 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMPACT: A Dataset for Multi-Granularity Human Procedural Action Understanding in Industrial Assembly
Apr 12, 2026We introduce IMPACT, a synchronized five-view RGB-D dataset for deployment-oriented industrial procedural understanding, built around real assembly and disassembly of a commercial angle grinder with professional-grade tools. To our knowledge, IMPACT is the first real industrial assembly benchmark that jointly provides synchronized ego-exo RGB-D capture, decoupled bimanual annotation, compliance-aware state tracking, and explicit anomaly--recovery supervision within a single real industrial workflow. It comprises 112 trials from 13 participants totaling 39.5 hours, with multi-route execution governed by a partial-order prerequisite graph, a six-category anomaly taxonomy, and operator cognitive load measured via NASA-TLX. The annotation hierarchy links hand-specific atomic actions to coarse procedural steps, component assembly states, and per-hand compliance phases, with synchronized null spans across views to decouple perceptual limitations from algorithmic failure. Systematic baselines reveal fundamental limitations that remain invisible to single-task benchmarks, particularly under realistic deployment conditions that involve incomplete observations, flexible execution paths, and corrective behavior. The full dataset, annotations, and evaluation code are available at https://github.com/Kratos-Wen/IMPACT.
OmniFall: A Unified Staged-to-Wild Benchmark for Human Fall Detection
May 26, 2025Current video-based fall detection research mostly relies on small, staged datasets with significant domain biases concerning background, lighting, and camera setup resulting in unknown real-world performance. We introduce OmniFall, unifying eight public fall detection datasets (roughly 14 h of recordings, roughly 42 h of multiview data, 101 subjects, 29 camera views) under a consistent ten-class taxonomy with standardized evaluation protocols. Our benchmark provides complete video segmentation labels and enables fair cross-dataset comparison previously impossible with incompatible annotation schemes. For real-world evaluation we curate OOPS-Fall from genuine accident videos and establish a staged-to-wild protocol measuring generalization from controlled to uncontrolled environments. Experiments with frozen pre-trained backbones such as I3D or VideoMAE reveal significant performance gaps between in-distribution and in-the-wild scenarios, highlighting critical challenges in developing robust fall detection systems. OmniFall Dataset at https://huggingface.co/datasets/simplexsigil2/omnifall , Code at https://github.com/simplexsigil/omnifall-experiments
Mitigating Label Noise using Prompt-Based Hyperbolic Meta-Learning in Open-Set Domain Generalization
Dec 24, 2024



Open-Set Domain Generalization (OSDG) is a challenging task requiring models to accurately predict familiar categories while minimizing confidence for unknown categories to effectively reject them in unseen domains. While the OSDG field has seen considerable advancements, the impact of label noise--a common issue in real-world datasets--has been largely overlooked. Label noise can mislead model optimization, thereby exacerbating the challenges of open-set recognition in novel domains. In this study, we take the first step towards addressing Open-Set Domain Generalization under Noisy Labels (OSDG-NL) by constructing dedicated benchmarks derived from widely used OSDG datasets, including PACS and DigitsDG. We evaluate baseline approaches by integrating techniques from both label denoising and OSDG methodologies, highlighting the limitations of existing strategies in handling label noise effectively. To address these limitations, we propose HyProMeta, a novel framework that integrates hyperbolic category prototypes for label noise-aware meta-learning alongside a learnable new-category agnostic prompt designed to enhance generalization to unseen classes. Our extensive experiments demonstrate the superior performance of HyProMeta compared to state-of-the-art methods across the newly established benchmarks. The source code of this work is released at https://github.com/KPeng9510/HyProMeta.
Rendering-Refined Stable Diffusion for Privacy Compliant Synthetic Data
Dec 09, 2024Growing privacy concerns and regulations like GDPR and CCPA necessitate pseudonymization techniques that protect identity in image datasets. However, retaining utility is also essential. Traditional methods like masking and blurring degrade quality and obscure critical context, especially in human-centric images. We introduce Rendering-Refined Stable Diffusion (RefSD), a pipeline that combines 3D-rendering with Stable Diffusion, enabling prompt-based control over human attributes while preserving posture. Unlike standard diffusion models that fail to retain posture or GANs that lack realism and flexible attribute control, RefSD balances posture preservation, realism, and customization. We also propose HumanGenAI, a framework for human perception and utility evaluation. Human perception assessments reveal attribute-specific strengths and weaknesses of RefSD. Our utility experiments show that models trained on RefSD pseudonymized data outperform those trained on real data in detection tasks, with further performance gains when combining RefSD with real data. For classification tasks, we consistently observe performance improvements when using RefSD data with real data, confirming the utility of our pseudonymized data.
