 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Intrinsic Medical Task Relationships: A Contrastive Learning Perspective
Apr 07, 2026While much of the medical computer vision community has focused on advancing performance for specific tasks, the underlying relationships between tasks, i.e., how they relate, overlap, or differ on a representational level, remain largely unexplored. Our work explores these intrinsic relationships between medical vision tasks, specifically, we investigate 30 tasks, such as semantic tasks (e.g., segmentation and detection), image generative tasks (e.g., denoising, inpainting, or colorization), and image transformation tasks (e.g., geometric transformations). Our goal is to probe whether a data-driven representation space can capture an underlying structure of tasks across a variety of 39 datasets from wildly different medical imaging modalities, including computed tomography, magnetic resonance, electron microscopy, X-ray ultrasound and more. By revealing how tasks relate to one another, we aim to provide insights into their fundamental properties and interconnectedness. To this end, we introduce Task-Contrastive Learning (TaCo), a contrastive learning framework designed to embed tasks into a shared representation space. Through TaCo, we map these heterogeneous tasks from different modalities into a joint space and analyze their properties: identifying which tasks are distinctly represented, which blend together, and how iterative alterations to tasks are reflected in the embedding space. Our work provides a foundation for understanding the intrinsic structure of medical vision tasks, offering a deeper understanding of task similarities and their interconnected properties in embedding spaces.
Is Visual in-Context Learning for Compositional Medical Tasks within Reach?
Jul 02, 2025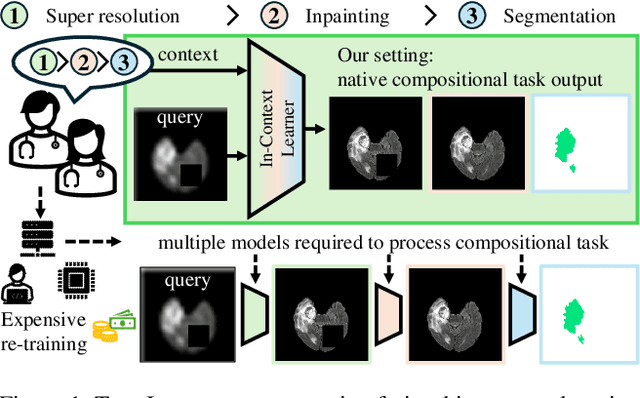
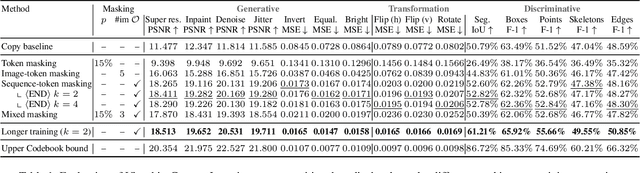
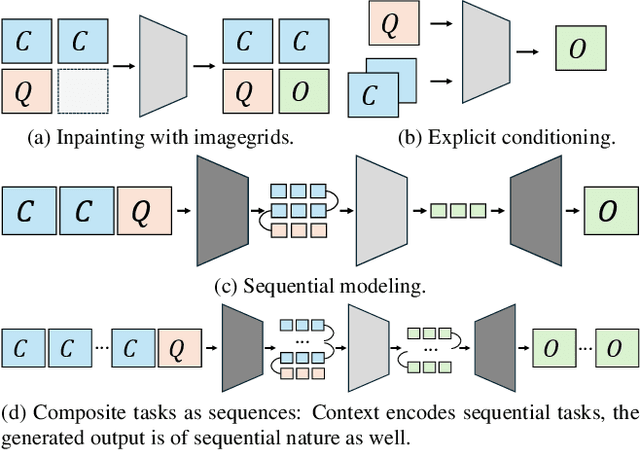
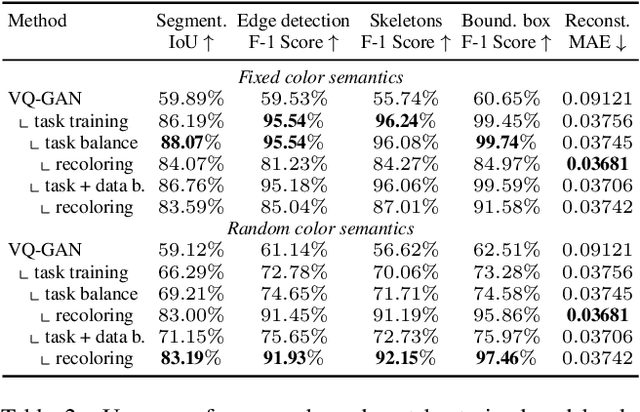
