 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuo Vadis, Visual In-Context Learning? A Unified Benchmark Across Domains and Tasks
Jun 09, 2026Visual in-context learning has been proposed as a pathway towards dynamic models that can generate predictions based on a provided context and thereby can adapt to new vision tasks at test-time. Yet, the evaluation of the adaptation capabilities of these models has been limited to narrow setups that mainly mirror tasks or image domains from pre-training for which real adaptation is not required. We address this gap by constructing a broad Visual In-Context BEnchmark (VIBE) with a focus on diverse imaging domains and a wide range of tasks. With this, we are able to get a much clearer picture of the adaptive capabilities of visual in-context models when faced with new image- and task distributions. We stress test six models on $14$ datasets and $12$ tasks (in total, we explore $106$ dataset-task combinations) and compare them under a unified, reproducible evaluation protocol, in an one-shot setting. Our evaluation uncovers key insights on the state of visual in-context learning, including limitations, systematic failure modes and promising directions. To foster broader evaluation, we will openly release our VIBE toolkit.
The autoPET3 Challenge -- Automated Lesion Segmentation in Whole-Body PET/CT - Multitracer Multicenter Generalization
May 07, 2026We report the design and results of the third autoPET challenge (MICCAI 2024), which benchmarked automated lesion segmentation in whole-body PET/CT under a compositional generalization setting. Training data comprised 1,014 [18F]-FDG PET/CT studies from the University Hospital Tübingen and 597 [18F]/[68Ga]-PSMA PET/CT studies from the LMU University Hospital Munich, constituting the largest publicly available annotated PSMA PET/CT dataset to date. The held-out test set of 200 studies covered four tracer-center combinations, two of which represented unseen compositional pairings. A complementary data-centric award category isolated the contribution of data handling strategies by restricting participants to a fixed baseline model. Seventeen teams submitted 27 algorithms, predominantly nnU-Net-based 3D networks with PET/CT channel concatenation. The top-ranked algorithm achieved a mean DSC of 0.66, FNV of 3.18 mL, and FPV of 2.78 mL across all four test conditions, improving DSC by 8% and reducing the false-negative volume by 5 mL relative to the provided baseline. Ranking was stable across bootstrap resampling and alternative ranking schemes for the top tier. Beyond the benchmark, we provide an in-depth analysis of segmentation performance at the patient and lesion level. Three main conclusions can be drawn: (1) in-domain multitracer PET/CT segmentation is sufficient and probably approaching reader agreement; (2) compositional generalization to unseen tracer-center combinations remains an open problem mainly driven by systematic volume overestimation; (3) heterogeneity and case difficulty drive performance variation substantially more than the choice of algorithm among top-ranked teams.
IMPACT-CYCLE: A Contract-Based Multi-Agent System for Claim-Level Supervisory Correction of Long-Video Semantic Memory
Apr 22, 2026Correcting errors in long-video understanding is disproportionately costly: existing multimodal pipelines produce opaque, end-to-end outputs that expose no intermediate state for inspection, forcing annotators to revisit raw video and reconstruct temporal logic from scratch. The core bottleneck is not generation quality alone, but the absence of a supervisory interface through which human effort can be proportional to the scope of each error. We present IMPACT-CYCLE, a supervisory multi-agent system that reformulates long-video understanding as iterative claim-level maintenance of a shared semantic memory -- a structured, versioned state encoding typed claims, a claim dependency graph, and a provenance log. Role-specialized agents operating under explicit authority contracts decompose verification into local object-relation correctness, cross-temporal consistency, and global semantic coherence, with corrections confined to structurally dependent claims. When automated evidence is insufficient, the system escalates to human arbitration as the supervisory authority with final override rights; dependency-closure re-verification then ensures correction cost remains proportional to error scope. Experiments on VidOR show substantially improved downstream reasoning (VQA: 0.71 to 0.79) and a 4.8x reduction in human arbitration cost, with workload significantly lower than manual annotation. Code will be released at https://github.com/MKong17/IMPACT_CYCLE.
