 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Attention Module Design for Point Cloud Analysis
Jul 27, 2024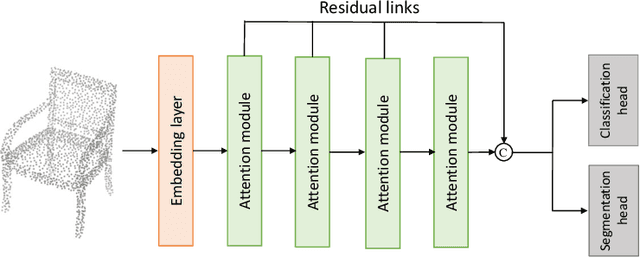
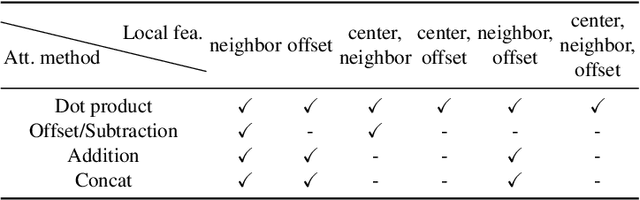
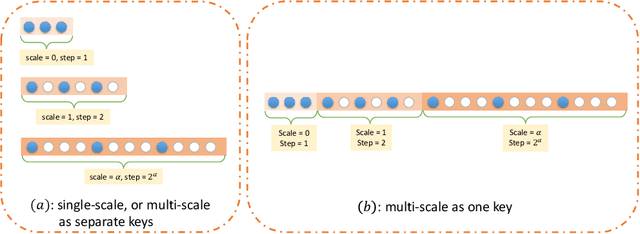

In recent years, there have been significant advancements in applying attention mechanisms to point cloud analysis. However, attention module variants featured in various research papers often operate under diverse settings and tasks, incorporating potential training strategies. This heterogeneity poses challenges in establishing a fair comparison among these attention module variants. In this paper, we address this issue by rethinking and exploring attention module design within a consistent base framework and settings. Both global-based and local-based attention methods are studied, with a focus on the selection basis and scales of neighbors for local-based attention. Different combinations of aggregated local features and computation methods for attention scores are evaluated, ranging from the initial addition/concatenation-based approach to the widely adopted dot product-based method and the recently proposed vector attention technique. Various position encoding methods are also investigated. Our extensive experimental analysis reveals that there is no universally optimal design across diverse point cloud tasks. Instead, drawing from best practices, we propose tailored attention modules for specific tasks, leading to superior performance on point cloud classification and segmentation benchmarks.
An End-to-End Cascaded Image Deraining and Object Detection Neural Network
Feb 23, 2022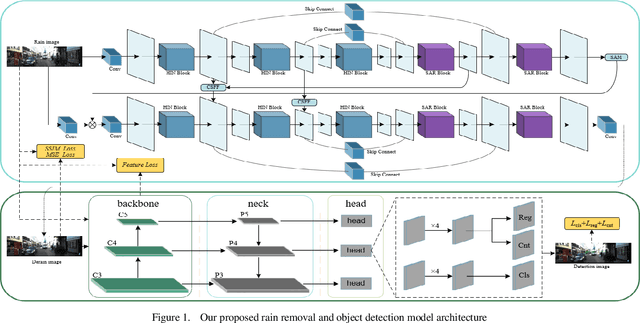
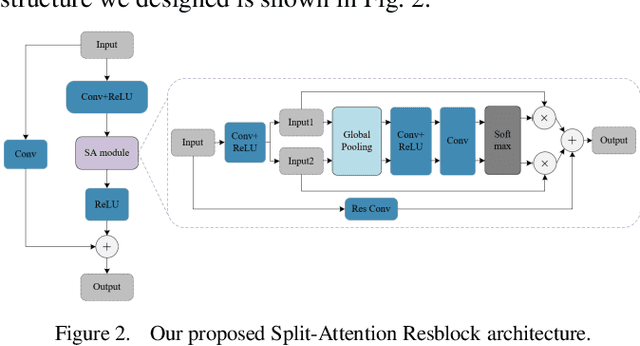

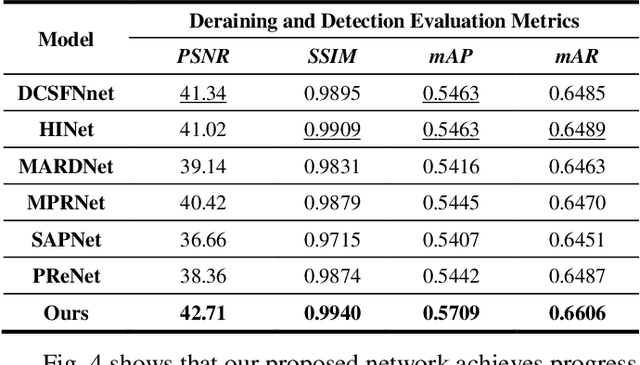
While the deep learning-based image deraining methods have made great progress in recent years, there are two major shortcomings in their application in real-world situations. Firstly, the gap between the low-level vision task represented by rain removal and the high-level vision task represented by object detection is significant, and the low-level vision task can hardly contribute to the high-level vision task. Secondly, the quality of the deraining dataset needs to be improved. In fact, the rain lines in many baselines have a large gap with the real rain lines, and the resolution of the deraining dataset images is generally not ideally. Meanwhile, there are few common datasets for both the low-level vision task and the high-level vision task. In this paper, we explore the combination of the low-level vision task with the high-level vision task. Specifically, we propose an end-to-end object detection network for reducing the impact of rainfall, which consists of two cascaded networks, an improved image deraining network and an object detection network, respectively. We also design the components of the loss function to accommodate the characteristics of the different sub-networks. We then propose a dataset based on the KITTI dataset for rainfall removal and object detection, on which our network surpasses the state-of-the-art with a significant improvement in metrics. Besides, our proposed network is measured on driving videos collected by self-driving vehicles and shows positive results for rain removal and object detection.