In this paper, we explore the potential of visual in-context learning to enable a single model to handle multiple tasks and adapt to new tasks during test time without re-training. Unlike previous approaches, our focus is on training in-context learners to adapt to sequences of tasks, rather than individual tasks. Our goal is to solve complex tasks that involve multiple intermediate steps using a single model, allowing users to define entire vision pipelines flexibly at test time. To achieve this, we first examine the properties and limitations of visual in-context learning architectures, with a particular focus on the role of codebooks. We then introduce a novel method for training in-context learners using a synthetic compositional task generation engine. This engine bootstraps task sequences from arbitrary segmentation datasets, enabling the training of visual in-context learners for compositional tasks. Additionally, we investigate different masking-based training objectives to gather insights into how to train models better for solving complex, compositional tasks. Our exploration not only provides important insights especially for multi-modal medical task sequences but also highlights challenges that need to be addressed.
Good Enough: Is it Worth Improving your Label Quality?
May 27, 2025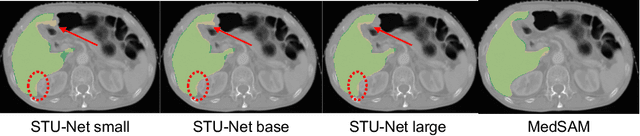
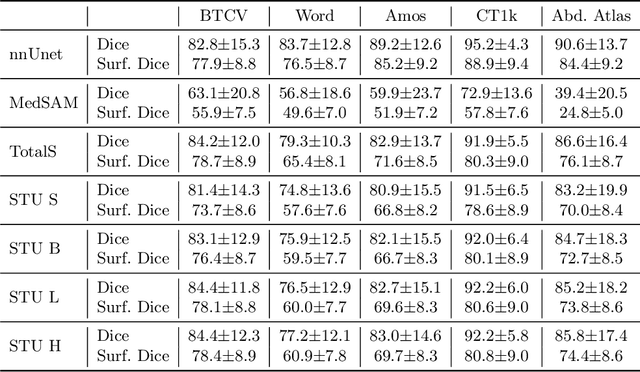
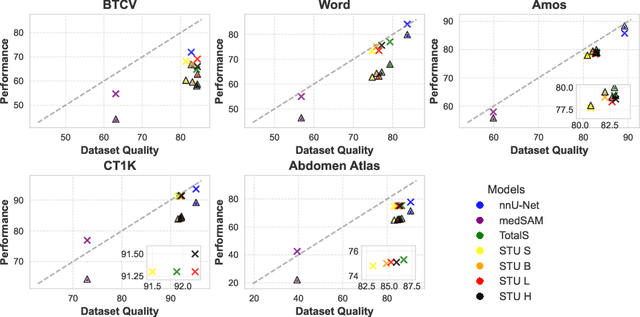
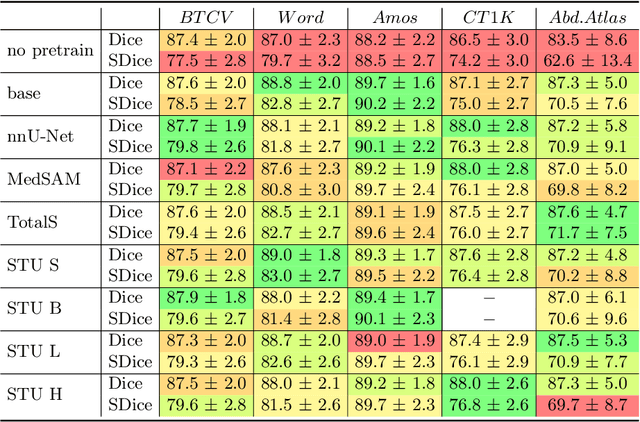
Improving label quality in medical image segmentation is costly, but its benefits remain unclear. We systematically evaluate its impact using multiple pseudo-labeled versions of CT datasets, generated by models like nnU-Net, TotalSegmentator, and MedSAM. Our results show that while higher-quality labels improve in-domain performance, gains remain unclear if below a small threshold. For pre-training, label quality has minimal impact, suggesting that models rather transfer general concepts than detailed annotations. These findings provide guidance on when improving label quality is worth the effort.
