 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptTracer: Interactive Analysis of Concept Saliency and Selectivity in Neural Representations
Apr 08, 2026Neural networks deliver impressive predictive performance across a variety of tasks, but they are often opaque in their decision-making processes. Despite a growing interest in mechanistic interpretability, tools for systematically exploring the representations learned by neural networks in general, and tabular foundation models in particular, remain limited. In this work, we introduce ConceptTracer, an interactive application for analyzing neural representations through the lens of human-interpretable concepts. ConceptTracer integrates two information-theoretic measures that quantify concept saliency and selectivity, enabling researchers and practitioners to identify neurons that respond strongly to individual concepts. We demonstrate the utility of ConceptTracer on representations learned by TabPFN and show that our approach facilitates the discovery of interpretable neurons. Together, these capabilities provide a practical framework for investigating how neural networks like TabPFN encode concept-level information. ConceptTracer is available at https://github.com/ml-lab-htw/concept-tracer.
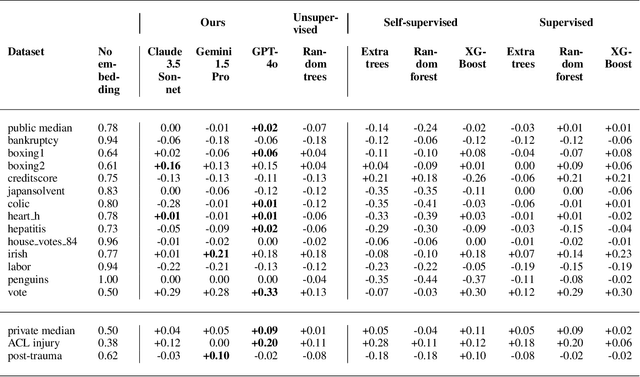
Embedding World Knowledge into Tabular Models: Towards Best Practices for Embedding Pipeline Design
Mar 18, 2026Embeddings are a powerful way to enrich data-driven machine learning models with the world knowledge of large language models (LLMs). Yet, there is limited evidence on how to design effective LLM-based embedding pipelines for tabular prediction. In this work, we systematically benchmark 256 pipeline configurations, covering 8 preprocessing strategies, 16 embedding models, and 2 downstream models. Our results show that it strongly depends on the specific pipeline design whether incorporating the prior knowledge of LLMs improves the predictive performance. In general, concatenating embeddings tends to outperform replacing the original columns with embeddings. Larger embedding models tend to yield better results, while public leaderboard rankings and model popularity are poor performance indicators. Finally, gradient boosting decision trees tend to be strong downstream models. Our findings provide researchers and practitioners with guidance for building more effective embedding pipelines for tabular prediction tasks.
LLMStructBench: Benchmarking Large Language Model Structured Data Extraction
Feb 16, 2026We present LLMStructBench, a novel benchmark for evaluating Large Language Models (LLMs) on extracting structured data and generating valid JavaScript Object Notation (JSON) outputs from natural-language text. Our open dataset comprises diverse, manually verified parsing scenarios of varying complexity and enables systematic testing across 22 models and five prompting strategies. We further introduce complementary performance metrics that capture both token-level accuracy and document-level validity, facilitating rigorous comparison of model, size, and prompting effects on parsing reliability. In particular, we show that choosing the right prompting strategy is more important than standard attributes such as model size. This especially ensures structural validity for smaller or less reliable models but increase the number of semantic errors. Our benchmark suite is an step towards future research in the area of LLM applied to parsing or Extract, Transform and Load (ETL) applications.
In Search of Grandmother Cells: Tracing Interpretable Neurons in Tabular Representations
Jan 07, 2026Foundation models are powerful yet often opaque in their decision-making. A topic of continued interest in both neuroscience and artificial intelligence is whether some neurons behave like grandmother cells, i.e., neurons that are inherently interpretable because they exclusively respond to single concepts. In this work, we propose two information-theoretic measures that quantify the neuronal saliency and selectivity for single concepts. We apply these metrics to the representations of TabPFN, a tabular foundation model, and perform a simple search across neuron-concept pairs to find the most salient and selective pair. Our analysis provides the first evidence that some neurons in such models show moderate, statistically significant saliency and selectivity for high-level concepts. These findings suggest that interpretable neurons can emerge naturally and that they can, in some cases, be identified without resorting to more complex interpretability techniques.
