 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Video Representation Alignment for Robust Self-supervised Driver Distraction Detection
Jun 01, 2026Robust self-supervised learning of multi-modal video representations is critical for real-world applications such as driver distraction detection, where multiple sensors provide complementary but noisy signals. Conventional contrastive objectives, such as InfoNCE, assume all negatives are equally informative and all positives are reliable. However, this assumption is frequently violated in multi-modal data due to viewpoint changes, occlusions, or semantic overlap across modalities. In this work, we propose a novel framework for multi-modal global alignment that addresses these challenges by jointly modeling faulty negatives and unreliable or faulty positives. We introduce soft targets derived from cycle-consistency scores to relax the hard-negative assumption, and a weighting mechanism based on similarity distributions to mitigate the impact of noisy or faulty positives. Our approach extends traditional pairwise alignment to a principled global multi-modal setting, aggregating alignment information across all modality pairs. We evaluate our method on the Drive&Act dataset, demonstrating that it consistently outperforms both pairwise and existing global alignment baselines across RGB, IR, Depth, and Skeleton modalities. Cross-view ablation studies further show strong generalization to unseen camera perspectives, highlighting the robustness of our representations. Overall, our framework provides a scalable and effective solution for self-supervised global multi-modal representation learning, enabling reliable driver distraction detection and pioneering in real-world multi-modal video understanding. Our code will be published on GitHub.
Vision-language Models for Driver Monitoring Systems: A Driver Activity Description Dataset
Jun 01, 2026Understanding subtle driver actions is essential for building reliable driver monitoring systems. Existing visionlanguage models (VLMs) are trained on general datasets and struggle to recognize fine distinctions in driver behaviors. This paper addresses this limitation by creating a detailed natural language version of the Drive&Act dataset. We evaluate three VLMs on our new benchmark using LLM-based scoring methods. Their performance on the new benchmark shows that they cannot reliably generate accurate fine-grained driver activity descriptions. Based on the labeled Drive&Act dataset we create a new Drive&Act description dataset containing finegrained descriptions to train VLMs on driver activity understanding. Cross dataset evaluation on the Driver Monitoring Dataset (DMD) shows that the VLM fine-tuned on our new Drive&Act description dataset generalizes well to actions in the DMD dataset. The VLM fine-tuned on our Drive&Act description dataset achieves an ACCR score of 76 outperforming the zero-shot VLM baseline with an ACCR score of 66. These findings demonstrate that adapting VLMs with richly described driver actions can significantly improve their ability to interpret driver behavior while also highlighting the need for more diverse datasets to support broader generalization in future applications. Our Drive&Act description dataset and code will be publicly available on GitHub.
FlowNar: Scalable Streaming Narration for Long-Form Videos
May 30, 2026Recent Large Multimodal Models (LMMs), primarily designed for offline settings, are ill-suited for the dynamic requirements of streaming video. While recent online adaptations improve real-time processing, they still face critical scalability challenges, with resource demands typically growing at least linearly with video duration. To overcome this bottleneck, we propose FlowNar, a novel framework for scalable streaming video narration. The core of FlowNar is a dynamic context management strategy for historical visual context removal, combined with our CLAM (Cross Linear Attentive Memory) module for streaming visual history retention, ensuring bounded visual memory usage and computational complexity, crucial for efficient streaming. We also introduce a realistic self-conditioned evaluation protocol and complementary evaluation metrics to assess streaming narration models under deployment-like conditions. Experiments on the Ego4D, EgoExo4D, and EpicKitchens100 datasets demonstrate that FlowNar substantially improves narration quality over strong baselines while being highly efficient, supporting processing of 10$\times$ longer videos and achieving 3$\times$ higher throughput (FPS). The code is available at https://github.com/zeyun-zhong/FlowNar.
