 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Cross Branch Fusion-Based Contrastive Learning Framework for Point Cloud Self-supervised Learning
May 30, 2025Contrastive learning is an essential method in self-supervised learning. It primarily employs a multi-branch strategy to compare latent representations obtained from different branches and train the encoder. In the case of multi-modal input, diverse modalities of the same object are fed into distinct branches. When using single-modal data, the same input undergoes various augmentations before being fed into different branches. However, all existing contrastive learning frameworks have so far only performed contrastive operations on the learned features at the final loss end, with no information exchange between different branches prior to this stage. In this paper, for point cloud unsupervised learning without the use of extra training data, we propose a Contrastive Cross-branch Attention-based framework for Point cloud data (termed PoCCA), to learn rich 3D point cloud representations. By introducing sub-branches, PoCCA allows information exchange between different branches before the loss end. Experimental results demonstrate that in the case of using no extra training data, the representations learned with our self-supervised model achieve state-of-the-art performances when used for downstream tasks on point clouds.
6D Pose Estimation on Point Cloud Data through Prior Knowledge Integration: A Case Study in Autonomous Disassembly
May 30, 2025The accurate estimation of 6D pose remains a challenging task within the computer vision domain, even when utilizing 3D point cloud data. Conversely, in the manufacturing domain, instances arise where leveraging prior knowledge can yield advancements in this endeavor. This study focuses on the disassembly of starter motors to augment the engineering of product life cycles. A pivotal objective in this context involves the identification and 6D pose estimation of bolts affixed to the motors, facilitating automated disassembly within the manufacturing workflow. Complicating matters, the presence of occlusions and the limitations of single-view data acquisition, notably when motors are placed in a clamping system, obscure certain portions and render some bolts imperceptible. Consequently, the development of a comprehensive pipeline capable of acquiring complete bolt information is imperative to avoid oversight in bolt detection. In this paper, employing the task of bolt detection within the scope of our project as a pertinent use case, we introduce a meticulously devised pipeline. This multi-stage pipeline effectively captures the 6D information with regard to all bolts on the motor, thereby showcasing the effective utilization of prior knowledge in handling this challenging task. The proposed methodology not only contributes to the field of 6D pose estimation but also underscores the viability of integrating domain-specific insights to tackle complex problems in manufacturing and automation.
SAMBLE: Shape-Specific Point Cloud Sampling for an Optimal Trade-Off Between Local Detail and Global Uniformity
Apr 28, 2025Driven by the increasing demand for accurate and efficient representation of 3D data in various domains, point cloud sampling has emerged as a pivotal research topic in 3D computer vision. Recently, learning-to-sample methods have garnered growing interest from the community, particularly for their ability to be jointly trained with downstream tasks. However, previous learning-based sampling methods either lead to unrecognizable sampling patterns by generating a new point cloud or biased sampled results by focusing excessively on sharp edge details. Moreover, they all overlook the natural variations in point distribution across different shapes, applying a similar sampling strategy to all point clouds. In this paper, we propose a Sparse Attention Map and Bin-based Learning method (termed SAMBLE) to learn shape-specific sampling strategies for point cloud shapes. SAMBLE effectively achieves an improved balance between sampling edge points for local details and preserving uniformity in the global shape, resulting in superior performance across multiple common point cloud downstream tasks, even in scenarios with few-point sampling.
Rethinking Attention Module Design for Point Cloud Analysis
Jul 27, 2024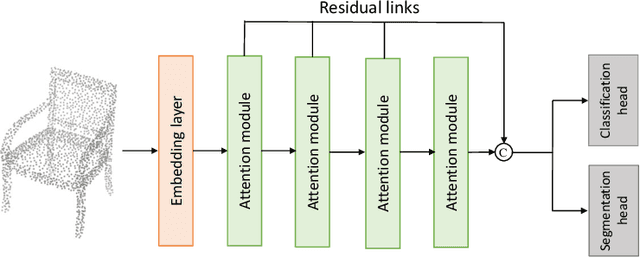
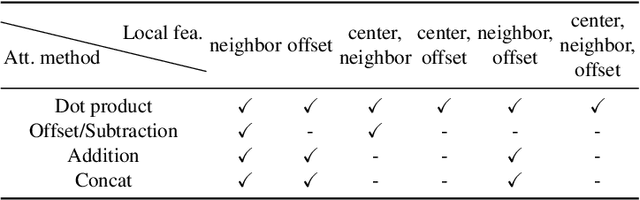
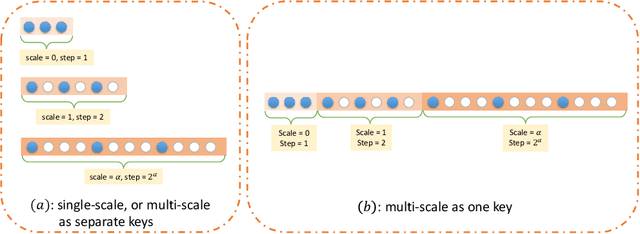

In recent years, there have been significant advancements in applying attention mechanisms to point cloud analysis. However, attention module variants featured in various research papers often operate under diverse settings and tasks, incorporating potential training strategies. This heterogeneity poses challenges in establishing a fair comparison among these attention module variants. In this paper, we address this issue by rethinking and exploring attention module design within a consistent base framework and settings. Both global-based and local-based attention methods are studied, with a focus on the selection basis and scales of neighbors for local-based attention. Different combinations of aggregated local features and computation methods for attention scores are evaluated, ranging from the initial addition/concatenation-based approach to the widely adopted dot product-based method and the recently proposed vector attention technique. Various position encoding methods are also investigated. Our extensive experimental analysis reveals that there is no universally optimal design across diverse point cloud tasks. Instead, drawing from best practices, we propose tailored attention modules for specific tasks, leading to superior performance on point cloud classification and segmentation benchmarks.