Is Visual in-Context Learning for Compositional Medical Tasks within Reach?
Jul 02, 2025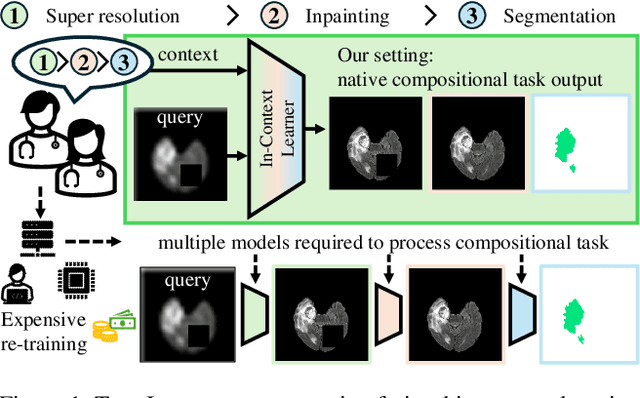
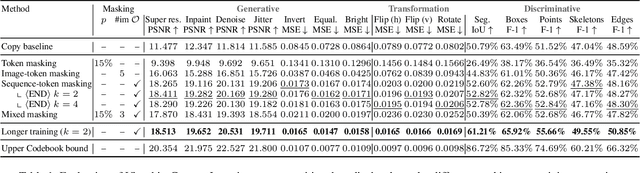
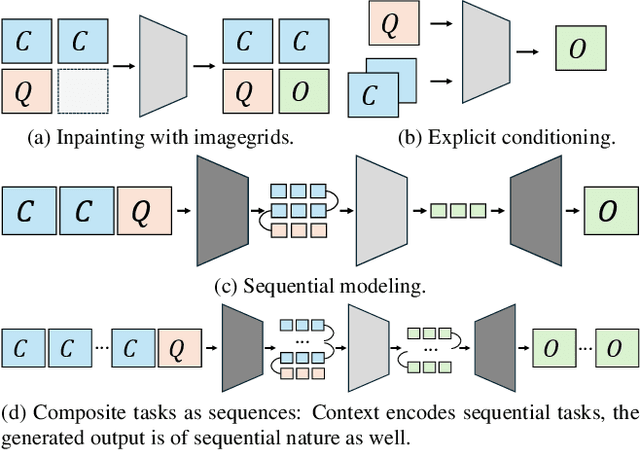
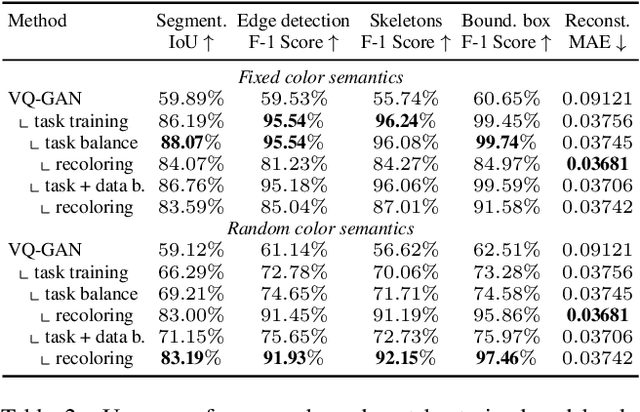
In this paper, we explore the potential of visual in-context learning to enable a single model to handle multiple tasks and adapt to new tasks during test time without re-training. Unlike previous approaches, our focus is on training in-context learners to adapt to sequences of tasks, rather than individual tasks. Our goal is to solve complex tasks that involve multiple intermediate steps using a single model, allowing users to define entire vision pipelines flexibly at test time. To achieve this, we first examine the properties and limitations of visual in-context learning architectures, with a particular focus on the role of codebooks. We then introduce a novel method for training in-context learners using a synthetic compositional task generation engine. This engine bootstraps task sequences from arbitrary segmentation datasets, enabling the training of visual in-context learners for compositional tasks. Additionally, we investigate different masking-based training objectives to gather insights into how to train models better for solving complex, compositional tasks. Our exploration not only provides important insights especially for multi-modal medical task sequences but also highlights challenges that need to be addressed.