Semantic Segmentation for Preoperative Planning in Transcatheter Aortic Valve Replacement
Jul 22, 2025When preoperative planning for surgeries is conducted on the basis of medical images, artificial intelligence methods can support medical doctors during assessment. In this work, we consider medical guidelines for preoperative planning of the transcatheter aortic valve replacement (TAVR) and identify tasks, that may be supported via semantic segmentation models by making relevant anatomical structures measurable in computed tomography scans. We first derive fine-grained TAVR-relevant pseudo-labels from coarse-grained anatomical information, in order to train segmentation models and quantify how well they are able to find these structures in the scans. Furthermore, we propose an adaptation to the loss function in training these segmentation models and through this achieve a +1.27% Dice increase in performance. Our fine-grained TAVR-relevant pseudo-labels and the computed tomography scans we build upon are available at https://doi.org/10.5281/zenodo.16274176.
Is Visual in-Context Learning for Compositional Medical Tasks within Reach?
Jul 02, 2025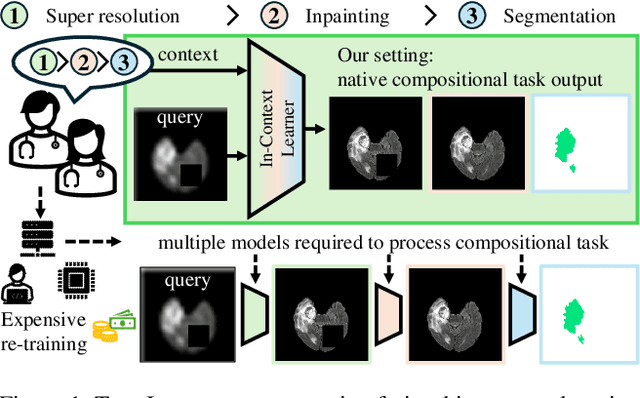
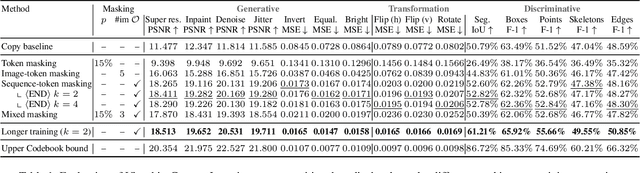
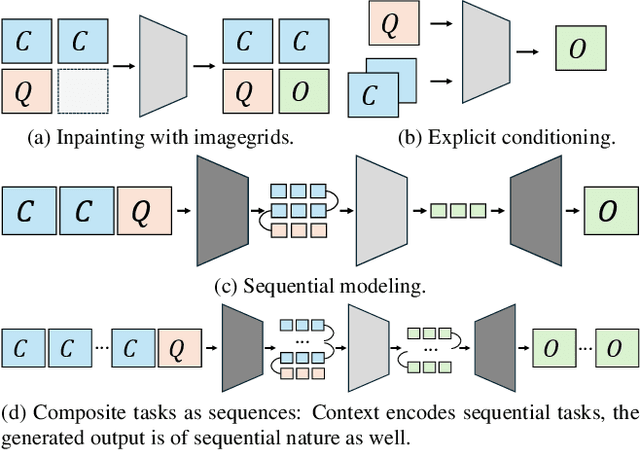
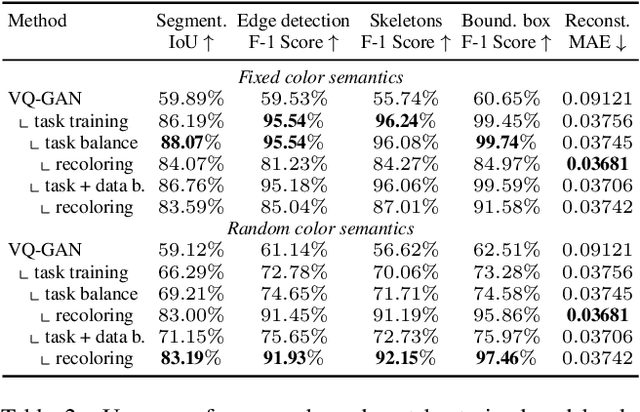
In this paper, we explore the potential of visual in-context learning to enable a single model to handle multiple tasks and adapt to new tasks during test time without re-training. Unlike previous approaches, our focus is on training in-context learners to adapt to sequences of tasks, rather than individual tasks. Our goal is to solve complex tasks that involve multiple intermediate steps using a single model, allowing users to define entire vision pipelines flexibly at test time. To achieve this, we first examine the properties and limitations of visual in-context learning architectures, with a particular focus on the role of codebooks. We then introduce a novel method for training in-context learners using a synthetic compositional task generation engine. This engine bootstraps task sequences from arbitrary segmentation datasets, enabling the training of visual in-context learners for compositional tasks. Additionally, we investigate different masking-based training objectives to gather insights into how to train models better for solving complex, compositional tasks. Our exploration not only provides important insights especially for multi-modal medical task sequences but also highlights challenges that need to be addressed.