Super-resolution reconstruction of cytoskeleton image based on A-net deep learning network
Dec 17, 2021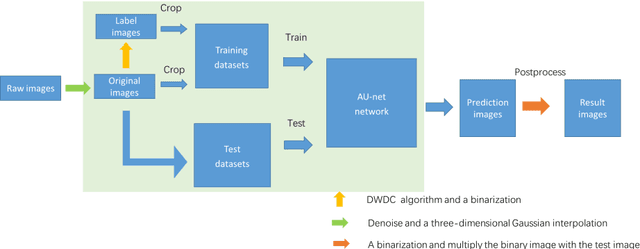
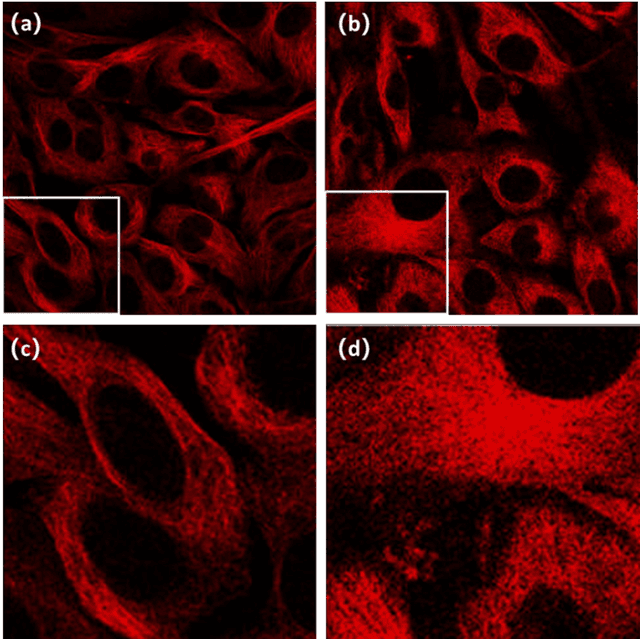
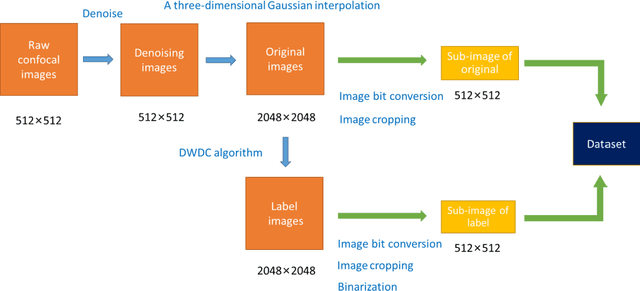
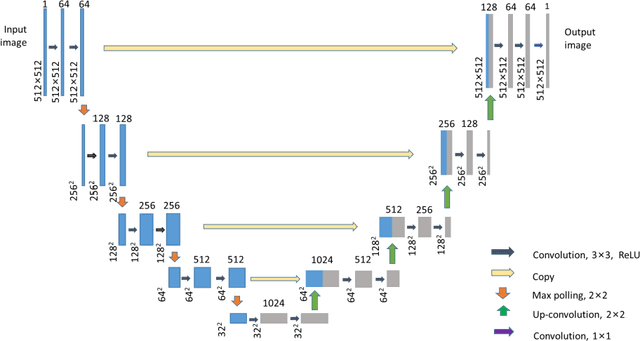
To date, live-cell imaging at the nanometer scale remains challenging. Even though super-resolution microscopy methods have enabled visualization of subcellular structures below the optical resolution limit, the spatial resolution is still far from enough for the structural reconstruction of biomolecules in vivo (i.e. ~24 nm thickness of microtubule fiber). In this study, we proposed an A-net network and showed that the resolution of cytoskeleton images captured by a confocal microscope can be significantly improved by combining the A-net deep learning network with the DWDC algorithm based on degradation model. Utilizing the DWDC algorithm to construct new datasets and taking advantage of A-net neural network's features (i.e., considerably fewer layers), we successfully removed the noise and flocculent structures, which originally interfere with the cellular structure in the raw image, and improved the spatial resolution by 10 times using relatively small dataset. We, therefore, conclude that the proposed algorithm that combines A-net neural network with the DWDC method is a suitable and universal approach for exacting structural details of biomolecules, cells and organs from low-resolution images.