Robust Weight Imprinting: Insights from Neural Collapse and Proxy-Based Aggregation
Mar 18, 2025The capacity of a foundation model allows for adaptation to new downstream tasks. Weight imprinting is a universal and efficient method to fulfill this purpose. It has been reinvented several times, but it has not been systematically studied. In this paper, we propose a framework for imprinting, identifying three main components: generation, normalization, and aggregation. This allows us to conduct an in-depth analysis of imprinting and a comparison of the existing work. We reveal the benefits of representing novel data with multiple proxies in the generation step and show the importance of proper normalization. We determine those proxies through clustering and propose a novel variant of imprinting that outperforms previous work. We motivate this by the neural collapse phenomenon -- an important connection that we can draw for the first time. Our results show an increase of up to 4% in challenging scenarios with complex data distributions for new classes.
Feedback-driven object detection and iterative model improvement
Nov 29, 2024


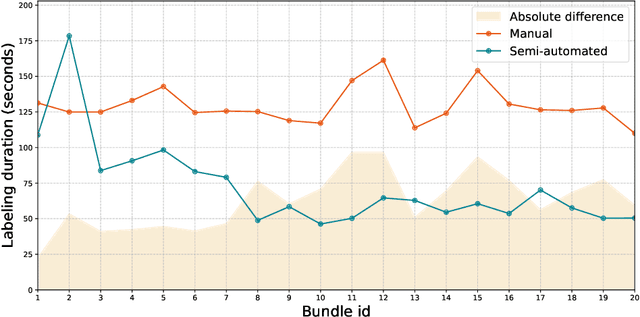
Automated object detection has become increasingly valuable across diverse applications, yet efficient, high-quality annotation remains a persistent challenge. In this paper, we present the development and evaluation of a platform designed to interactively improve object detection models. The platform allows uploading and annotating images as well as fine-tuning object detection models. Users can then manually review and refine annotations, further creating improved snapshots that are used for automatic object detection on subsequent image uploads - a process we refer to as semi-automatic annotation resulting in a significant gain in annotation efficiency. Whereas iterative refinement of model results to speed up annotation has become common practice, we are the first to quantitatively evaluate its benefits with respect to time, effort, and interaction savings. Our experimental results show clear evidence for a significant time reduction of up to 53% for semi-automatic compared to manual annotation. Importantly, these efficiency gains did not compromise annotation quality, while matching or occasionally even exceeding the accuracy of manual annotations. These findings demonstrate the potential of our lightweight annotation platform for creating high-quality object detection datasets and provide best practices to guide future development of annotation platforms. The platform is open-source, with the frontend and backend repositories available on GitHub.