OmniFall: A Unified Staged-to-Wild Benchmark for Human Fall Detection
May 26, 2025Current video-based fall detection research mostly relies on small, staged datasets with significant domain biases concerning background, lighting, and camera setup resulting in unknown real-world performance. We introduce OmniFall, unifying eight public fall detection datasets (roughly 14 h of recordings, roughly 42 h of multiview data, 101 subjects, 29 camera views) under a consistent ten-class taxonomy with standardized evaluation protocols. Our benchmark provides complete video segmentation labels and enables fair cross-dataset comparison previously impossible with incompatible annotation schemes. For real-world evaluation we curate OOPS-Fall from genuine accident videos and establish a staged-to-wild protocol measuring generalization from controlled to uncontrolled environments. Experiments with frozen pre-trained backbones such as I3D or VideoMAE reveal significant performance gaps between in-distribution and in-the-wild scenarios, highlighting critical challenges in developing robust fall detection systems. OmniFall Dataset at https://huggingface.co/datasets/simplexsigil2/omnifall , Code at https://github.com/simplexsigil/omnifall-experiments
Efficient MedSAMs: Segment Anything in Medical Images on Laptop
Dec 20, 2024


Promptable segmentation foundation models have emerged as a transformative approach to addressing the diverse needs in medical images, but most existing models require expensive computing, posing a big barrier to their adoption in clinical practice. In this work, we organized the first international competition dedicated to promptable medical image segmentation, featuring a large-scale dataset spanning nine common imaging modalities from over 20 different institutions. The top teams developed lightweight segmentation foundation models and implemented an efficient inference pipeline that substantially reduced computational requirements while maintaining state-of-the-art segmentation accuracy. Moreover, the post-challenge phase advanced the algorithms through the design of performance booster and reproducibility tasks, resulting in improved algorithms and validated reproducibility of the winning solution. Furthermore, the best-performing algorithms have been incorporated into the open-source software with a user-friendly interface to facilitate clinical adoption. The data and code are publicly available to foster the further development of medical image segmentation foundation models and pave the way for impactful real-world applications.