Good Enough: Is it Worth Improving your Label Quality?
May 27, 2025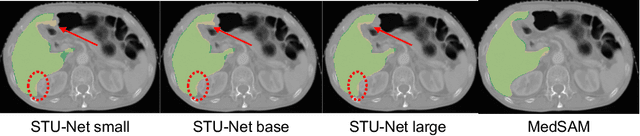
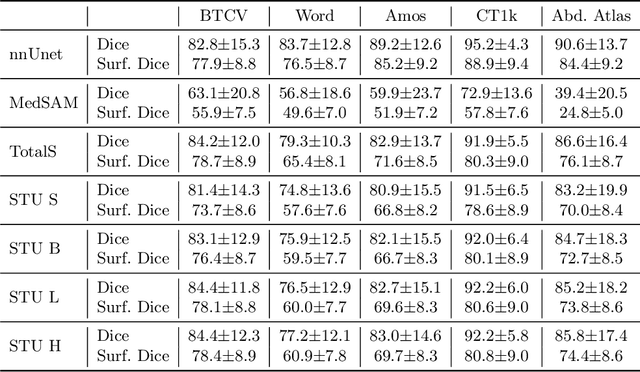
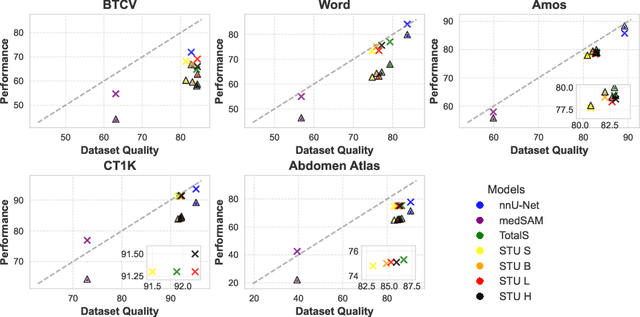
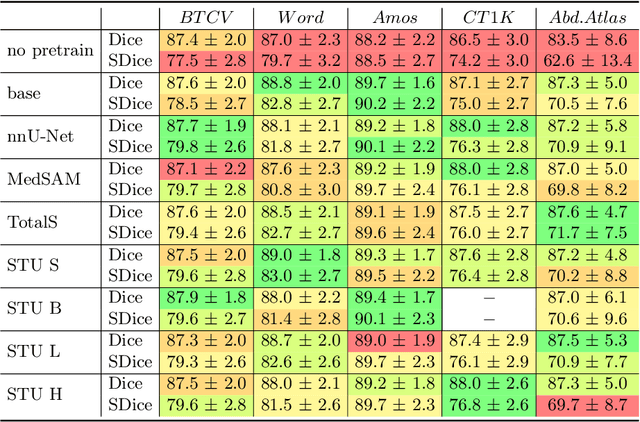
Improving label quality in medical image segmentation is costly, but its benefits remain unclear. We systematically evaluate its impact using multiple pseudo-labeled versions of CT datasets, generated by models like nnU-Net, TotalSegmentator, and MedSAM. Our results show that while higher-quality labels improve in-domain performance, gains remain unclear if below a small threshold. For pre-training, label quality has minimal impact, suggesting that models rather transfer general concepts than detailed annotations. These findings provide guidance on when improving label quality is worth the effort.
Muscles in Time: Learning to Understand Human Motion by Simulating Muscle Activations
Oct 31, 2024



Exploring the intricate dynamics between muscular and skeletal structures is pivotal for understanding human motion. This domain presents substantial challenges, primarily attributed to the intensive resources required for acquiring ground truth muscle activation data, resulting in a scarcity of datasets. In this work, we address this issue by establishing Muscles in Time (MinT), a large-scale synthetic muscle activation dataset. For the creation of MinT, we enriched existing motion capture datasets by incorporating muscle activation simulations derived from biomechanical human body models using the OpenSim platform, a common approach in biomechanics and human motion research. Starting from simple pose sequences, our pipeline enables us to extract detailed information about the timing of muscle activations within the human musculoskeletal system. Muscles in Time contains over nine hours of simulation data covering 227 subjects and 402 simulated muscle strands. We demonstrate the utility of this dataset by presenting results on neural network-based muscle activation estimation from human pose sequences with two different sequence-to-sequence architectures. Data and code are provided under https://simplexsigil.github.io/mint.
