Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueryMamba: A Mamba-Based Encoder-Decoder Architecture with a Statistical Verb-Noun Interaction Module for Video Action Forecasting @ Ego4D Long-Term Action Anticipation Challenge 2024
Jul 04, 2024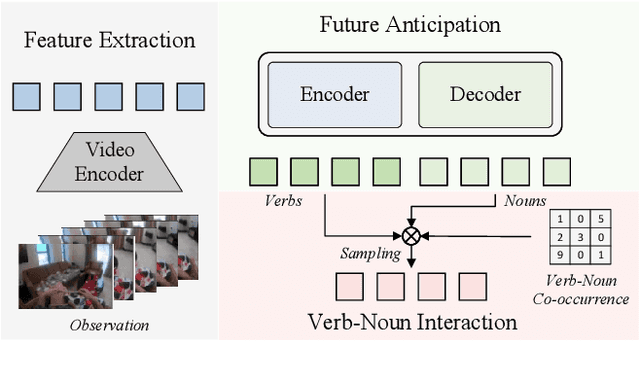
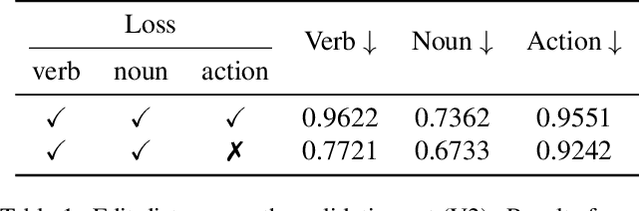
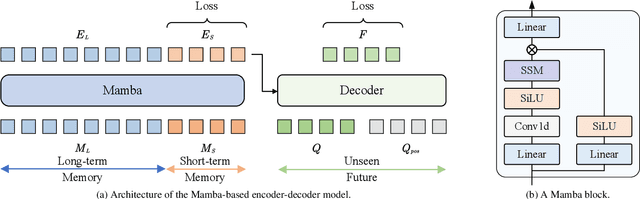
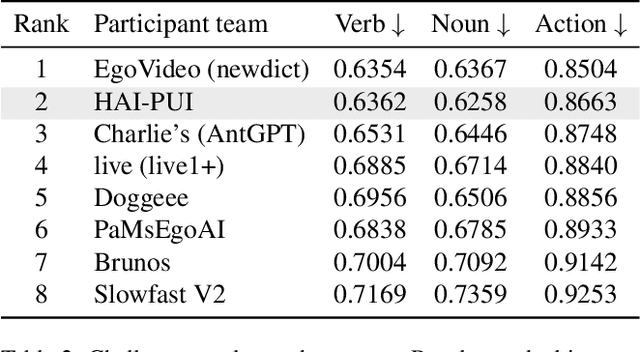
This report presents a novel Mamba-based encoder-decoder architecture, QueryMamba, featuring an integrated verb-noun interaction module that utilizes a statistical verb-noun co-occurrence matrix to enhance video action forecasting. This architecture not only predicts verbs and nouns likely to occur based on historical data but also considers their joint occurrence to improve forecast accuracy. The efficacy of this approach is substantiated by experimental results, with the method achieving second place in the Ego4D LTA challenge and ranking first in noun prediction accuracy.
Via