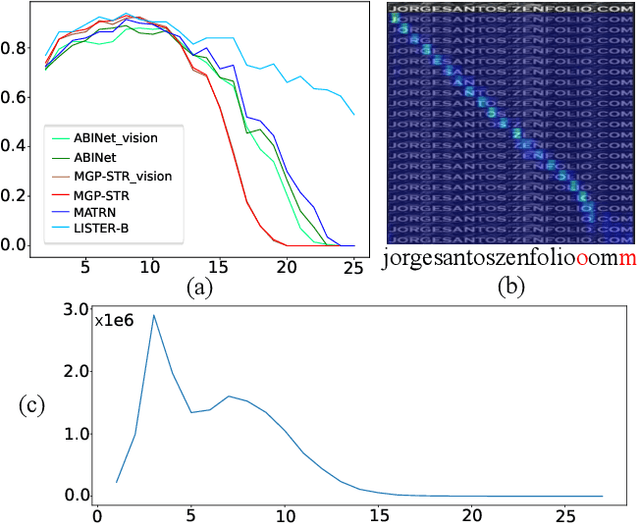
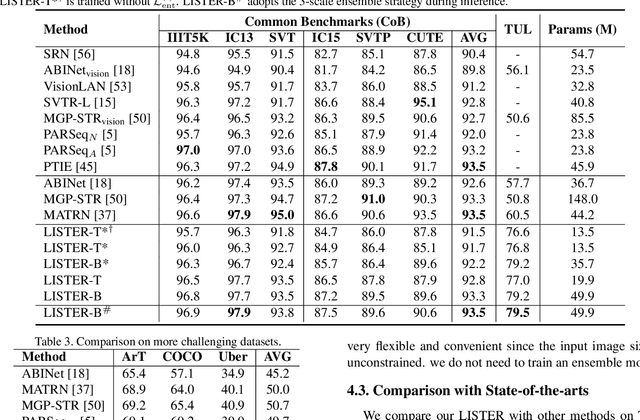
The diversity in length constitutes a significant characteristic of text. Due to the long-tail distribution of text lengths, most existing methods for scene text recognition (STR) only work well on short or seen-length text, lacking the capability of recognizing longer text or performing length extrapolation. This is a crucial issue, since the lengths of the text to be recognized are usually not given in advance in real-world applications, but it has not been adequately investigated in previous works. Therefore, we propose in this paper a method called Length-Insensitive Scene TExt Recognizer (LISTER), which remedies the limitation regarding the robustness to various text lengths. Specifically, a Neighbor Decoder is proposed to obtain accurate character attention maps with the assistance of a novel neighbor matrix regardless of the text lengths. Besides, a Feature Enhancement Module is devised to model the long-range dependency with low computation cost, which is able to perform iterations with the neighbor decoder to enhance the feature map progressively. To the best of our knowledge, we are the first to achieve effective length-insensitive scene text recognition. Extensive experiments demonstrate that the proposed LISTER algorithm exhibits obvious superiority on long text recognition and the ability for length extrapolation, while comparing favourably with the previous state-of-the-art methods on standard benchmarks for STR (mainly short text).
Multi-Granularity Prediction with Learnable Fusion for Scene Text Recognition
Jul 25, 2023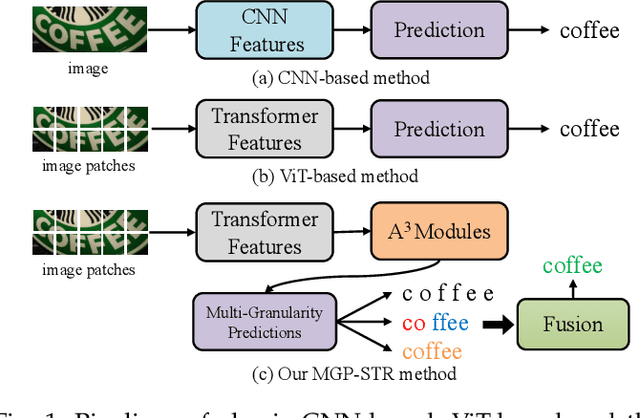



Due to the enormous technical challenges and wide range of applications, scene text recognition (STR) has been an active research topic in computer vision for years. To tackle this tough problem, numerous innovative methods have been successively proposed, and incorporating linguistic knowledge into STR models has recently become a prominent trend. In this work, we first draw inspiration from the recent progress in Vision Transformer (ViT) to construct a conceptually simple yet functionally powerful vision STR model, which is built upon ViT and a tailored Adaptive Addressing and Aggregation (A$^3$) module. It already outperforms most previous state-of-the-art models for scene text recognition, including both pure vision models and language-augmented methods. To integrate linguistic knowledge, we further propose a Multi-Granularity Prediction strategy to inject information from the language modality into the model in an implicit way, \ie, subword representations (BPE and WordPiece) widely used in NLP are introduced into the output space, in addition to the conventional character level representation, while no independent language model (LM) is adopted. To produce the final recognition results, two strategies for effectively fusing the multi-granularity predictions are devised. The resultant algorithm (termed MGP-STR) is able to push the performance envelope of STR to an even higher level. Specifically, MGP-STR achieves an average recognition accuracy of $94\%$ on standard benchmarks for scene text recognition. Moreover, it also achieves state-of-the-art results on widely-used handwritten benchmarks as well as more challenging scene text datasets, demonstrating the generality of the proposed MGP-STR algorithm. The source code and models will be available at: \url{https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/OCR/MGP-STR}.
