 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Data Manifold under the Microscope
Jun 14, 2026A significant gap exists between theory and practice in deep learning. Generalization and approximation error bounds are often derived for simplified models or are too loose to be informative. Many rely on the manifold hypothesis and on geometric regularity such as intrinsic dimension, curvature, and reach. Progress requires insight into data-manifold geometry and suitable benchmarks, yet existing options are polarized: analytic manifolds with known geometry but limited applicability, or real-world datasets where geometry is only coarsely estimable. We introduce a benchmarking framework for studying data geometry. We repurpose and extend dSprites and COIL-20 with additional transformation dimensions and dense, axis-aligned sampling, and pair them with finite-difference estimators that recover curvature, reach, and volume at near-ground-truth accuracy in a regime where general-purpose estimators are unreliable or difficult to deploy. The framework is intended as a controlled testbed, useful as a calibration environment for geometric estimators and a sandbox for probing theoretical assumptions. To illustrate its use, we present two application studies, namely assessing the scaling behavior of the bounds of Genovese et al. and Fefferman et al., and tracking the layer-wise geometry of a $β$-VAE, highlighting the behavior of current bounds and the value of controlled benchmarks for guiding and validating future theory. A reference implementation is available at https://github.com/koulakis/manifold-microscope.
Frame2Freq: Spectral Adapters for Fine-Grained Video Understanding
Feb 21, 2026Adapting image-pretrained backbones to video typically relies on time-domain adapters tuned to a single temporal scale. Our experiments show that these modules pick up static image cues and very fast flicker changes, while overlooking medium-speed motion. Capturing dynamics across multiple time-scales is, however, crucial for fine-grained temporal analysis (i.e., opening vs. closing bottle). To address this, we introduce Frame2Freq -- a family of frequency-aware adapters that perform spectral encoding during image-to-video adaptation of pretrained Vision Foundation Models (VFMs), improving fine-grained action recognition. Frame2Freq uses Fast Fourier Transform (FFT) along time and learns frequency-band specific embeddings that adaptively highlight the most discriminative frequency ranges. Across five fine-grained activity recognition datasets, Frame2Freq outperforms prior PEFT methods and even surpasses fully fine-tuned models on four of them. These results provide encouraging evidence that frequency analysis methods are a powerful tool for modeling temporal dynamics in image-to-video transfer. Code is available at https://github.com/th-nesh/Frame2Freq.
Region-Normalized DPO for Medical Image Segmentation under Noisy Judges
Jan 30, 2026While dense pixel-wise annotations remain the gold standard for medical image segmentation, they are costly to obtain and limit scalability. In contrast, many deployed systems already produce inexpensive automatic quality-control (QC) signals like model agreement, uncertainty measures, or learned mask-quality scores which can be used for further model training without additional ground-truth annotation. However, these signals can be noisy and biased, making preference-based fine-tuning susceptible to harmful updates. We study Direct Preference Optimization (DPO) for segmentation from such noisy judges using proposals generated by a supervised base segmenter trained on a small labeled set. We find that outcomes depend strongly on how preference pairs are mined: selecting the judge's top-ranked proposal can improve peak performance when the judge is reliable, but can amplify harmful errors under weaker judges. We propose Region-Normalized DPO (RN-DPO), a segmentation-aware objective which normalizes preference updates by the size of the disagreement region between masks, reducing the leverage of harmful comparisons and improving optimization stability. Across two medical datasets and multiple regimes, RN-DPO improves sustained performance and stabilizes preference-based fine-tuning, outperforming standard DPO and strong baselines without requiring additional pixel annotations.
