 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniFall: A Unified Staged-to-Wild Benchmark for Human Fall Detection
May 26, 2025Current video-based fall detection research mostly relies on small, staged datasets with significant domain biases concerning background, lighting, and camera setup resulting in unknown real-world performance. We introduce OmniFall, unifying eight public fall detection datasets (roughly 14 h of recordings, roughly 42 h of multiview data, 101 subjects, 29 camera views) under a consistent ten-class taxonomy with standardized evaluation protocols. Our benchmark provides complete video segmentation labels and enables fair cross-dataset comparison previously impossible with incompatible annotation schemes. For real-world evaluation we curate OOPS-Fall from genuine accident videos and establish a staged-to-wild protocol measuring generalization from controlled to uncontrolled environments. Experiments with frozen pre-trained backbones such as I3D or VideoMAE reveal significant performance gaps between in-distribution and in-the-wild scenarios, highlighting critical challenges in developing robust fall detection systems. OmniFall Dataset at https://huggingface.co/datasets/simplexsigil2/omnifall , Code at https://github.com/simplexsigil/omnifall-experiments
SAMBLE: Shape-Specific Point Cloud Sampling for an Optimal Trade-Off Between Local Detail and Global Uniformity
Apr 28, 2025Driven by the increasing demand for accurate and efficient representation of 3D data in various domains, point cloud sampling has emerged as a pivotal research topic in 3D computer vision. Recently, learning-to-sample methods have garnered growing interest from the community, particularly for their ability to be jointly trained with downstream tasks. However, previous learning-based sampling methods either lead to unrecognizable sampling patterns by generating a new point cloud or biased sampled results by focusing excessively on sharp edge details. Moreover, they all overlook the natural variations in point distribution across different shapes, applying a similar sampling strategy to all point clouds. In this paper, we propose a Sparse Attention Map and Bin-based Learning method (termed SAMBLE) to learn shape-specific sampling strategies for point cloud shapes. SAMBLE effectively achieves an improved balance between sampling edge points for local details and preserving uniformity in the global shape, resulting in superior performance across multiple common point cloud downstream tasks, even in scenarios with few-point sampling.
Rethinking Attention Module Design for Point Cloud Analysis
Jul 27, 2024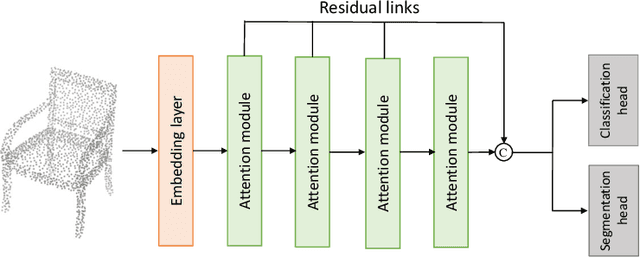
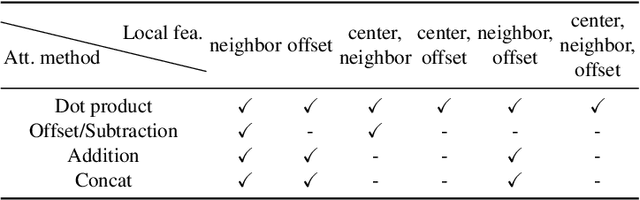
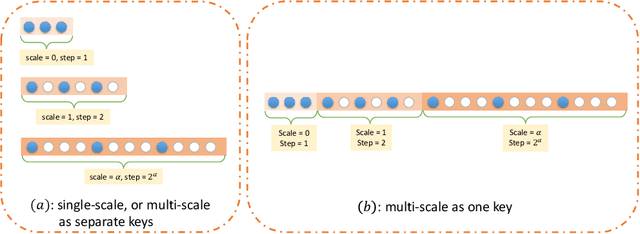

In recent years, there have been significant advancements in applying attention mechanisms to point cloud analysis. However, attention module variants featured in various research papers often operate under diverse settings and tasks, incorporating potential training strategies. This heterogeneity poses challenges in establishing a fair comparison among these attention module variants. In this paper, we address this issue by rethinking and exploring attention module design within a consistent base framework and settings. Both global-based and local-based attention methods are studied, with a focus on the selection basis and scales of neighbors for local-based attention. Different combinations of aggregated local features and computation methods for attention scores are evaluated, ranging from the initial addition/concatenation-based approach to the widely adopted dot product-based method and the recently proposed vector attention technique. Various position encoding methods are also investigated. Our extensive experimental analysis reveals that there is no universally optimal design across diverse point cloud tasks. Instead, drawing from best practices, we propose tailored attention modules for specific tasks, leading to superior performance on point cloud classification and segmentation benchmarks.
