 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cross Branch Fusion-Based Contrastive Learning Framework for Point Cloud Self-supervised Learning
May 30, 2025



Contrastive learning is an essential method in self-supervised learning. It primarily employs a multi-branch strategy to compare latent representations obtained from different branches and train the encoder. In the case of multi-modal input, diverse modalities of the same object are fed into distinct branches. When using single-modal data, the same input undergoes various augmentations before being fed into different branches. However, all existing contrastive learning frameworks have so far only performed contrastive operations on the learned features at the final loss end, with no information exchange between different branches prior to this stage. In this paper, for point cloud unsupervised learning without the use of extra training data, we propose a Contrastive Cross-branch Attention-based framework for Point cloud data (termed PoCCA), to learn rich 3D point cloud representations. By introducing sub-branches, PoCCA allows information exchange between different branches before the loss end. Experimental results demonstrate that in the case of using no extra training data, the representations learned with our self-supervised model achieve state-of-the-art performances when used for downstream tasks on point clouds.
Diffusion Model as a Noise-Aware Latent Reward Model for Step-Level Preference Optimization
Feb 03, 2025



Preference optimization for diffusion models aims to align them with human preferences for images. Previous methods typically leverage Vision-Language Models (VLMs) as pixel-level reward models to approximate human preferences. However, when used for step-level preference optimization, these models face challenges in handling noisy images of different timesteps and require complex transformations into pixel space. In this work, we demonstrate that diffusion models are inherently well-suited for step-level reward modeling in the latent space, as they can naturally extract features from noisy latent images. Accordingly, we propose the Latent Reward Model (LRM), which repurposes components of diffusion models to predict preferences of latent images at various timesteps. Building on LRM, we introduce Latent Preference Optimization (LPO), a method designed for step-level preference optimization directly in the latent space. Experimental results indicate that LPO not only significantly enhances performance in aligning diffusion models with general, aesthetic, and text-image alignment preferences, but also achieves 2.5-28$\times$ training speedup compared to existing preference optimization methods. Our code will be available at https://github.com/casiatao/LPO.
User-Creator Feature Dynamics in Recommender Systems with Dual Influence
Jul 19, 2024



Recommender systems present relevant contents to users and help content creators reach their target audience. The dual nature of these systems influences both users and creators: users' preferences are affected by the items they are recommended, while creators are incentivized to alter their contents such that it is recommended more frequently. We define a model, called user-creator feature dynamics, to capture the dual influences of recommender systems. We prove that a recommender system with dual influence is guaranteed to polarize, causing diversity loss in the system. We then investigate, both theoretically and empirically, approaches for mitigating polarization and promoting diversity in recommender systems. Unexpectedly, we find that common diversity-promoting approaches do not work in the presence of dual influence, while relevancy-optimizing methods like top-$k$ recommendation can prevent polarization and improve diversity of the system.
Consistency Purification: Effective and Efficient Diffusion Purification towards Certified Robustness
Jun 30, 2024

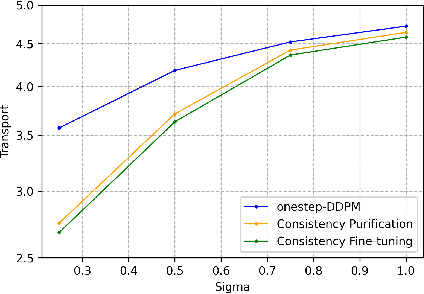

Diffusion Purification, purifying noised images with diffusion models, has been widely used for enhancing certified robustness via randomized smoothing. However, existing frameworks often grapple with the balance between efficiency and effectiveness. While the Denoising Diffusion Probabilistic Model (DDPM) offers an efficient single-step purification, it falls short in ensuring purified images reside on the data manifold. Conversely, the Stochastic Diffusion Model effectively places purified images on the data manifold but demands solving cumbersome stochastic differential equations, while its derivative, the Probability Flow Ordinary Differential Equation (PF-ODE), though solving simpler ordinary differential equations, still requires multiple computational steps. In this work, we demonstrated that an ideal purification pipeline should generate the purified images on the data manifold that are as much semantically aligned to the original images for effectiveness in one step for efficiency. Therefore, we introduced Consistency Purification, an efficiency-effectiveness Pareto superior purifier compared to the previous work. Consistency Purification employs the consistency model, a one-step generative model distilled from PF-ODE, thus can generate on-manifold purified images with a single network evaluation. However, the consistency model is designed not for purification thus it does not inherently ensure semantic alignment between purified and original images. To resolve this issue, we further refine it through Consistency Fine-tuning with LPIPS loss, which enables more aligned semantic meaning while keeping the purified images on data manifold. Our comprehensive experiments demonstrate that our Consistency Purification framework achieves state-of the-art certified robustness and efficiency compared to baseline methods.