Every Component Counts: Rethinking the Measure of Success for Medical Semantic Segmentation in Multi-Instance Segmentation Tasks
Oct 24, 2024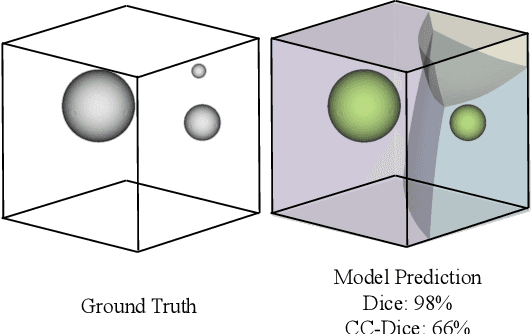
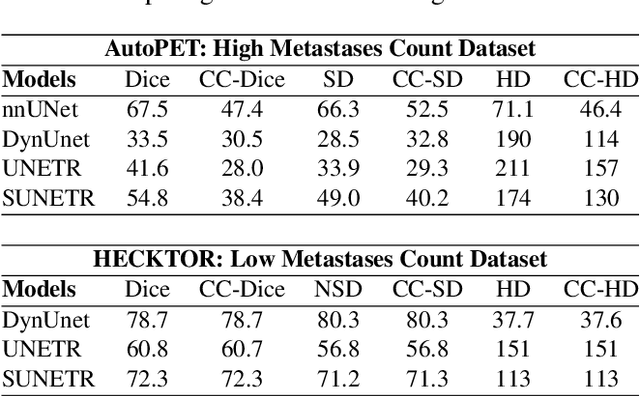
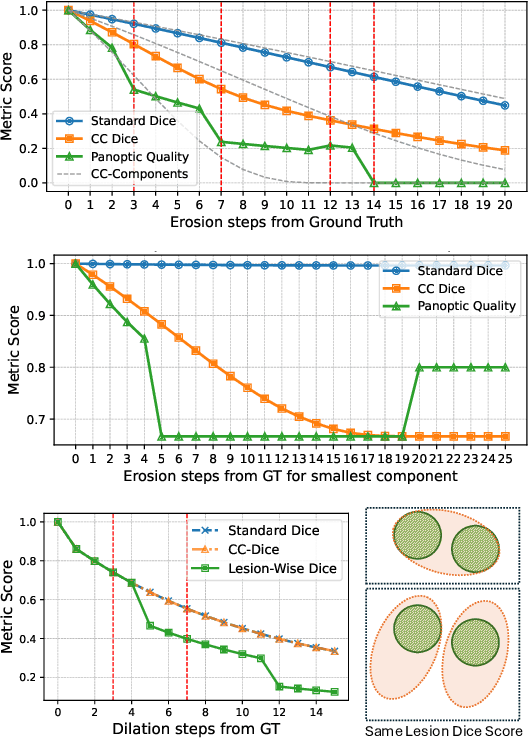
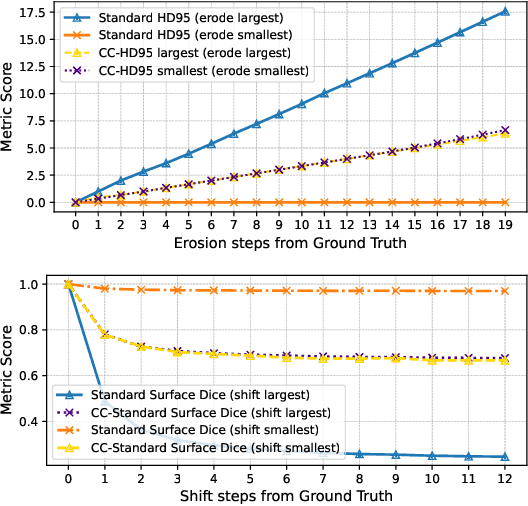
We present Connected-Component~(CC)-Metrics, a novel semantic segmentation evaluation protocol, targeted to align existing semantic segmentation metrics to a multi-instance detection scenario in which each connected component matters. We motivate this setup in the common medical scenario of semantic metastases segmentation in a full-body PET/CT. We show how existing semantic segmentation metrics suffer from a bias towards larger connected components contradicting the clinical assessment of scans in which tumor size and clinical relevance are uncorrelated. To rebalance existing segmentation metrics, we propose to evaluate them on a per-component basis thus giving each tumor the same weight irrespective of its size. To match predictions to ground-truth segments, we employ a proximity-based matching criterion, evaluating common metrics locally at the component of interest. Using this approach, we break free of biases introduced by large metastasis for overlap-based metrics such as Dice or Surface Dice. CC-Metrics also improves distance-based metrics such as Hausdorff Distances which are uninformative for small changes that do not influence the maximum or 95th percentile, and avoids pitfalls introduced by directly combining counting-based metrics with overlap-based metrics as it is done in Panoptic Quality.