Every Component Counts: Rethinking the Measure of Success for Medical Semantic Segmentation in Multi-Instance Segmentation Tasks
Oct 24, 2024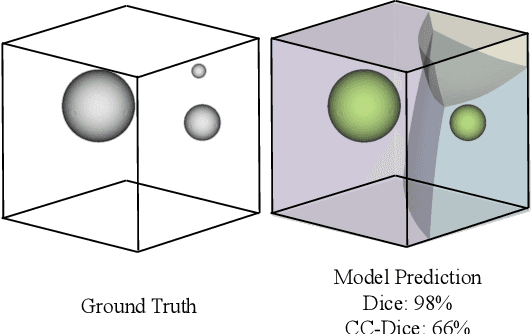
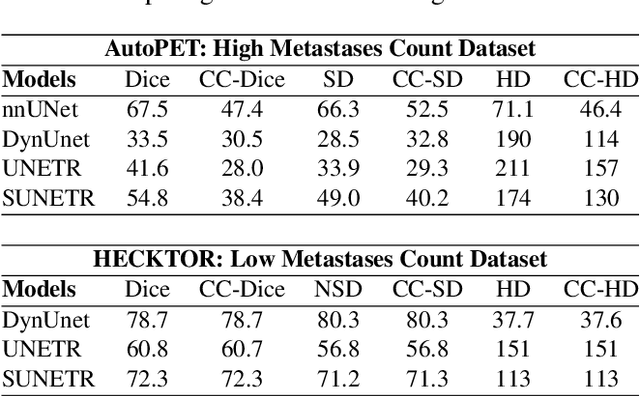
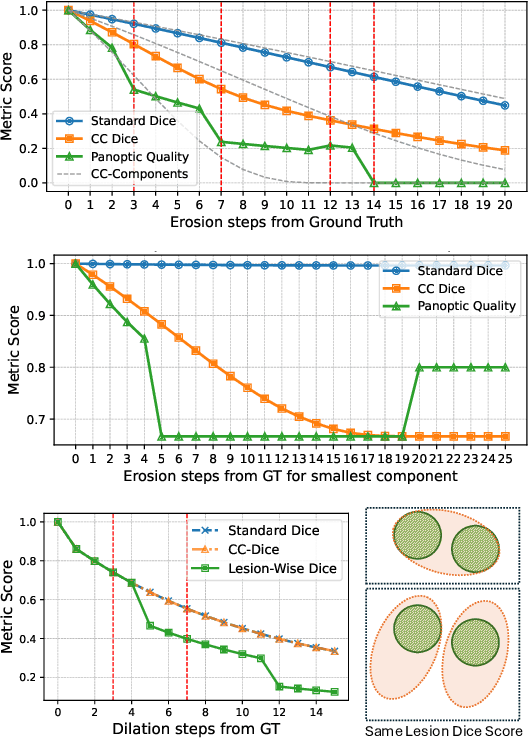
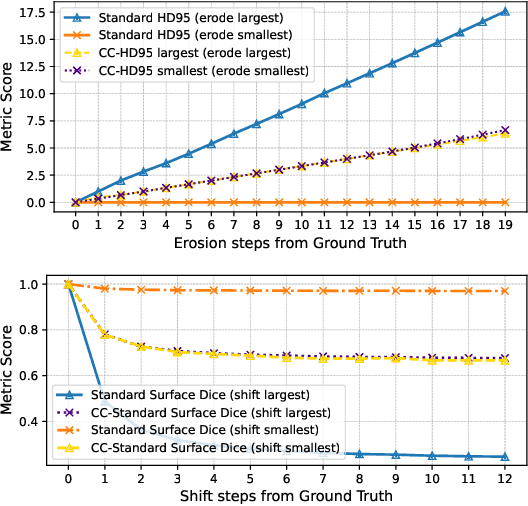
We present Connected-Component~(CC)-Metrics, a novel semantic segmentation evaluation protocol, targeted to align existing semantic segmentation metrics to a multi-instance detection scenario in which each connected component matters. We motivate this setup in the common medical scenario of semantic metastases segmentation in a full-body PET/CT. We show how existing semantic segmentation metrics suffer from a bias towards larger connected components contradicting the clinical assessment of scans in which tumor size and clinical relevance are uncorrelated. To rebalance existing segmentation metrics, we propose to evaluate them on a per-component basis thus giving each tumor the same weight irrespective of its size. To match predictions to ground-truth segments, we employ a proximity-based matching criterion, evaluating common metrics locally at the component of interest. Using this approach, we break free of biases introduced by large metastasis for overlap-based metrics such as Dice or Surface Dice. CC-Metrics also improves distance-based metrics such as Hausdorff Distances which are uninformative for small changes that do not influence the maximum or 95th percentile, and avoids pitfalls introduced by directly combining counting-based metrics with overlap-based metrics as it is done in Panoptic Quality.
LIMIS: Towards Language-based Interactive Medical Image Segmentation
Oct 22, 2024Within this work, we introduce LIMIS: The first purely language-based interactive medical image segmentation model. We achieve this by adapting Grounded SAM to the medical domain and designing a language-based model interaction strategy that allows radiologists to incorporate their knowledge into the segmentation process. LIMIS produces high-quality initial segmentation masks by leveraging medical foundation models and allows users to adapt segmentation masks using only language, opening up interactive segmentation to scenarios where physicians require using their hands for other tasks. We evaluate LIMIS on three publicly available medical datasets in terms of performance and usability with experts from the medical domain confirming its high-quality segmentation masks and its interactive usability.