Addressing Polarization and Unfairness in Performative Prediction
Jun 24, 2024
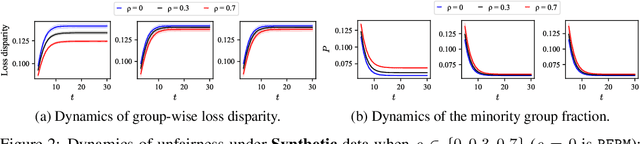
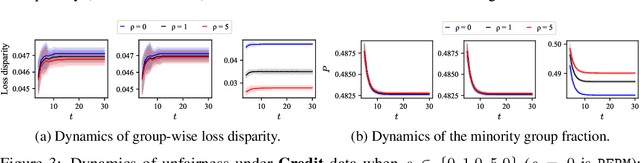
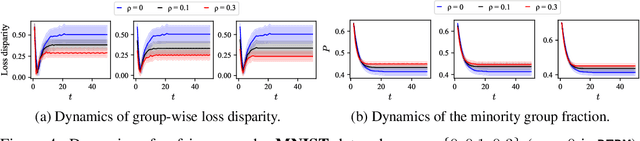
When machine learning (ML) models are used in applications that involve humans (e.g., online recommendation, school admission, hiring, lending), the model itself may trigger changes in the distribution of targeted data it aims to predict. Performative prediction (PP) is a framework that explicitly considers such model-dependent distribution shifts when learning ML models. While significant efforts have been devoted to finding performative stable (PS) solutions in PP for system robustness, their societal implications are less explored and it is unclear whether PS solutions are aligned with social norms such as fairness. In this paper, we set out to examine the fairness property of PS solutions in performative prediction. We first show that PS solutions can incur severe polarization effects and group-wise loss disparity. Although existing fairness mechanisms commonly used in literature can help mitigate unfairness, they may fail and disrupt the stability under model-dependent distribution shifts. We thus propose novel fairness intervention mechanisms that can simultaneously achieve both stability and fairness in PP settings. Both theoretical analysis and experiments are provided to validate the proposed method.
Measuring Fairness in Large-Scale Recommendation Systems with Missing Labels
Jun 07, 2024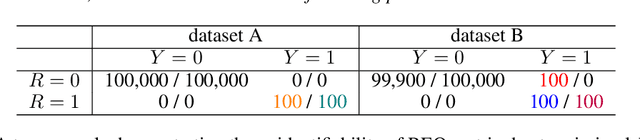

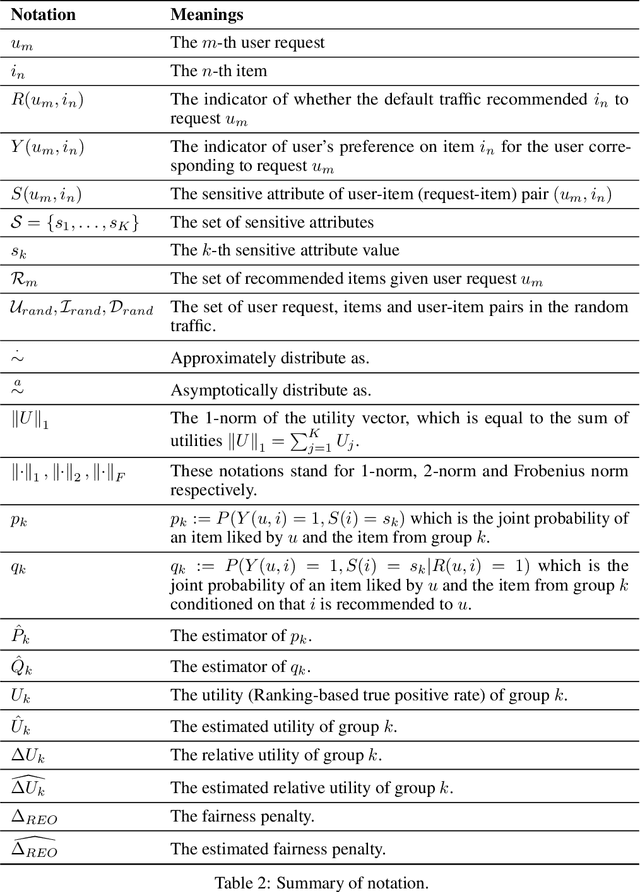
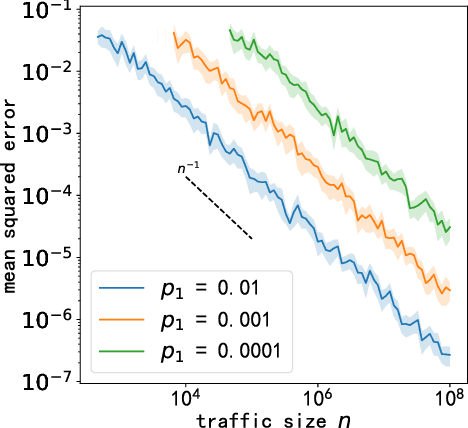
In large-scale recommendation systems, the vast array of items makes it infeasible to obtain accurate user preferences for each product, resulting in a common issue of missing labels. Typically, only items previously recommended to users have associated ground truth data. Although there is extensive research on fairness concerning fully observed user-item interactions, the challenge of fairness in scenarios with missing labels remains underexplored. Previous methods often treat these samples missing labels as negative, which can significantly deviate from the ground truth fairness metrics. Our study addresses this gap by proposing a novel method employing a small randomized traffic to estimate fairness metrics accurately. We present theoretical bounds for the estimation error of our fairness metric and support our findings with empirical evidence on real data. Our numerical experiments on synthetic and TikTok's