Open Panoramic Segmentation
Jul 02, 2024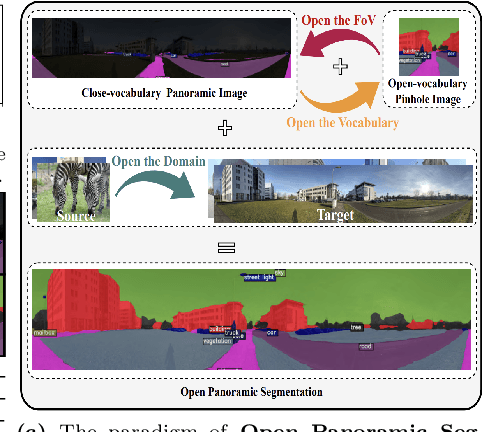
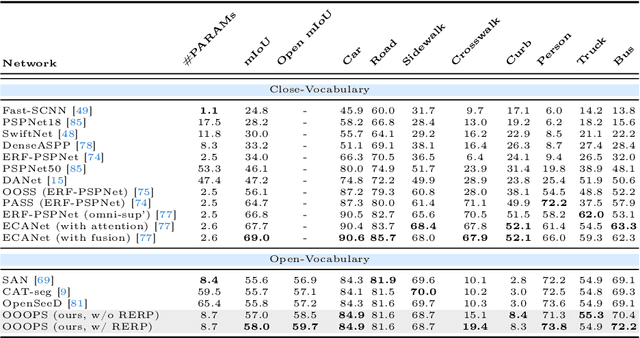
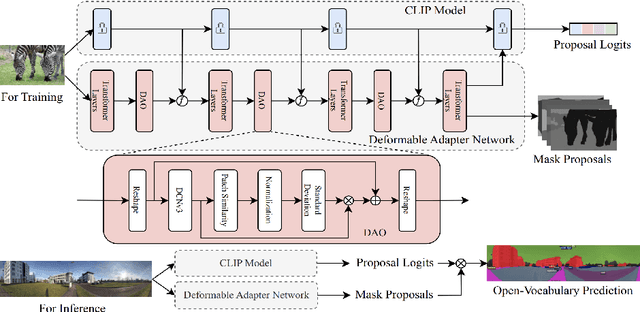

Panoramic images, capturing a 360{\deg} field of view (FoV), encompass omnidirectional spatial information crucial for scene understanding. However, it is not only costly to obtain training-sufficient dense-annotated panoramas but also application-restricted when training models in a close-vocabulary setting. To tackle this problem, in this work, we define a new task termed Open Panoramic Segmentation (OPS), where models are trained with FoV-restricted pinhole images in the source domain in an open-vocabulary setting while evaluated with FoV-open panoramic images in the target domain, enabling the zero-shot open panoramic semantic segmentation ability of models. Moreover, we propose a model named OOOPS with a Deformable Adapter Network (DAN), which significantly improves zero-shot panoramic semantic segmentation performance. To further enhance the distortion-aware modeling ability from the pinhole source domain, we propose a novel data augmentation method called Random Equirectangular Projection (RERP) which is specifically designed to address object deformations in advance. Surpassing other state-of-the-art open-vocabulary semantic segmentation approaches, a remarkable performance boost on three panoramic datasets, WildPASS, Stanford2D3D, and Matterport3D, proves the effectiveness of our proposed OOOPS model with RERP on the OPS task, especially +2.2% on outdoor WildPASS and +2.4% mIoU on indoor Stanford2D3D. The code will be available at https://junweizheng93.github.io/publications/OPS/OPS.html.