"Oh LLM, I'm Asking Thee, Please Give Me a Decision Tree": Zero-Shot Decision Tree Induction and Embedding with Large Language Models
Sep 27, 2024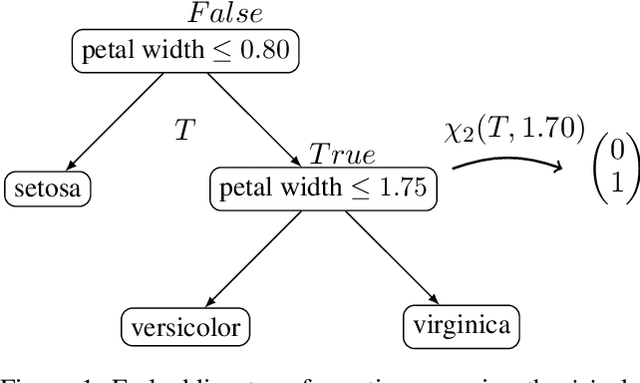
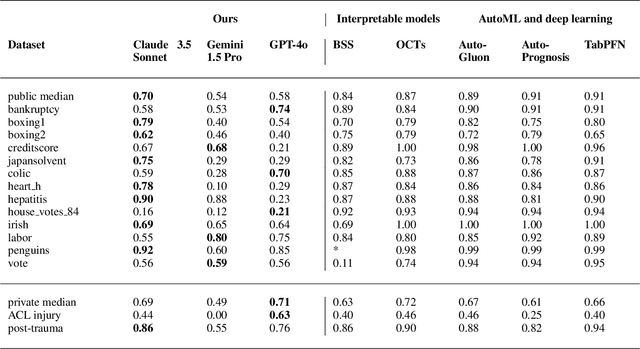
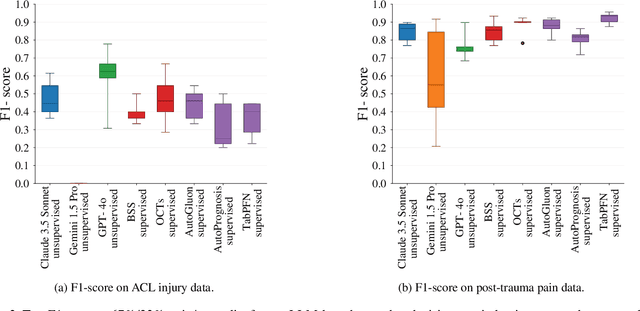
Large language models (LLMs) provide powerful means to leverage prior knowledge for predictive modeling when data is limited. In this work, we demonstrate how LLMs can use their compressed world knowledge to generate intrinsically interpretable machine learning models, i.e., decision trees, without any training data. We find that these zero-shot decision trees can surpass data-driven trees on some small-sized tabular datasets and that embeddings derived from these trees perform on par with data-driven tree-based embeddings on average. Our knowledge-driven decision tree induction and embedding approaches therefore serve as strong new baselines for data-driven machine learning methods in the low-data regime.
PMLBmini: A Tabular Classification Benchmark Suite for Data-Scarce Applications
Sep 03, 2024



In practice, we are often faced with small-sized tabular data. However, current tabular benchmarks are not geared towards data-scarce applications, making it very difficult to derive meaningful conclusions from empirical comparisons. We introduce PMLBmini, a tabular benchmark suite of 44 binary classification datasets with sample sizes $\leq$ 500. We use our suite to thoroughly evaluate current automated machine learning (AutoML) frameworks, off-the-shelf tabular deep neural networks, as well as classical linear models in the low-data regime. Our analysis reveals that state-of-the-art AutoML and deep learning approaches often fail to appreciably outperform even a simple logistic regression baseline, but we also identify scenarios where AutoML and deep learning methods are indeed reasonable to apply. Our benchmark suite, available on https://github.com/RicardoKnauer/TabMini , allows researchers and practitioners to analyze their own methods and challenge their data efficiency.
Squeezing Lemons with Hammers: An Evaluation of AutoML and Tabular Deep Learning for Data-Scarce Classification Applications
May 13, 2024



Many industry verticals are confronted with small-sized tabular data. In this low-data regime, it is currently unclear whether the best performance can be expected from simple baselines, or more complex machine learning approaches that leverage meta-learning and ensembling. On 44 tabular classification datasets with sample sizes $\leq$ 500, we find that L2-regularized logistic regression performs similar to state-of-the-art automated machine learning (AutoML) frameworks (AutoPrognosis, AutoGluon) and off-the-shelf deep neural networks (TabPFN, HyperFast) on the majority of the benchmark datasets. We therefore recommend to consider logistic regression as the first choice for data-scarce applications with tabular data and provide practitioners with best practices for further method selection.