Rethinking Annotator Simulation: Realistic Evaluation of Whole-Body PET Lesion Interactive Segmentation Methods
Apr 02, 2024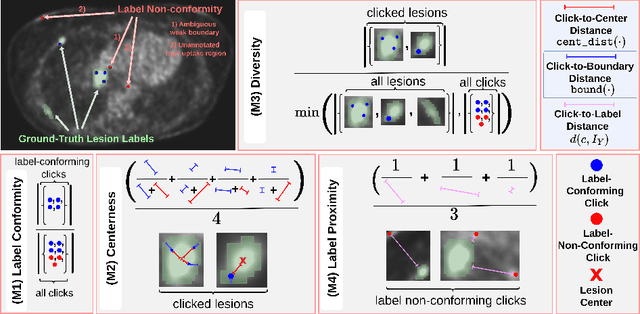
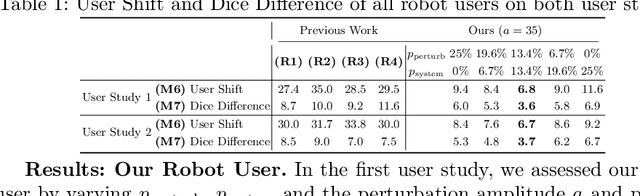
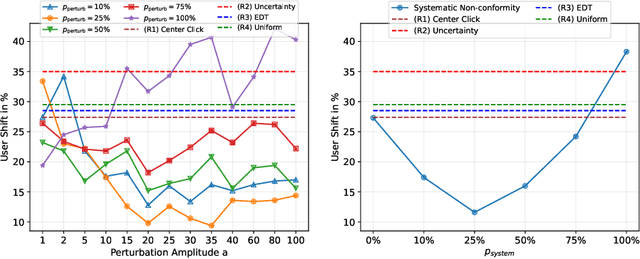
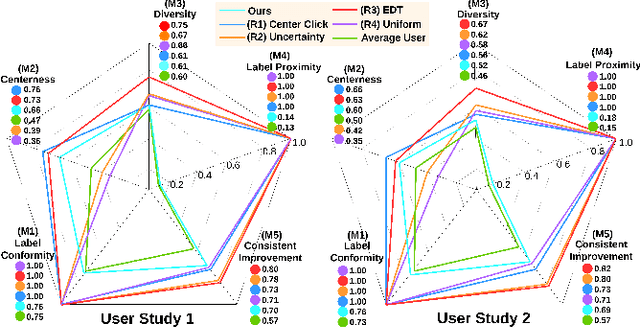
Interactive segmentation plays a crucial role in accelerating the annotation, particularly in domains requiring specialized expertise such as nuclear medicine. For example, annotating lesions in whole-body Positron Emission Tomography (PET) images can require over an hour per volume. While previous works evaluate interactive segmentation models through either real user studies or simulated annotators, both approaches present challenges. Real user studies are expensive and often limited in scale, while simulated annotators, also known as robot users, tend to overestimate model performance due to their idealized nature. To address these limitations, we introduce four evaluation metrics that quantify the user shift between real and simulated annotators. In an initial user study involving four annotators, we assess existing robot users using our proposed metrics and find that robot users significantly deviate in performance and annotation behavior compared to real annotators. Based on these findings, we propose a more realistic robot user that reduces the user shift by incorporating human factors such as click variation and inter-annotator disagreement. We validate our robot user in a second user study, involving four other annotators, and show it consistently reduces the simulated-to-real user shift compared to traditional robot users. By employing our robot user, we can conduct more large-scale and cost-efficient evaluations of interactive segmentation models, while preserving the fidelity of real user studies. Our implementation is based on MONAI Label and will be made publicly available.