QueryMamba: A Mamba-Based Encoder-Decoder Architecture with a Statistical Verb-Noun Interaction Module for Video Action Forecasting @ Ego4D Long-Term Action Anticipation Challenge 2024
Jul 04, 2024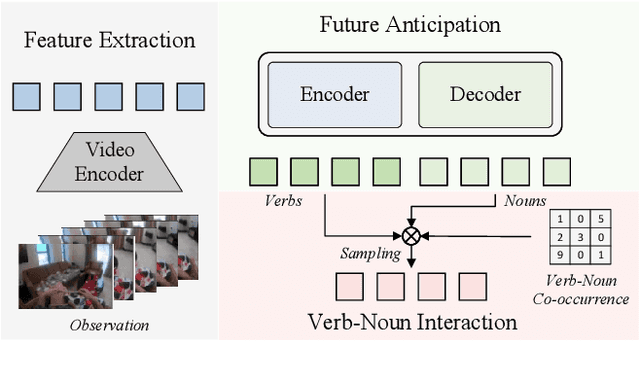
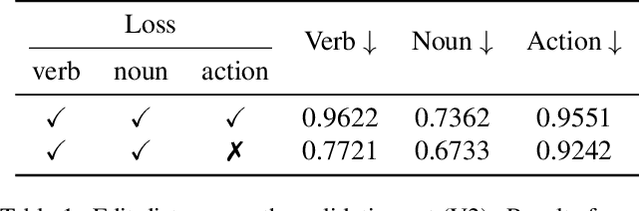
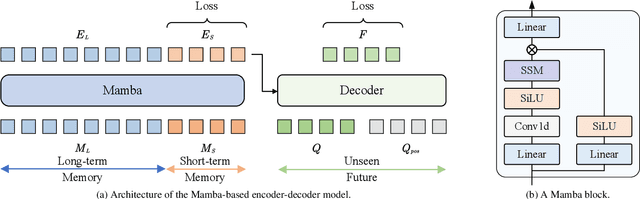
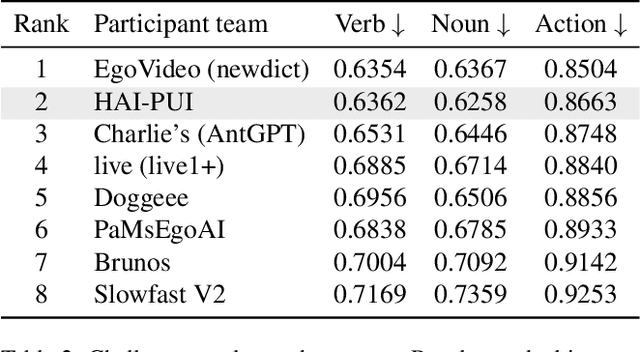
This report presents a novel Mamba-based encoder-decoder architecture, QueryMamba, featuring an integrated verb-noun interaction module that utilizes a statistical verb-noun co-occurrence matrix to enhance video action forecasting. This architecture not only predicts verbs and nouns likely to occur based on historical data but also considers their joint occurrence to improve forecast accuracy. The efficacy of this approach is substantiated by experimental results, with the method achieving second place in the Ego4D LTA challenge and ranking first in noun prediction accuracy.
DiffAnt: Diffusion Models for Action Anticipation
Nov 27, 2023Anticipating future actions is inherently uncertain. Given an observed video segment containing ongoing actions, multiple subsequent actions can plausibly follow. This uncertainty becomes even larger when predicting far into the future. However, the majority of existing action anticipation models adhere to a deterministic approach, neglecting to account for future uncertainties. In this work, we rethink action anticipation from a generative view, employing diffusion models to capture different possible future actions. In this framework, future actions are iteratively generated from standard Gaussian noise in the latent space, conditioned on the observed video, and subsequently transitioned into the action space. Extensive experiments on four benchmark datasets, i.e., Breakfast, 50Salads, EpicKitchens, and EGTEA Gaze+, are performed and the proposed method achieves superior or comparable results to state-of-the-art methods, showing the effectiveness of a generative approach for action anticipation. Our code and trained models will be published on GitHub.