Muscles in Time: Learning to Understand Human Motion by Simulating Muscle Activations
Oct 31, 2024



Exploring the intricate dynamics between muscular and skeletal structures is pivotal for understanding human motion. This domain presents substantial challenges, primarily attributed to the intensive resources required for acquiring ground truth muscle activation data, resulting in a scarcity of datasets. In this work, we address this issue by establishing Muscles in Time (MinT), a large-scale synthetic muscle activation dataset. For the creation of MinT, we enriched existing motion capture datasets by incorporating muscle activation simulations derived from biomechanical human body models using the OpenSim platform, a common approach in biomechanics and human motion research. Starting from simple pose sequences, our pipeline enables us to extract detailed information about the timing of muscle activations within the human musculoskeletal system. Muscles in Time contains over nine hours of simulation data covering 227 subjects and 402 simulated muscle strands. We demonstrate the utility of this dataset by presenting results on neural network-based muscle activation estimation from human pose sequences with two different sequence-to-sequence architectures. Data and code are provided under https://simplexsigil.github.io/mint.
Masked Differential Privacy
Oct 22, 2024



Privacy-preserving computer vision is an important emerging problem in machine learning and artificial intelligence. The prevalent methods tackling this problem use differential privacy or anonymization and obfuscation techniques to protect the privacy of individuals. In both cases, the utility of the trained model is sacrificed heavily in this process. In this work, we propose an effective approach called masked differential privacy (MaskDP), which allows for controlling sensitive regions where differential privacy is applied, in contrast to applying DP on the entire input. Our method operates selectively on the data and allows for defining non-sensitive spatio-temporal regions without DP application or combining differential privacy with other privacy techniques within data samples. Experiments on four challenging action recognition datasets demonstrate that our proposed techniques result in better utility-privacy trade-offs compared to standard differentially private training in the especially demanding $\epsilon<1$ regime.
Navigating Open Set Scenarios for Skeleton-based Action Recognition
Dec 11, 2023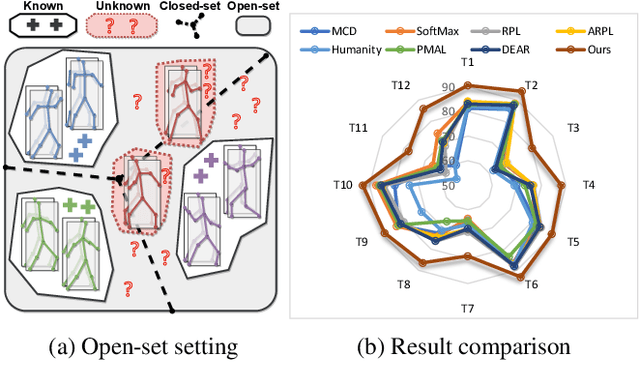
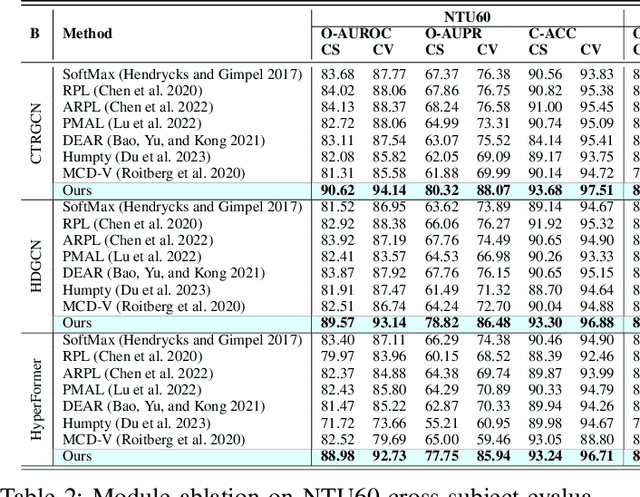
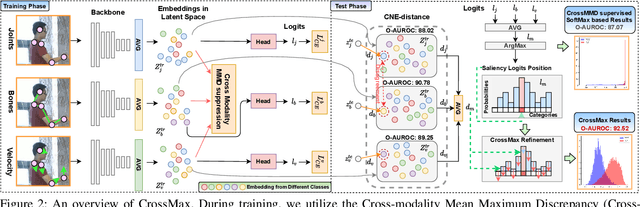
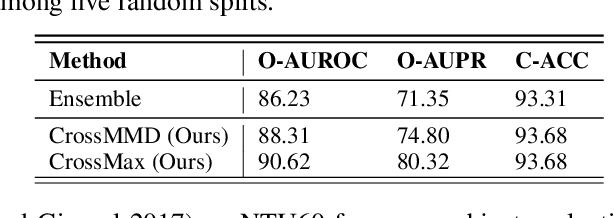
