 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Annotator Simulation: Realistic Evaluation of Whole-Body PET Lesion Interactive Segmentation Methods
Paper and Code
Apr 02, 2024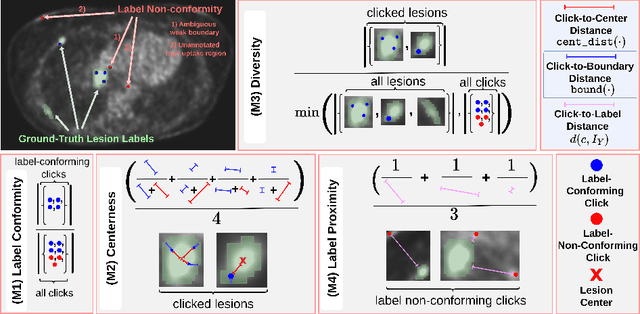
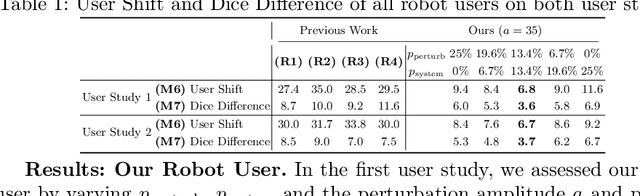
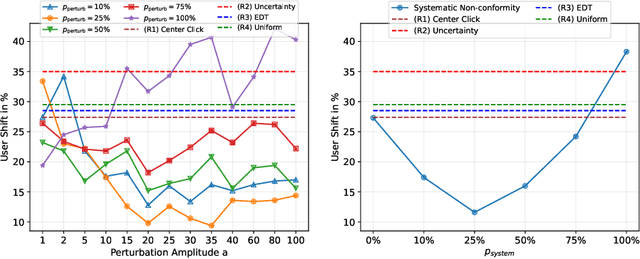
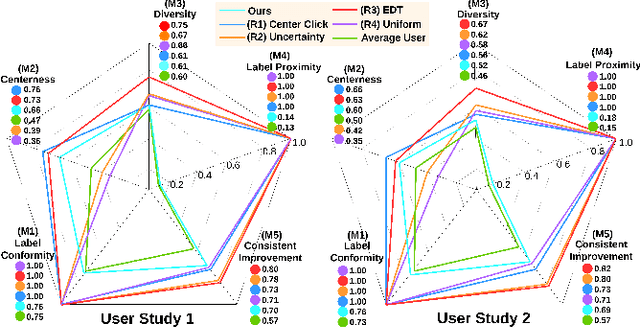
Interactive segmentation plays a crucial role in accelerating the annotation, particularly in domains requiring specialized expertise such as nuclear medicine. For example, annotating lesions in whole-body Positron Emission Tomography (PET) images can require over an hour per volume. While previous works evaluate interactive segmentation models through either real user studies or simulated annotators, both approaches present challenges. Real user studies are expensive and often limited in scale, while simulated annotators, also known as robot users, tend to overestimate model performance due to their idealized nature. To address these limitations, we introduce four evaluation metrics that quantify the user shift between real and simulated annotators. In an initial user study involving four annotators, we assess existing robot users using our proposed metrics and find that robot users significantly deviate in performance and annotation behavior compared to real annotators. Based on these findings, we propose a more realistic robot user that reduces the user shift by incorporating human factors such as click variation and inter-annotator disagreement. We validate our robot user in a second user study, involving four other annotators, and show it consistently reduces the simulated-to-real user shift compared to traditional robot users. By employing our robot user, we can conduct more large-scale and cost-efficient evaluations of interactive segmentation models, while preserving the fidelity of real user studies. Our implementation is based on MONAI Label and will be made publicly available.