LIMIS: Towards Language-based Interactive Medical Image Segmentation
Oct 22, 2024Within this work, we introduce LIMIS: The first purely language-based interactive medical image segmentation model. We achieve this by adapting Grounded SAM to the medical domain and designing a language-based model interaction strategy that allows radiologists to incorporate their knowledge into the segmentation process. LIMIS produces high-quality initial segmentation masks by leveraging medical foundation models and allows users to adapt segmentation masks using only language, opening up interactive segmentation to scenarios where physicians require using their hands for other tasks. We evaluate LIMIS on three publicly available medical datasets in terms of performance and usability with experts from the medical domain confirming its high-quality segmentation masks and its interactive usability.
Anatomy-guided Pathology Segmentation
Jul 08, 2024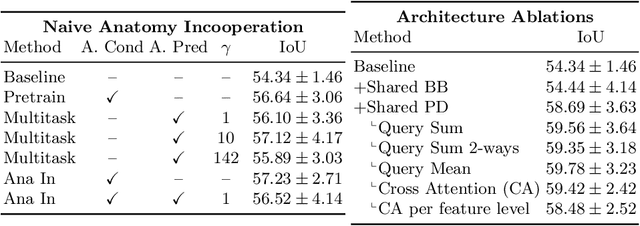
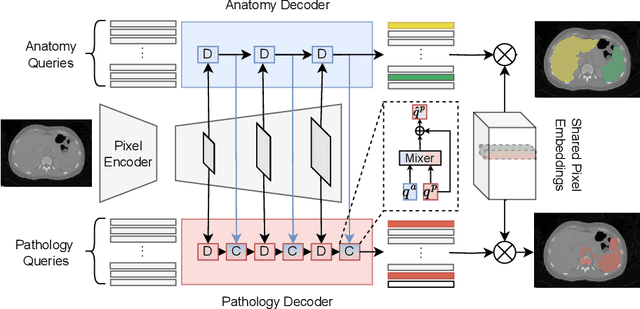
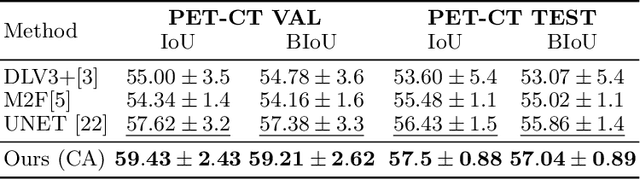
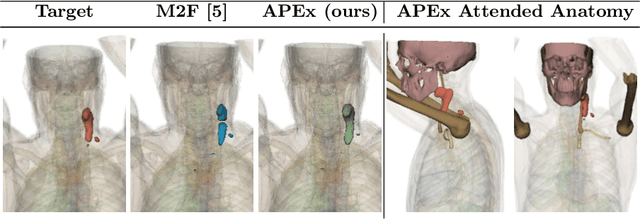
Pathological structures in medical images are typically deviations from the expected anatomy of a patient. While clinicians consider this interplay between anatomy and pathology, recent deep learning algorithms specialize in recognizing either one of the two, rarely considering the patient's body from such a joint perspective. In this paper, we develop a generalist segmentation model that combines anatomical and pathological information, aiming to enhance the segmentation accuracy of pathological features. Our Anatomy-Pathology Exchange (APEx) training utilizes a query-based segmentation transformer which decodes a joint feature space into query-representations for human anatomy and interleaves them via a mixing strategy into the pathology-decoder for anatomy-informed pathology predictions. In doing so, we are able to report the best results across the board on FDG-PET-CT and Chest X-Ray pathology segmentation tasks with a margin of up to 3.3% as compared to strong baseline methods. Code and models will be publicly available at github.com/alexanderjaus/APEx.