Image Deraining Convolutional Neural Network ForAutonomous Driving
Sep 15, 2021
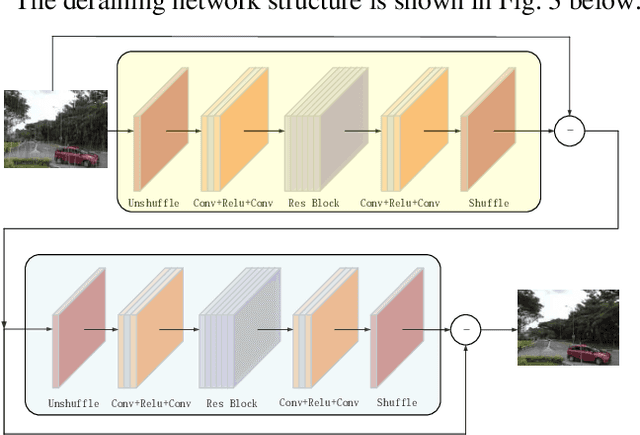
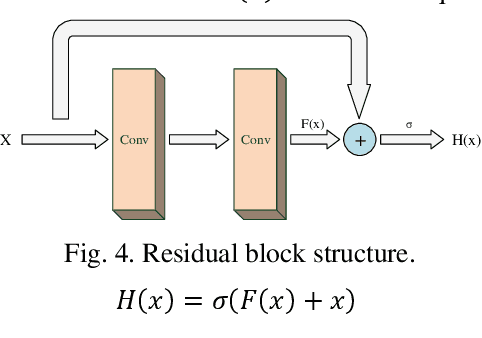

Perception plays an important role in reliable decision-making for autonomous vehicles. Over the last ten years, huge advances have been made in the field of perception. However, perception in extreme weather conditions is still a difficult problem, especially in rainy weather conditions. In order to improve the detection effect of road targets in rainy environments, we analyze the physical characteristics of the rain layer and propose a deraining convolutional neural network structure. Based on this network structure, we design an ablation experiment and experiment results show that our method can effectively improve the accuracy of object detection in rainy conditions.
Ghost Panorama
Aug 13, 2021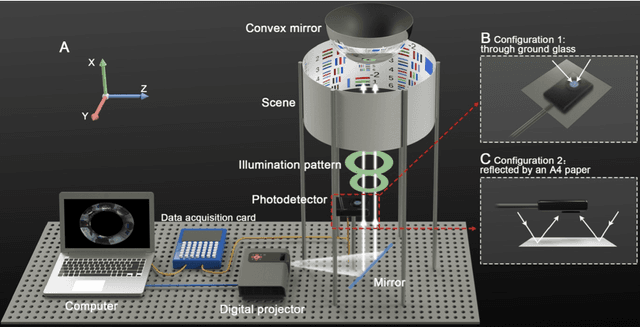
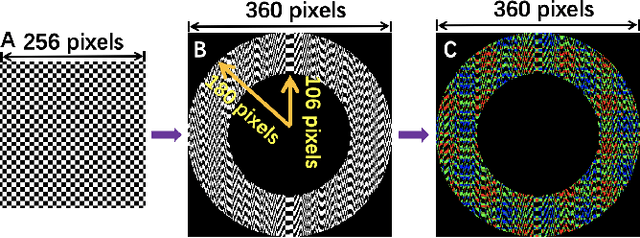


Computational ghost imaging or single-pixel imaging enables the image formation of an unknown scene using a lens-free photodetector. In this Letter, we present a computational panoramic ghost imaging system that can achieve the full-color panorama using a single-pixel photodetector, where a convex mirror performs the optical transformation of the engineered Hadamard-based circular illumination pattern from unidirectionally to omnidirectionally. To our best knowledge, it is the first time to propose the concept of ghost panorama and realize preliminary experimentations. It is foreseeable that ghost panorama will have more advantages in imaging and detection in many extreme conditions (e.g., scattering/turbulence, cryogenic temperatures, and unconventional spectra), as well as broad application prospects in the positioning of fast-moving targets and situation awareness for autonomous vehicles.