In real-world scenarios, human actions often fall outside the distribution of training data, making it crucial for models to recognize known actions and reject unknown ones. However, using pure skeleton data in such open-set conditions poses challenges due to the lack of visual background cues and the distinct sparse structure of body pose sequences. In this paper, we tackle the unexplored Open-Set Skeleton-based Action Recognition (OS-SAR) task and formalize the benchmark on three skeleton-based datasets. We assess the performance of seven established open-set approaches on our task and identify their limits and critical generalization issues when dealing with skeleton information. To address these challenges, we propose a distance-based cross-modality ensemble method that leverages the cross-modal alignment of skeleton joints, bones, and velocities to achieve superior open-set recognition performance. We refer to the key idea as CrossMax - an approach that utilizes a novel cross-modality mean max discrepancy suppression mechanism to align latent spaces during training and a cross-modality distance-based logits refinement method during testing. CrossMax outperforms existing approaches and consistently yields state-of-the-art results across all datasets and backbones. The benchmark, code, and models will be released at https://github.com/KPeng9510/OS-SAR.
Unveiling the Hidden Realm: Self-supervised Skeleton-based Action Recognition in Occluded Environments
Sep 21, 2023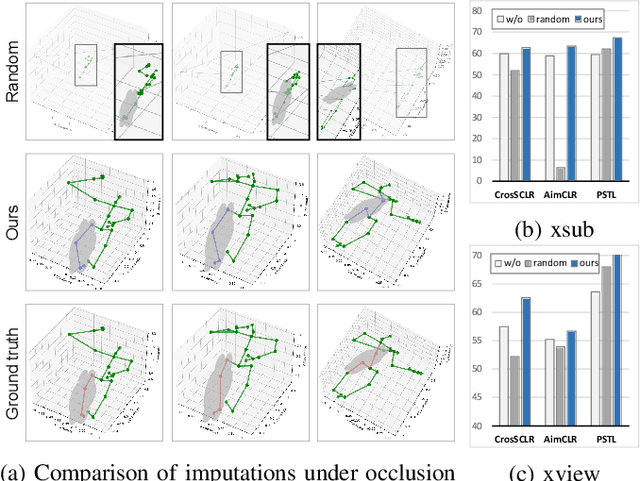
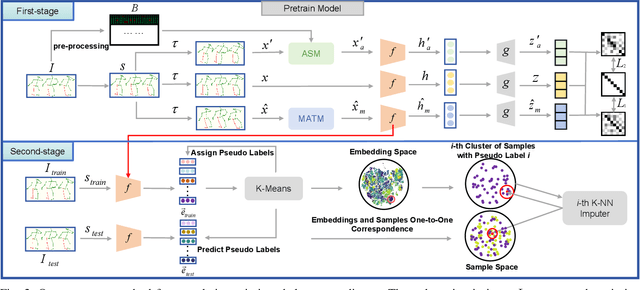
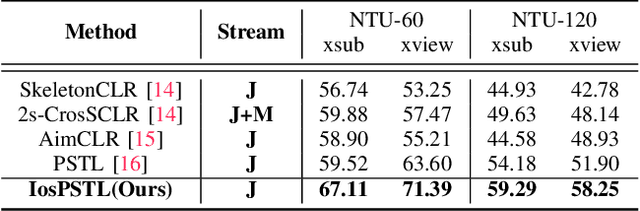
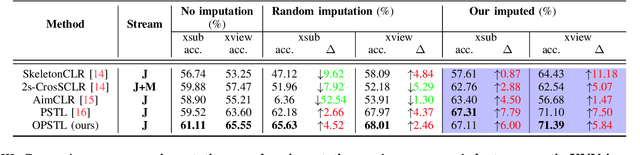
To integrate action recognition methods into autonomous robotic systems, it is crucial to consider adverse situations involving target occlusions. Such a scenario, despite its practical relevance, is rarely addressed in existing self-supervised skeleton-based action recognition methods. To empower robots with the capacity to address occlusion, we propose a simple and effective method. We first pre-train using occluded skeleton sequences, then use k-means clustering (KMeans) on sequence embeddings to group semantically similar samples. Next, we employ K-nearest-neighbor (KNN) to fill in missing skeleton data based on the closest sample neighbors. Imputing incomplete skeleton sequences to create relatively complete sequences as input provides significant benefits to existing skeleton-based self-supervised models. Meanwhile, building on the state-of-the-art Partial Spatio-Temporal Learning (PSTL), we introduce an Occluded Partial Spatio-Temporal Learning (OPSTL) framework. This enhancement utilizes Adaptive Spatial Masking (ASM) for better use of high-quality, intact skeletons. The effectiveness of our imputation methods is verified on the challenging occluded versions of the NTURGB+D 60 and NTURGB+D 120. The source code will be made publicly available at https://github.com/cyfml/OPSTL.
FeatFSDA: Towards Few-shot Domain Adaptation for Video-based Activity Recognition