CT-GRAPH: Hierarchical Graph Attention Network for Anatomy-Guided CT Report Generation
Aug 07, 2025As medical imaging is central to diagnostic processes, automating the generation of radiology reports has become increasingly relevant to assist radiologists with their heavy workloads. Most current methods rely solely on global image features, failing to capture fine-grained organ relationships crucial for accurate reporting. To this end, we propose CT-GRAPH, a hierarchical graph attention network that explicitly models radiological knowledge by structuring anatomical regions into a graph, linking fine-grained organ features to coarser anatomical systems and a global patient context. Our method leverages pretrained 3D medical feature encoders to obtain global and organ-level features by utilizing anatomical masks. These features are further refined within the graph and then integrated into a large language model to generate detailed medical reports. We evaluate our approach for the task of report generation on the large-scale chest CT dataset CT-RATE. We provide an in-depth analysis of pretrained feature encoders for CT report generation and show that our method achieves a substantial improvement of absolute 7.9\% in F1 score over current state-of-the-art methods. The code is publicly available at https://github.com/hakal104/CT-GRAPH.
Automatic Fine-grained Segmentation-assisted Report Generation
Jul 22, 2025Reliable end-to-end clinical report generation has been a longstanding goal of medical ML research. The end goal for this process is to alleviate radiologists' workloads and provide second opinions to clinicians or patients. Thus, a necessary prerequisite for report generation models is a strong general performance and some type of innate grounding capability, to convince clinicians or patients of the veracity of the generated reports. In this paper, we present ASaRG (\textbf{A}utomatic \textbf{S}egmentation-\textbf{a}ssisted \textbf{R}eport \textbf{G}eneration), an extension of the popular LLaVA architecture that aims to tackle both of these problems. ASaRG proposes to fuse intermediate features and fine-grained segmentation maps created by specialist radiological models into LLaVA's multi-modal projection layer via simple concatenation. With a small number of added parameters, our approach achieves a +0.89\% performance