QueryMamba: A Mamba-Based Encoder-Decoder Architecture with a Statistical Verb-Noun Interaction Module for Video Action Forecasting @ Ego4D Long-Term Action Anticipation Challenge 2024
Jul 04, 2024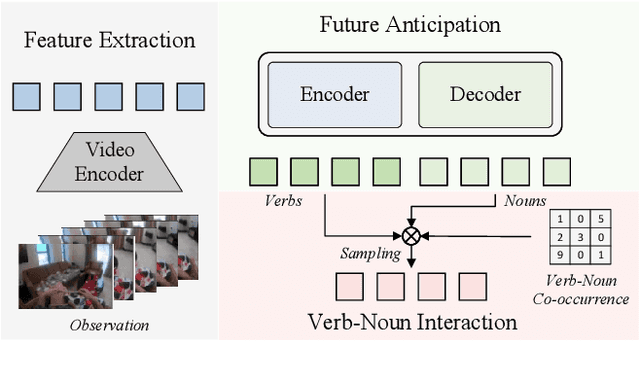
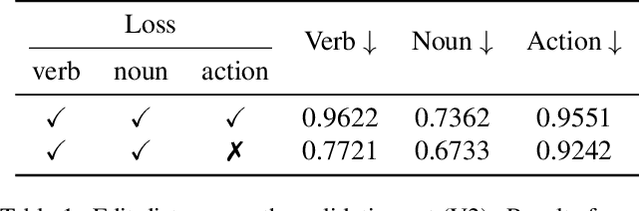
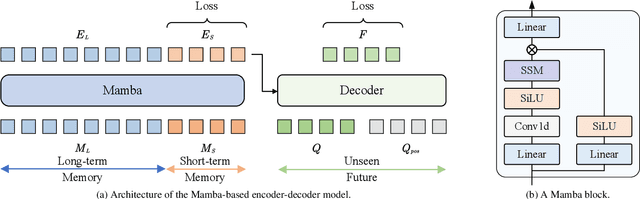
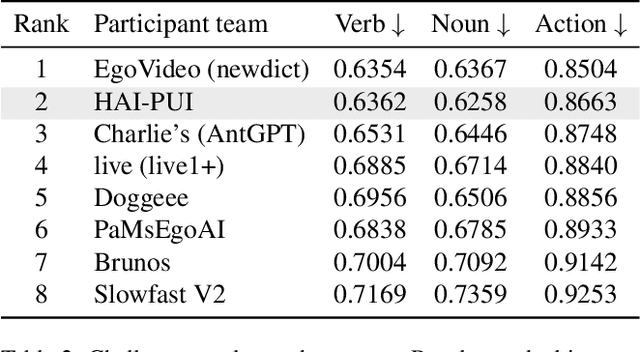
This report presents a novel Mamba-based encoder-decoder architecture, QueryMamba, featuring an integrated verb-noun interaction module that utilizes a statistical verb-noun co-occurrence matrix to enhance video action forecasting. This architecture not only predicts verbs and nouns likely to occur based on historical data but also considers their joint occurrence to improve forecast accuracy. The efficacy of this approach is substantiated by experimental results, with the method achieving second place in the Ego4D LTA challenge and ranking first in noun prediction accuracy.
DiffAnt: Diffusion Models for Action Anticipation
Nov 27, 2023Anticipating future actions is inherently uncertain. Given an observed video segment containing ongoing actions, multiple subsequent actions can plausibly follow. This uncertainty becomes even larger when predicting far into the future. However, the majority of existing action anticipation models adhere to a deterministic approach, neglecting to account for future uncertainties. In this work, we rethink action anticipation from a generative view, employing diffusion models to capture different possible future actions. In this framework, future actions are iteratively generated from standard Gaussian noise in the latent space, conditioned on the observed video, and subsequently transitioned into the action space. Extensive experiments on four benchmark datasets, i.e., Breakfast, 50Salads, EpicKitchens, and EGTEA Gaze+, are performed and the proposed method achieves superior or comparable results to state-of-the-art methods, showing the effectiveness of a generative approach for action anticipation. Our code and trained models will be published on GitHub.