real-world data validate our theory and show the efficiency and effectiveness of our novel methods. To the best of our knowledge, we are the first to emphasize the necessity of random traffic in dataset collection for recommendation fairness, the first to publish a fairness-related dataset from TikTok and to provide reliable estimates of fairness metrics in the context of large-scale recommendation systems with missing labels.
Professional Basketball Player Behavior Synthesis via Planning with Diffusion
Jun 10, 2023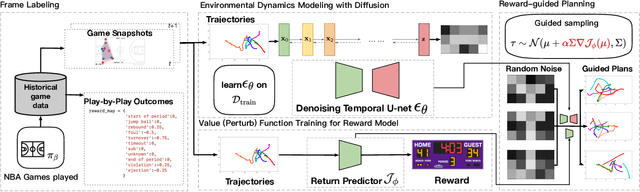
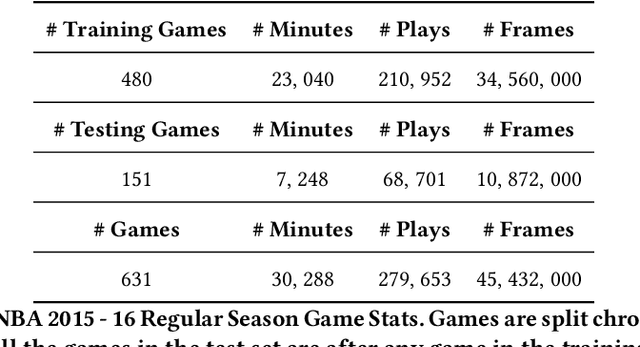
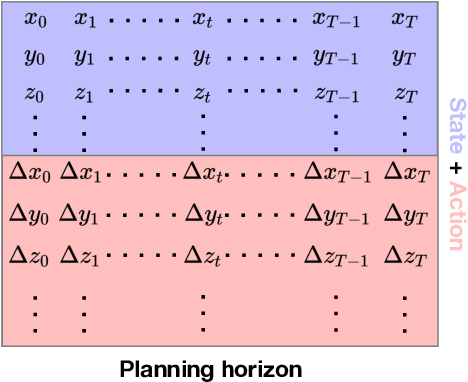

Dynamically planning in multi-agent systems has been explored to improve decision-making in various domains. Professional basketball serves as a compelling example of a dynamic spatio-temporal game, encompassing both concealed strategic policies and decision-making. However, processing the diverse on-court signals and navigating the vast space of potential actions and outcomes makes it difficult for existing approaches to swiftly identify optimal strategies in response to evolving circumstances. In this study, we first formulate the sequential decision-making process as a conditional trajectory generation process. We further introduce PLAYBEST (PLAYer BEhavior SynThesis), a method for enhancing player decision-making. We extend the state-of-the-art generative model, diffusion probabilistic model, to learn challenging multi-agent environmental dynamics from historical National Basketball Association (NBA) player motion tracking data. To incorporate data-driven strategies, an auxiliary value function is trained using the play-by-play data with corresponding rewards acting as the plan guidance. To accomplish reward-guided trajectory generation, conditional sampling is introduced to condition the diffusion model on the value function and conduct classifier-guided sampling. We validate the effectiveness of PLAYBEST via comprehensive simulation studies from real-world data, contrasting the generated trajectories and play strategies with those employed by professional basketball teams. Our results reveal that the model excels at generating high-quality basketball trajectories that yield efficient plays, surpassing conventional planning techniques in terms of adaptability, flexibility, and overall performance. Moreover, the synthesized play strategies exhibit a remarkable alignment with professional tactics, highlighting the model's capacity to capture the intricate dynamics of basketball games.