gain ($p=0.012$) in CE F1 score compared to the LLaVA baseline when using only intermediate features, and +2.77\% performance gain ($p<0.001$) when adding a combination of intermediate features and fine-grained segmentation maps. Compared with COMG and ORID, two other report generation methods that utilize segmentations, the performance gain amounts to 6.98\% and 6.28\% in F1 score, respectively. ASaRG is not mutually exclusive with other changes made to the LLaVA architecture, potentially allowing our method to be combined with other advances in the field. Finally, the use of an arbitrary number of segmentations as part of the input demonstrably allows tracing elements of the report to the corresponding segmentation maps and verifying the groundedness of assessments. Our code will be made publicly available at a later date.
Is Visual in-Context Learning for Compositional Medical Tasks within Reach?
Jul 02, 2025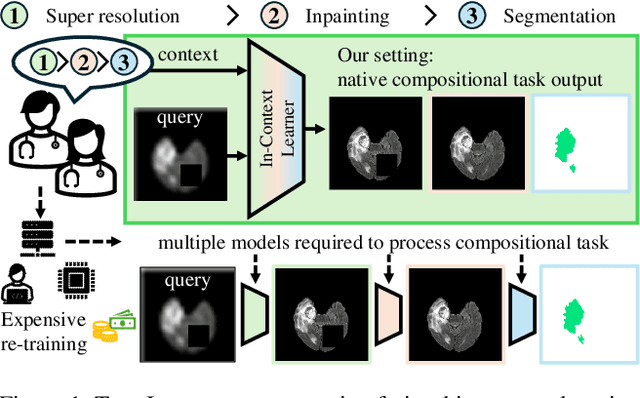
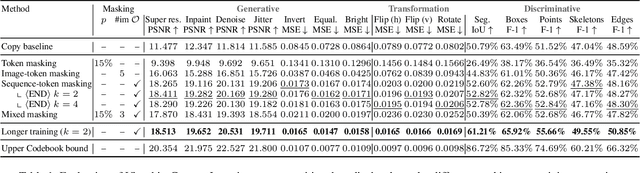
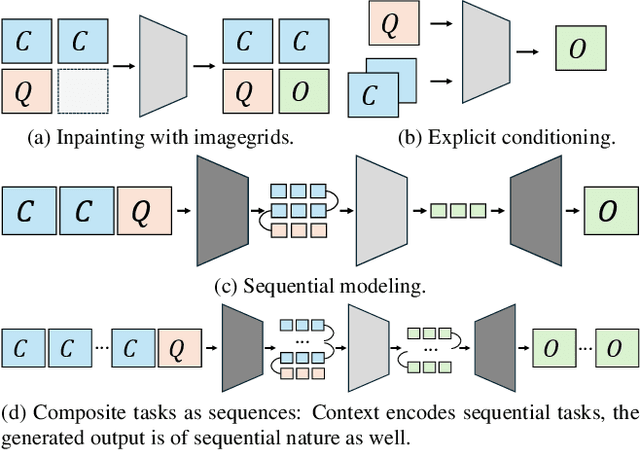
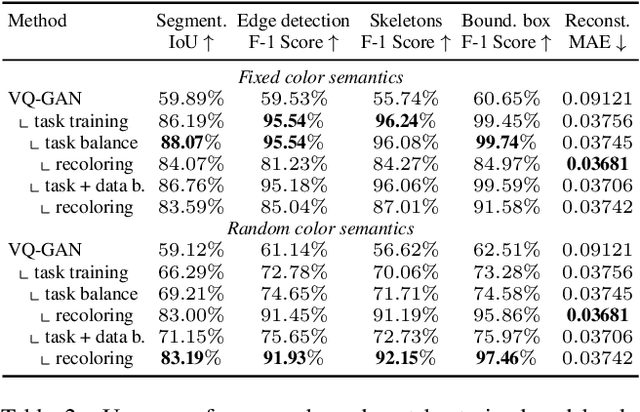
In this paper, we explore the potential of visual in-context learning to enable a single model to handle multiple tasks and adapt to new tasks during test time without re-training. Unlike previous approaches, our focus is on training in-context learners to adapt to sequences of tasks, rather than individual tasks. Our goal is to solve complex tasks that involve multiple intermediate steps using a single model, allowing users to define entire vision pipelines flexibly at test time. To achieve this, we first examine the properties and limitations of visual in-context learning architectures, with a particular focus on the role of codebooks. We then introduce a novel method for training in-context learners using a synthetic compositional task generation engine. This engine bootstraps task sequences from arbitrary segmentation datasets, enabling the training of visual in-context learners for compositional tasks. Additionally, we investigate different masking-based training objectives to gather insights into how to train models better for solving complex, compositional tasks. Our exploration not only provides important insights especially for multi-modal medical task sequences but also highlights challenges that need to be addressed.