Levenshtein OCR
Sep 08, 2022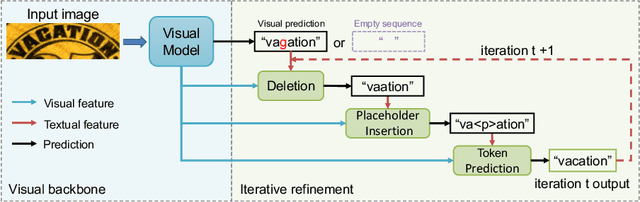
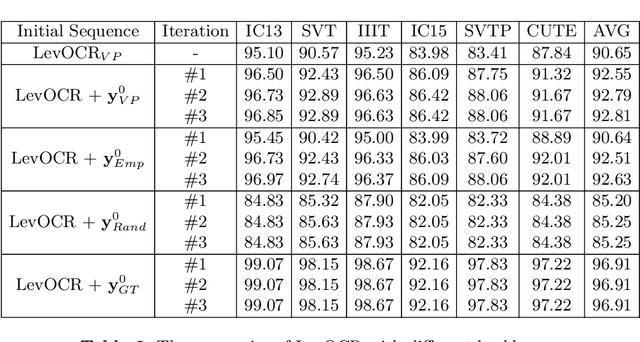
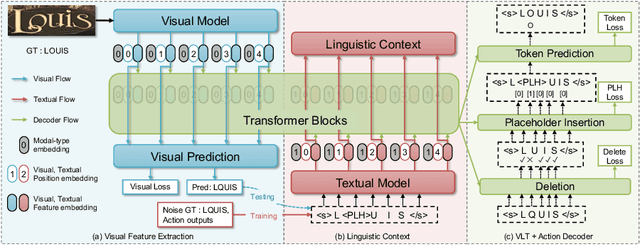
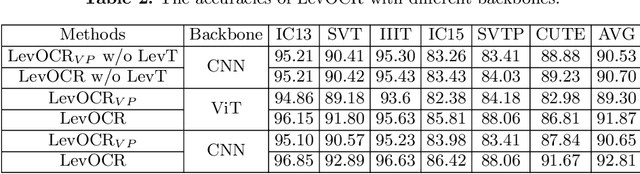
A novel scene text recognizer based on Vision-Language Transformer (VLT) is presented. Inspired by Levenshtein Transformer in the area of NLP, the proposed method (named Levenshtein OCR, and LevOCR for short) explores an alternative way for automatically transcribing textual content from cropped natural images. Specifically, we cast the problem of scene text recognition as an iterative sequence refinement process. The initial prediction sequence produced by a pure vision model is encoded and fed into a cross-modal transformer to interact and fuse with the visual features, to progressively approximate the ground truth. The refinement process is accomplished via two basic character-level operations: deletion and insertion, which are learned with imitation learning and allow for parallel decoding, dynamic length change and good interpretability. The quantitative experiments clearly demonstrate that LevOCR achieves state-of-the-art performances on standard benchmarks and the qualitative analyses verify the effectiveness and advantage of the proposed LevOCR algorithm. Code will be released soon.