A Survey on Deep Learning Techniques for Action Anticipation
Sep 29, 2023The ability to anticipate possible future human actions is essential for a wide range of applications, including autonomous driving and human-robot interaction. Consequently, numerous methods have been introduced for action anticipation in recent years, with deep learning-based approaches being particularly popular. In this work, we review the recent advances of action anticipation algorithms with a particular focus on daily-living scenarios. Additionally, we classify these methods according to their primary contributions and summarize them in tabular form, allowing readers to grasp the details at a glance. Furthermore, we delve into the common evaluation metrics and datasets used for action anticipation and provide future directions with systematical discussions.
Anticipative Feature Fusion Transformer for Multi-Modal Action Anticipation
Oct 23, 2022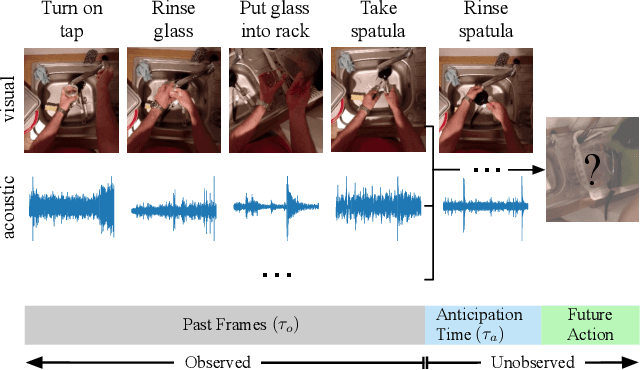

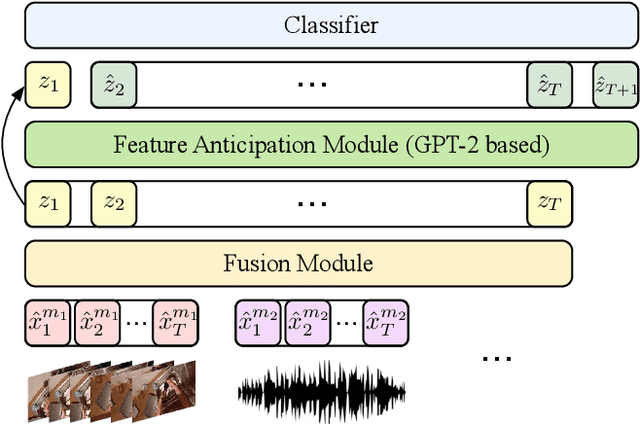
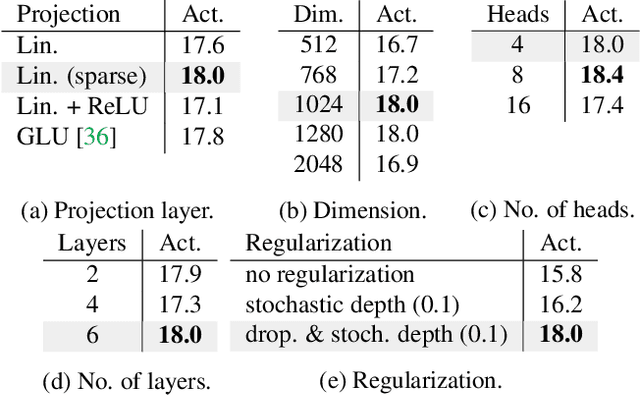
Although human action anticipation is a task which is inherently multi-modal, state-of-the-art methods on well known action anticipation datasets leverage this data by applying ensemble methods and averaging scores of unimodal anticipation networks. In this work we introduce transformer based modality fusion techniques, which unify multi-modal data at an early stage. Our Anticipative Feature Fusion Transformer (AFFT) proves to be superior to popular score fusion approaches and presents state-of-the-art results outperforming previous methods on EpicKitchens-100 and EGTEA Gaze+. Our model is easily extensible and allows for adding new modalities without architectural changes. Consequently, we extracted audio features on EpicKitchens-100 which we add to the set of commonly used features in the community.