Good Enough: Is it Worth Improving your Label Quality?
May 27, 2025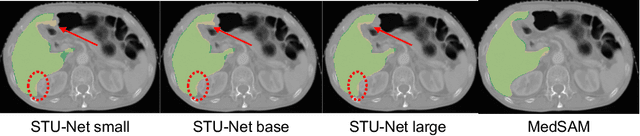
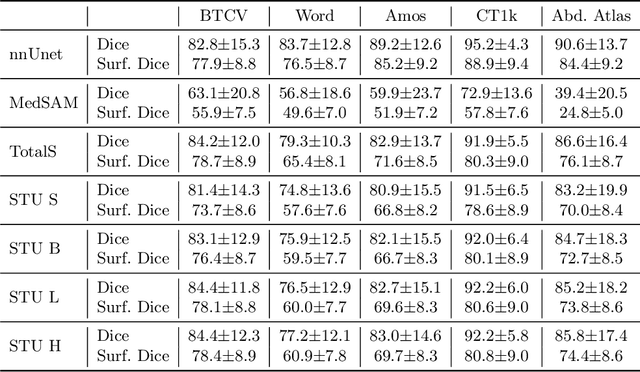
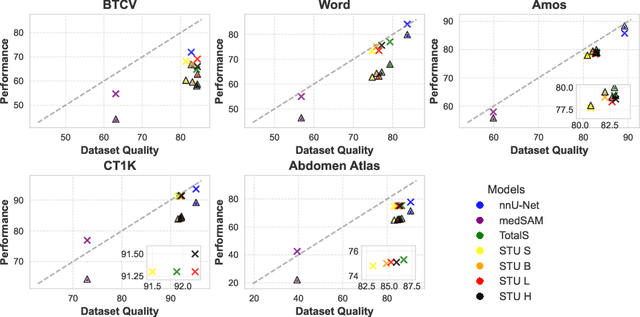
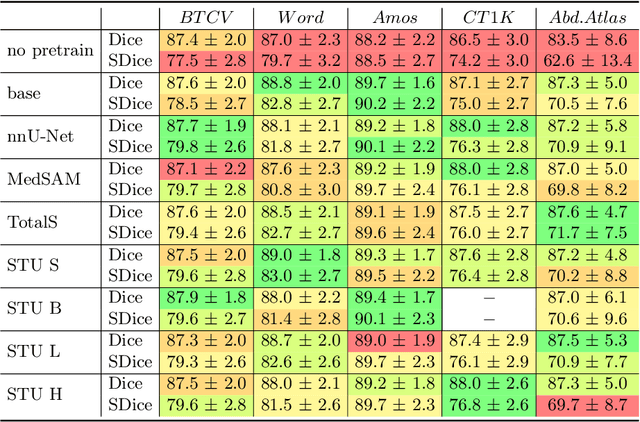
Improving label quality in medical image segmentation is costly, but its benefits remain unclear. We systematically evaluate its impact using multiple pseudo-labeled versions of CT datasets, generated by models like nnU-Net, TotalSegmentator, and MedSAM. Our results show that while higher-quality labels improve in-domain performance, gains remain unclear if below a small threshold. For pre-training, label quality has minimal impact, suggesting that models rather transfer general concepts than detailed annotations. These findings provide guidance on when improving label quality is worth the effort.
Foreign object segmentation in chest x-rays through anatomy-guided shape insertion
Jan 21, 2025



In this paper, we tackle the challenge of instance segmentation for foreign objects in chest radiographs, commonly seen in postoperative follow-ups with stents, pacemakers, or ingested objects in children. The diversity of foreign objects complicates dense annotation, as shown in insufficient existing datasets. To address this, we propose the simple generation of synthetic data through (1) insertion of arbitrary shapes (lines, polygons, ellipses) with varying contrasts and opacities, and (2) cut-paste augmentations from a small set of semi-automatically extracted labels. These insertions are guided by anatomy labels to ensure realistic placements, such as stents appearing only in relevant vessels. Our approach enables networks to segment complex structures with minimal manually labeled data. Notably, it achieves performance comparable to fully supervised models while using 93\% fewer manual annotations.
Every Component Counts: Rethinking the Measure of Success for Medical Semantic Segmentation in Multi-Instance Segmentation Tasks
Oct 24, 2024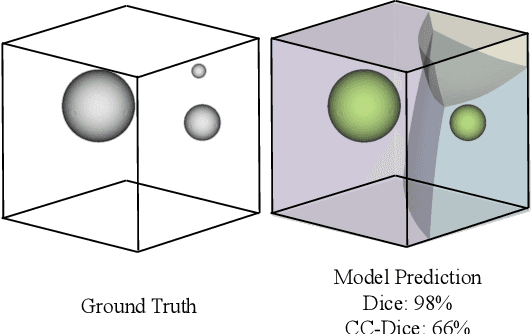
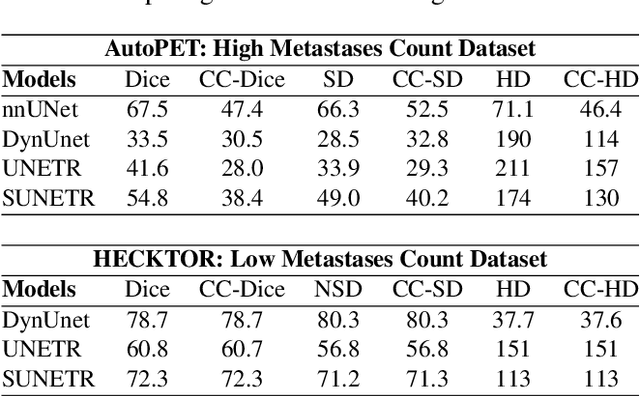
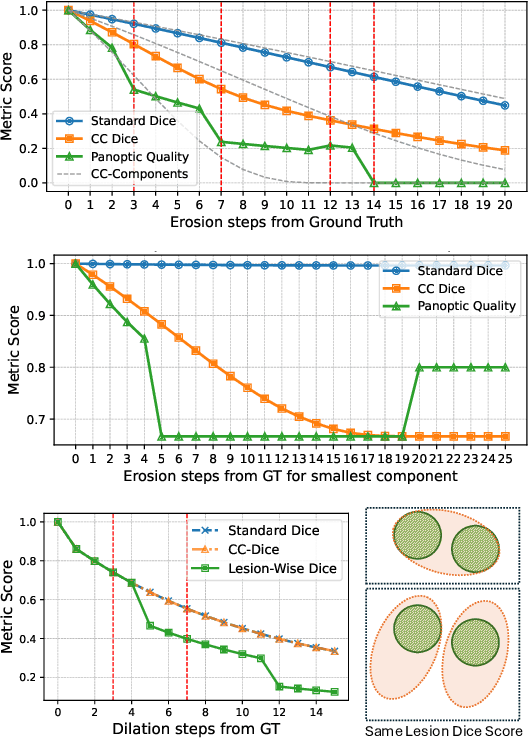
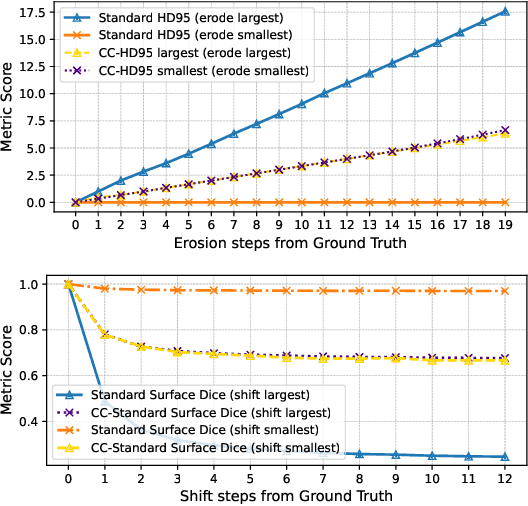