DiffAnt: Diffusion Models for Action Anticipation
Nov 27, 2023Anticipating future actions is inherently uncertain. Given an observed video segment containing ongoing actions, multiple subsequent actions can plausibly follow. This uncertainty becomes even larger when predicting far into the future. However, the majority of existing action anticipation models adhere to a deterministic approach, neglecting to account for future uncertainties. In this work, we rethink action anticipation from a generative view, employing diffusion models to capture different possible future actions. In this framework, future actions are iteratively generated from standard Gaussian noise in the latent space, conditioned on the observed video, and subsequently transitioned into the action space. Extensive experiments on four benchmark datasets, i.e., Breakfast, 50Salads, EpicKitchens, and EGTEA Gaze+, are performed and the proposed method achieves superior or comparable results to state-of-the-art methods, showing the effectiveness of a generative approach for action anticipation. Our code and trained models will be published on GitHub.
Attention-based Part Assembly for 3D Volumetric Shape Modeling
Apr 17, 2023Modeling a 3D volumetric shape as an assembly of decomposed shape parts is much more challenging, but semantically more valuable than direct reconstruction from a full shape representation. The neural network needs to implicitly learn part relations coherently, which is typically performed by dedicated network layers that can generate transformation matrices for each part. In this paper, we propose a VoxAttention network architecture for attention-based part assembly. We further propose a variant of using channel-wise part attention and show the advantages of this approach. Experimental results show that our method outperforms most state-of-the-art methods for the part relation-aware 3D shape modeling task.
Attention-based Point Cloud Edge Sampling
Feb 28, 2023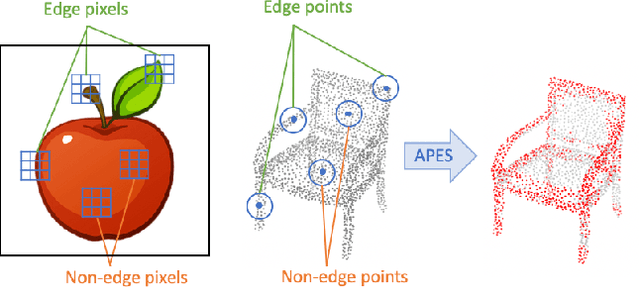



Point cloud sampling is a less explored research topic for this data representation. The most common sampling methods nowadays are still classical random sampling and farthest point sampling. With the development of neural networks, various methods have been proposed to sample point clouds in a task-based learning manner. However, these methods are mostly generative-based, other than selecting points directly with mathematical statistics. Inspired by the Canny edge detection algorithm for images and with the help of the attention mechanism, this paper proposes a non-generative Attention-based Point cloud Edge Sampling method (APES), which can capture the outline of input point clouds. Experimental results show that better performances are achieved with our sampling method due to the important outline information it learned.
Sim2real Transfer Learning for Point Cloud Segmentation: An Industrial Application Case on Autonomous Disassembly
Jan 12, 2023



On robotics computer vision tasks, generating and annotating large amounts of data from real-world for the use of deep learning-based approaches is often difficult or even impossible. A common strategy for solving this problem is to apply simulation-to-reality (sim2real) approaches with the help of simulated scenes. While the majority of current robotics vision sim2real work focuses on image data, we present an industrial application case that uses sim2real transfer learning for point cloud data. We provide insights on how to generate and process synthetic point cloud data in order to achieve better performance when the learned model is transferred to real-world data. The issue of imbalanced learning is investigated using multiple strategies. A novel patch-based attention network is proposed additionally to tackle this problem.
SynMotor: A Benchmark Suite for Object Attribute Regression and Multi-task Learning
Jan 11, 2023In this paper, we develop a novel benchmark suite including both a 2D synthetic image dataset and a 3D synthetic point cloud dataset. Our work is a sub-task in the framework of a remanufacturing project, in which small electric motors are used as fundamental objects. Apart from the given detection, classification, and segmentation annotations, the key objects also have multiple learnable attributes with ground truth provided. This benchmark can be used for computer vision tasks including 2D/3D detection, classification, segmentation, and multi-attribute learning. It is worth mentioning that most attributes of the motors are quantified as continuously variable rather than binary, which makes our benchmark well-suited for the less explored regression tasks. In addition, appropriate evaluation metrics are adopted or developed for each task and promising baseline results are provided. We hope this benchmark can stimulate more research efforts on the sub-domain of object attribute learning and multi-task learning in the future.