Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Oh LLM, I'm Asking Thee, Please Give Me a Decision Tree": Zero-Shot Decision Tree Induction and Embedding with Large Language Models
Paper and Code
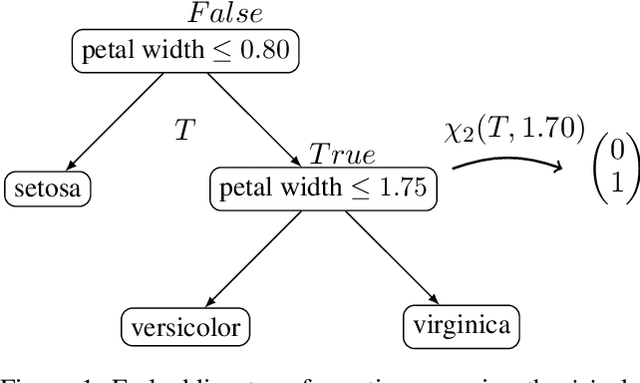
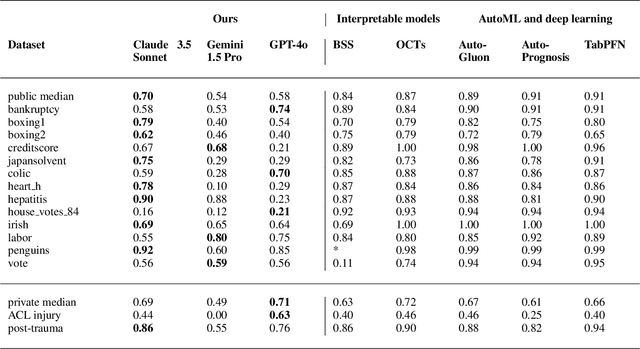
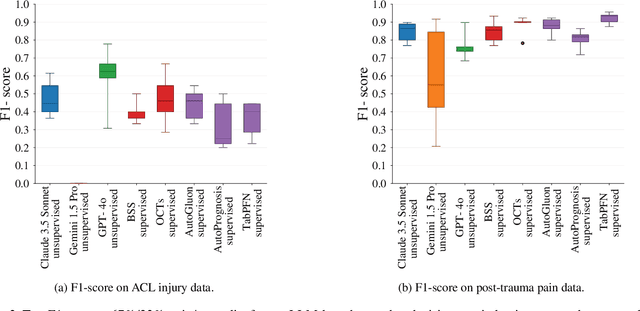
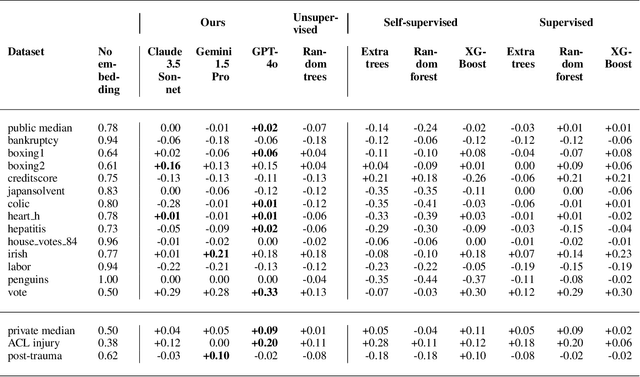
Large language models (LLMs) provide powerful means to leverage prior knowledge for predictive modeling when data is limited. In this work, we demonstrate how LLMs can use their compressed world knowledge to generate intrinsically interpretable machine learning models, i.e., decision trees, without any training data. We find that these zero-shot decision trees can surpass data-driven trees on some small-sized tabular datasets and that embeddings derived from these trees perform on par with data-driven tree-based embeddings on average. Our knowledge-driven decision tree induction and embedding approaches therefore serve as strong new baselines for data-driven machine learning methods in the low-data regime.
View paper on