We present Connected-Component~(CC)-Metrics, a novel semantic segmentation evaluation protocol, targeted to align existing semantic segmentation metrics to a multi-instance detection scenario in which each connected component matters. We motivate this setup in the common medical scenario of semantic metastases segmentation in a full-body PET/CT. We show how existing semantic segmentation metrics suffer from a bias towards larger connected components contradicting the clinical assessment of scans in which tumor size and clinical relevance are uncorrelated. To rebalance existing segmentation metrics, we propose to evaluate them on a per-component basis thus giving each tumor the same weight irrespective of its size. To match predictions to ground-truth segments, we employ a proximity-based matching criterion, evaluating common metrics locally at the component of interest. Using this approach, we break free of biases introduced by large metastasis for overlap-based metrics such as Dice or Surface Dice. CC-Metrics also improves distance-based metrics such as Hausdorff Distances which are uninformative for small changes that do not influence the maximum or 95th percentile, and avoids pitfalls introduced by directly combining counting-based metrics with overlap-based metrics as it is done in Panoptic Quality.
De-Identification of Medical Imaging Data: A Comprehensive Tool for Ensuring Patient Privacy
Oct 16, 2024



Medical data employed in research frequently comprises sensitive patient health information (PHI), which is subject to rigorous legal frameworks such as the General Data Protection Regulation (GDPR) or the Health Insurance Portability and Accountability Act (HIPAA). Consequently, these types of data must be pseudonymized prior to utilisation, which presents a significant challenge for many researchers. Given the vast array of medical data, it is necessary to employ a variety of de-identification techniques. To facilitate the anonymization process for medical imaging data, we have developed an open-source tool that can be used to de-identify DICOM magnetic resonance images, computer tomography images, whole slide images and magnetic resonance twix raw data. Furthermore, the implementation of a neural network enables the removal of text within the images. The proposed tool automates an elaborate anonymization pipeline for multiple types of inputs, reducing the need for additional tools used for de-identification of imaging data. We make our code publicly available at https://github.com/code-lukas/medical_image_deidentification.