A Survey on Deep Learning Techniques for Action Anticipation
Sep 29, 2023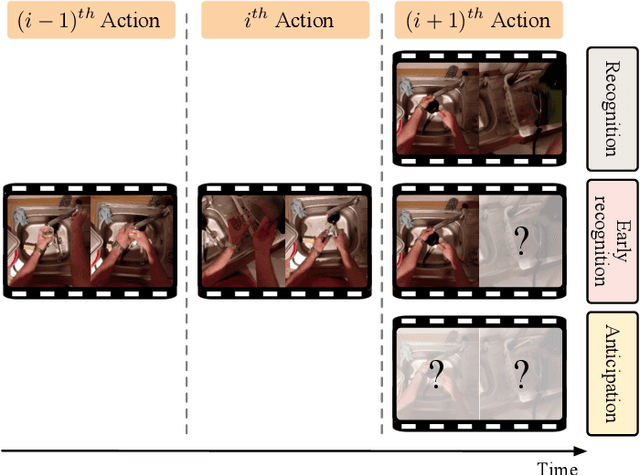
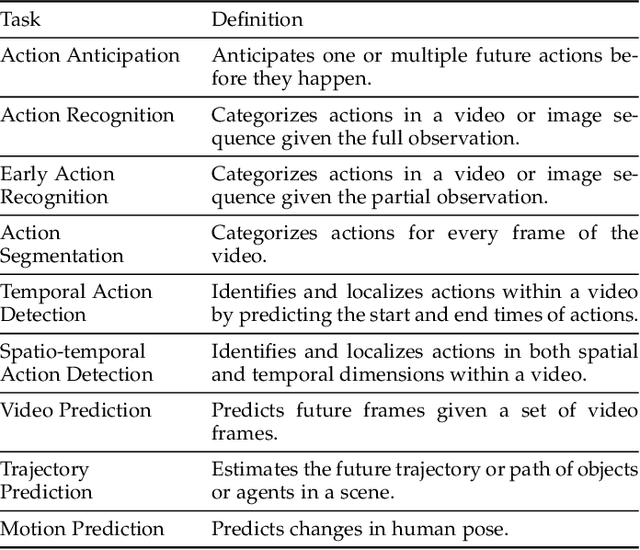

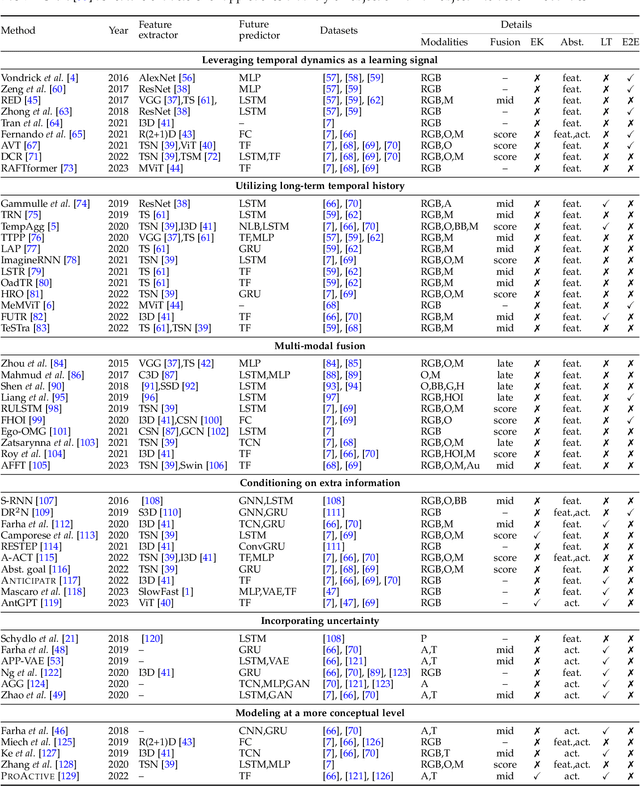
The ability to anticipate possible future human actions is essential for a wide range of applications, including autonomous driving and human-robot interaction. Consequently, numerous methods have been introduced for action anticipation in recent years, with deep learning-based approaches being particularly popular. In this work, we review the recent advances of action anticipation algorithms with a particular focus on daily-living scenarios. Additionally, we classify these methods according to their primary contributions and summarize them in tabular form, allowing readers to grasp the details at a glance. Furthermore, we delve into the common evaluation metrics and datasets used for action anticipation and provide future directions with systematical discussions.