Multi-Granularity Prediction for Scene Text Recognition
Sep 08, 2022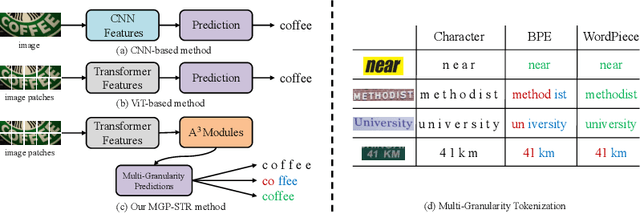
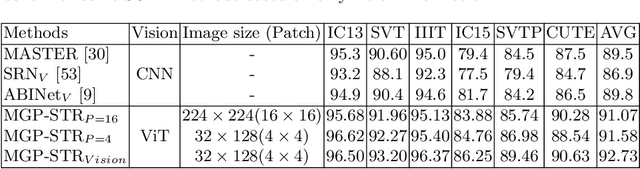
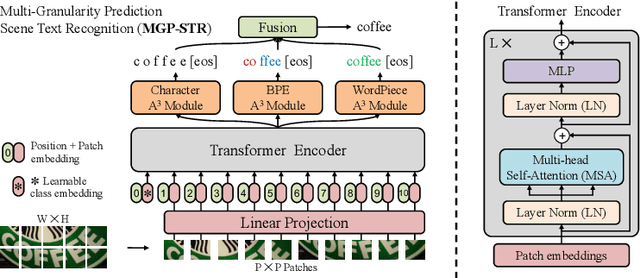

Scene text recognition (STR) has been an active research topic in computer vision for years. To tackle this challenging problem, numerous innovative methods have been successively proposed and incorporating linguistic knowledge into STR models has recently become a prominent trend. In this work, we first draw inspiration from the recent progress in Vision Transformer (ViT) to construct a conceptually simple yet powerful vision STR model, which is built upon ViT and outperforms previous state-of-the-art models for scene text recognition, including both pure vision models and language-augmented methods. To integrate linguistic knowledge, we further propose a Multi-Granularity Prediction strategy to inject information from the language modality into the model in an implicit way, i.e. , subword representations (BPE and WordPiece) widely-used in NLP are introduced into the output space, in addition to the conventional character level representation, while no independent language model (LM) is adopted. The resultant algorithm (termed MGP-STR) is able to push the performance envelop of STR to an even higher level. Specifically, it achieves an average recognition accuracy of 93.35% on standard benchmarks. Code will be released soon.
Fashion Focus: Multi-modal Retrieval System for Video Commodity Localization in E-commerce
Feb 09, 2021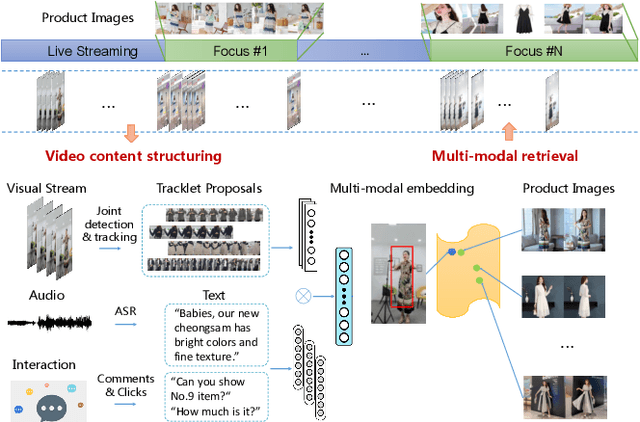

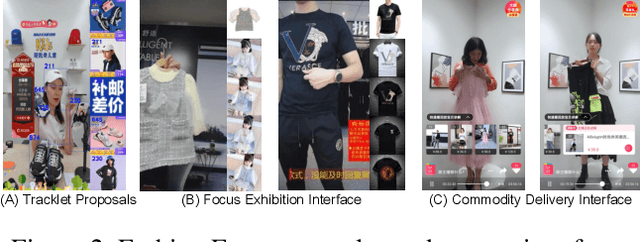
Nowadays, live-stream and short video shopping in E-commerce have grown exponentially. However, the sellers are required to manually match images of the selling products to the timestamp of exhibition in the untrimmed video, resulting in a complicated process. To solve the problem, we present an innovative demonstration of multi-modal retrieval system called "Fashion Focus", which enables to exactly localize the product images in the online video as the focuses. Different modality contributes to the community localization, including visual content, linguistic features and interaction context are jointly investigated via presented multi-modal learning. Our system employs two procedures for analysis, including video content structuring and multi-modal retrieval, to automatically achieve accurate video-to-shop matching. Fashion Focus presents a unified framework that can orientate the consumers towards relevant product exhibitions during watching videos and help the sellers to effectively deliver the products over search and recommendation.