 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative-Contrastive Learning for Self-Supervised Latent Representations of 3D Shapes from Multi-Modal Euclidean Input
Paper and Code
Jan 11, 2023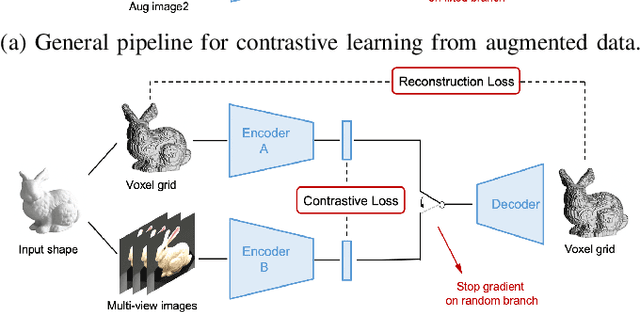
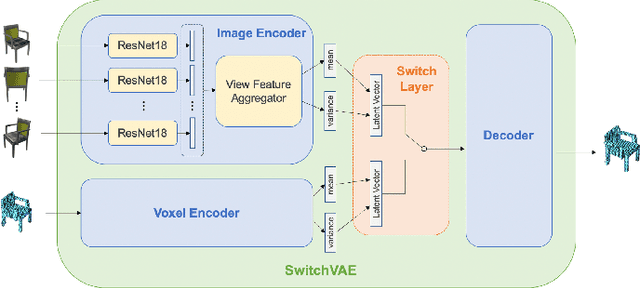

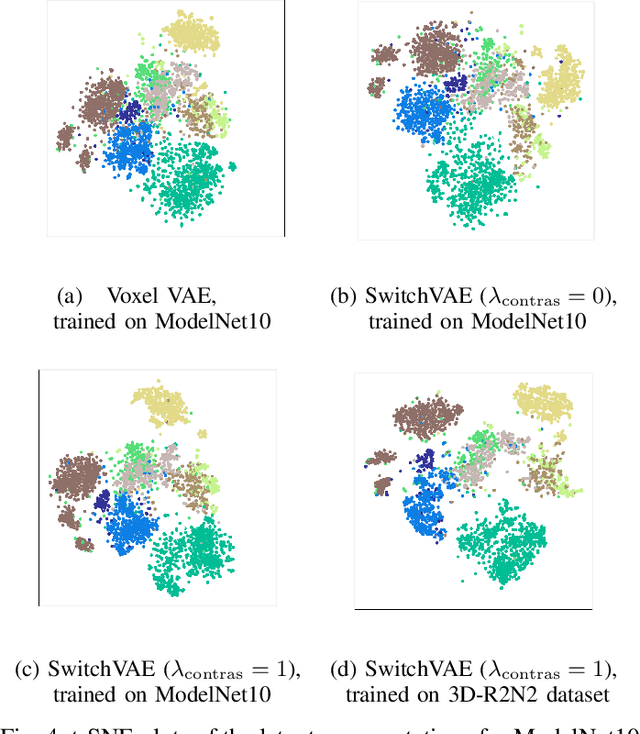
We propose a combined generative and contrastive neural architecture for learning latent representations of 3D volumetric shapes. The architecture uses two encoder branches for voxel grids and multi-view images from the same underlying shape. The main idea is to combine a contrastive loss between the resulting latent representations with an additional reconstruction loss. That helps to avoid collapsing the latent representations as a trivial solution for minimizing the contrastive loss. A novel switching scheme is used to cross-train two encoders with a shared decoder. The switching scheme also enables the stop gradient operation on a random branch. Further classification experiments show that the latent representations learned with our self-supervised method integrate more useful information from the additional input data implicitly, thus leading to better reconstruction and classification performance.