Performative Federated Learning: A Solution to Model-Dependent and Heterogeneous Distribution Shifts
May 08, 2023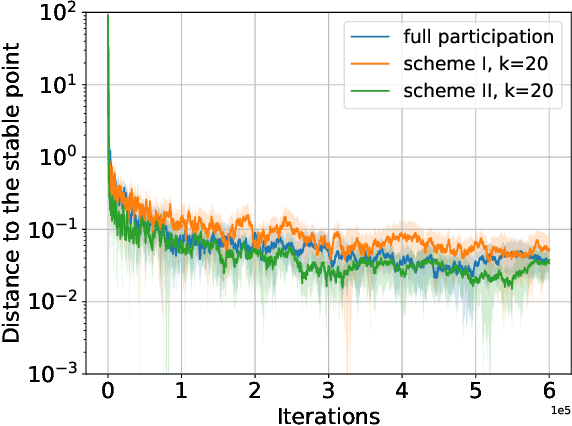
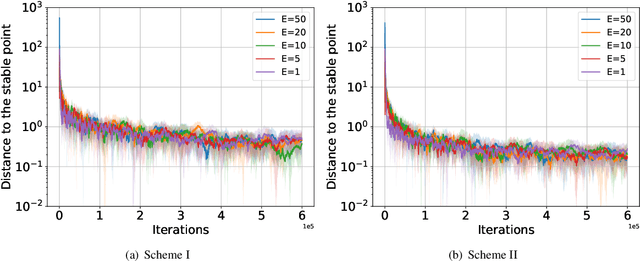
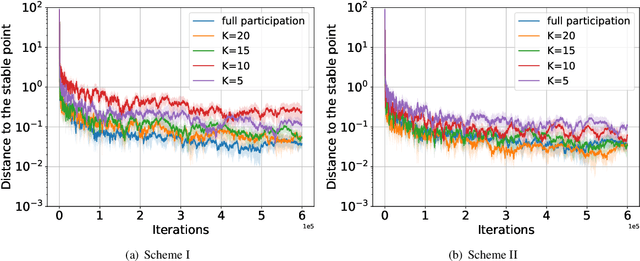
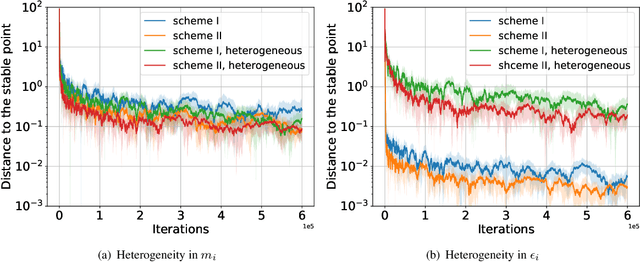
We consider a federated learning (FL) system consisting of multiple clients and a server, where the clients aim to collaboratively learn a common decision model from their distributed data. Unlike the conventional FL framework that assumes the client's data is static, we consider scenarios where the clients' data distributions may be reshaped by the deployed decision model. In this work, we leverage the idea of distribution shift mappings in performative prediction to formalize this model-dependent data distribution shift and propose a performative federated learning framework. We first introduce necessary and sufficient conditions for the existence of a unique performative stable solution and characterize its distance to the performative optimal solution. Then we propose the performative FedAvg algorithm and show that it converges to the performative stable solution at a rate of O(1/T) under both full and partial participation schemes. In particular, we use novel proof techniques and show how the clients' heterogeneity influences the convergence. Numerical results validate our analysis and provide valuable insights into real-world applications.