Sliding Window FastEdit: A Framework for Lesion Annotation in Whole-body PET Images
Nov 24, 2023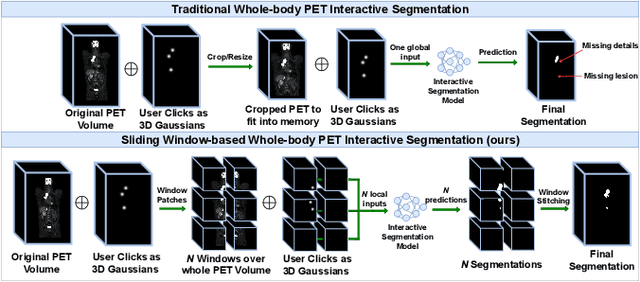
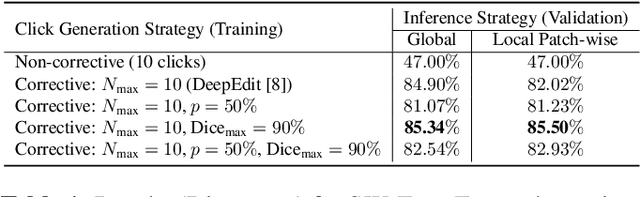
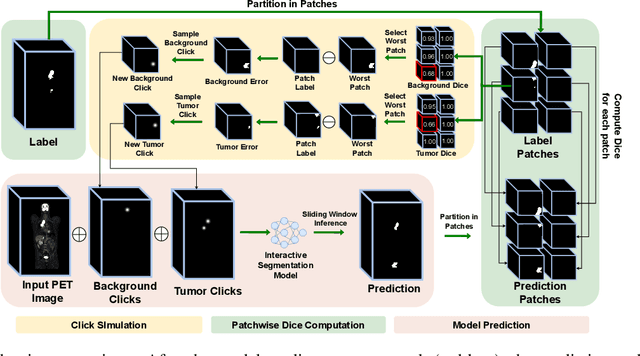
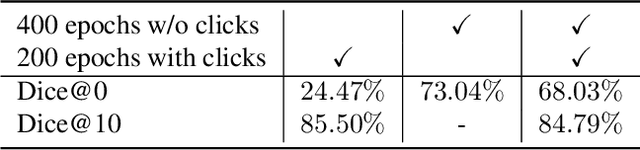
Deep learning has revolutionized the accurate segmentation of diseases in medical imaging. However, achieving such results requires training with numerous manual voxel annotations. This requirement presents a challenge for whole-body Positron Emission Tomography (PET) imaging, where lesions are scattered throughout the body. To tackle this problem, we introduce SW-FastEdit - an interactive segmentation framework that accelerates the labeling by utilizing only a few user clicks instead of voxelwise annotations. While prior interactive models crop or resize PET volumes due to memory constraints, we use the complete volume with our sliding window-based interactive scheme. Our model outperforms existing non-sliding window interactive models on the AutoPET dataset and generalizes to the previously unseen HECKTOR dataset. A user study revealed that annotators achieve high-quality predictions with only 10 click iterations and a low perceived NASA-TLX workload. Our framework is implemented using MONAI Label and is available: https://github.com/matt3o/AutoPET2-Submission/
Deep Interactive Segmentation of Medical Images: A Systematic Review and Taxonomy
Nov 23, 2023Interactive segmentation is a crucial research area in medical image analysis aiming to boost the efficiency of costly annotations by incorporating human feedback. This feedback takes the form of clicks, scribbles, or masks and allows for iterative refinement of the model output so as to efficiently guide the system towards the desired behavior. In recent years, deep learning-based approaches have propelled results to a new level causing a rapid growth in the field with 121 methods proposed in the medical imaging domain alone. In this review, we provide a structured overview of this emerging field featuring a comprehensive taxonomy, a systematic review of existing methods, and an in-depth analysis of current practices. Based on these contributions, we discuss the challenges and opportunities in the field. For instance, we find that there is a severe lack of comparison across methods which needs to be tackled by standardized baselines and benchmarks.