May 15, 2023Domain adaptation is essential for activity recognition, as common spatiotemporal architectures risk overfitting due to increased parameters arising from the temporal dimension. Unsupervised domain adaptation methods have been extensively studied, yet, they require large-scale unlabeled data from the target domain. In this work, we address few-shot domain adaptation for video-based activity recognition (FSDA-AR), which leverages a very small amount of labeled target videos to achieve effective adaptation. This setting is attractive and promising for applications, as it requires recording and labeling only a few, or even a single example per class in the target domain, which often includes activities that are rare yet crucial to recognize. We construct FSDA-AR benchmarks using five established datasets: UCF101, HMDB51, EPIC-KITCHEN, Sims4Action, and Toyota Smart Home. Our results demonstrate that FSDA-AR performs comparably to unsupervised domain adaptation with significantly fewer (yet labeled) target examples. We further propose a novel approach, FeatFSDA, to better leverage the few labeled target domain samples as knowledge guidance. FeatFSDA incorporates a latent space semantic adjacency loss, a domain prototypical similarity loss, and a graph-attentive-network-based edge dropout technique. Our approach achieves state-of-the-art performance on all datasets within our FSDA-AR benchmark. To encourage future research of few-shot domain adaptation for video-based activity recognition, we will release our benchmarks and code at https://github.com/KPeng9510/FeatFSDA.
MuscleMap: Towards Video-based Activated Muscle Group Estimation
Mar 17, 2023



In this paper, we tackle the new task of video-based Activated Muscle Group Estimation (AMGE) aiming at identifying active muscle regions during physical activity. To this intent, we provide the MuscleMap136 dataset featuring >15K video clips with 136 different activities and 20 labeled muscle groups. This dataset opens the vistas to multiple video-based applications in sports and rehabilitation medicine. We further complement the main MuscleMap136 dataset, which specifically targets physical exercise, with Muscle-UCF90 and Muscle-HMDB41, which are new variants of the well-known activity recognition benchmarks extended with AMGE annotations. To make the AMGE model applicable in real-life situations, it is crucial to ensure that the model can generalize well to types of physical activities not present during training and involving new combinations of activated muscles. To achieve this, our benchmark also covers an evaluation setting where the model is exposed to activity types excluded from the training set. Our experiments reveal that generalizability of existing architectures adapted for the AMGE task remains a challenge. Therefore, we also propose a new approach, TransM3E, which employs a transformer-based model with cross-modal multi-label knowledge distillation and surpasses all popular video classification models when dealing with both, previously seen and new types of physical activities. The datasets and code will be publicly available at https://github.com/KPeng9510/MuscleMap.