DensePure: Understanding Diffusion Models towards Adversarial Robustness
Nov 01, 2022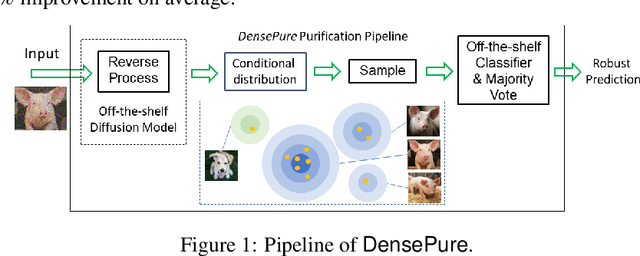
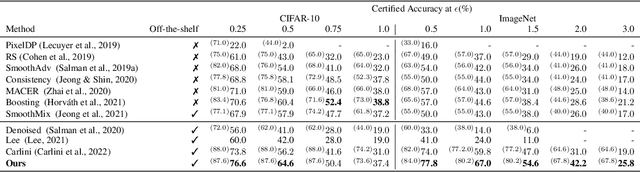
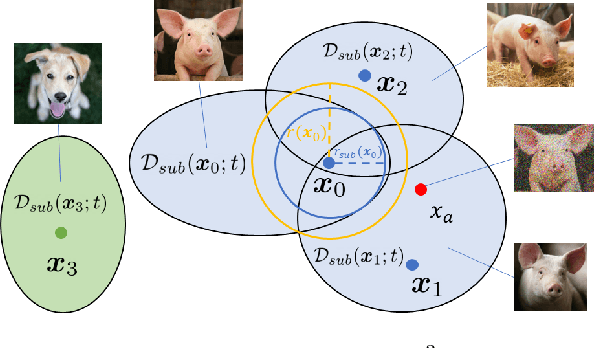

Diffusion models have been recently employed to improve certified robustness through the process of denoising. However, the theoretical understanding of why diffusion models are able to improve the certified robustness is still lacking, preventing from further improvement. In this study, we close this gap by analyzing the fundamental properties of diffusion models and establishing the conditions under which they can enhance certified robustness. This deeper understanding allows us to propose a new method DensePure, designed to improve the certified robustness of a pretrained model (i.e. classifier). Given an (adversarial) input, DensePure consists of multiple runs of denoising via the reverse process of the diffusion model (with different random seeds) to get multiple reversed samples, which are then passed through the classifier, followed by majority voting of inferred labels to make the final prediction. This design of using multiple runs of denoising is informed by our theoretical analysis of the conditional distribution of the reversed sample. Specifically, when the data density of a clean sample is high, its conditional density under the reverse process in a diffusion model is also high; thus sampling from the latter conditional distribution can purify the adversarial example and return the corresponding clean sample with a high probability. By using the highest density point in the conditional distribution as the reversed sample, we identify the robust region of a given instance under the diffusion model's reverse process. We show that this robust region is a union of multiple convex sets, and is potentially much larger than the robust regions identified in previous works. In practice, DensePure can approximate the label of the high density region in the conditional distribution so that it can enhance certified robustness.
The Gaussian Transform
Jun 21, 2020
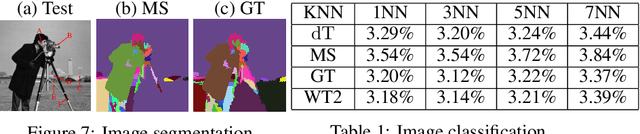
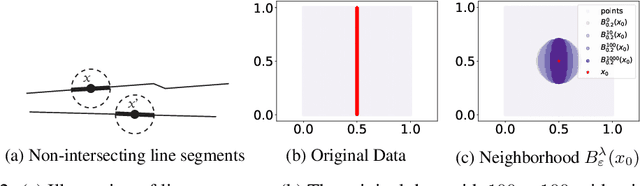
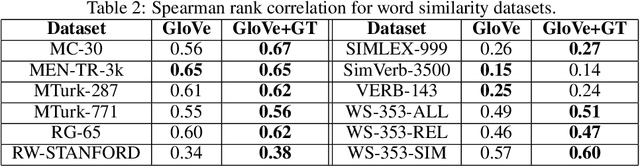
We introduce the Gaussian transform (GT), an optimal transport inspired iterative method for denoising and enhancing latent structures in datasets. Under the hood, GT generates a new distance function (GT distance) on a given dataset by computing the $\ell^2$-Wasserstein distance between certain Gaussian density estimates obtained by localizing the dataset to individual points. Our contribution is twofold: (1) theoretically, we establish firstly that GT is stable under perturbations and secondly that in the continuous case, each point possesses an asymptotically ellipsoidal neighborhood with respect to the GT distance; (2) computationally, we accelerate GT both by identifying a strategy for reducing the number of matrix square root computations inherent to the $\ell^2$-Wasserstein distance between Gaussian measures, and by avoiding redundant computations of GT distances between points via enhanced neighborhood mechanisms. We also observe that GT is both a generalization and a strengthening of the mean shift (MS) method, and it is also a computationally efficient specialization of the recently proposed Wasserstein Transform (WT) method. We perform extensive experimentation comparing their performance in different scenarios.