 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConceptTracer: Interactive Analysis of Concept Saliency and Selectivity in Neural Representations
Apr 08, 2026Neural networks deliver impressive predictive performance across a variety of tasks, but they are often opaque in their decision-making processes. Despite a growing interest in mechanistic interpretability, tools for systematically exploring the representations learned by neural networks in general, and tabular foundation models in particular, remain limited. In this work, we introduce ConceptTracer, an interactive application for analyzing neural representations through the lens of human-interpretable concepts. ConceptTracer integrates two information-theoretic measures that quantify concept saliency and selectivity, enabling researchers and practitioners to identify neurons that respond strongly to individual concepts. We demonstrate the utility of ConceptTracer on representations learned by TabPFN and show that our approach facilitates the discovery of interpretable neurons. Together, these capabilities provide a practical framework for investigating how neural networks like TabPFN encode concept-level information. ConceptTracer is available at https://github.com/ml-lab-htw/concept-tracer.
Embedding World Knowledge into Tabular Models: Towards Best Practices for Embedding Pipeline Design
Mar 18, 2026Embeddings are a powerful way to enrich data-driven machine learning models with the world knowledge of large language models (LLMs). Yet, there is limited evidence on how to design effective LLM-based embedding pipelines for tabular prediction. In this work, we systematically benchmark 256 pipeline configurations, covering 8 preprocessing strategies, 16 embedding models, and 2 downstream models. Our results show that it strongly depends on the specific pipeline design whether incorporating the prior knowledge of LLMs improves the predictive performance. In general, concatenating embeddings tends to outperform replacing the original columns with embeddings. Larger embedding models tend to yield better results, while public leaderboard rankings and model popularity are poor performance indicators. Finally, gradient boosting decision trees tend to be strong downstream models. Our findings provide researchers and practitioners with guidance for building more effective embedding pipelines for tabular prediction tasks.
In Search of Grandmother Cells: Tracing Interpretable Neurons in Tabular Representations
Jan 07, 2026Foundation models are powerful yet often opaque in their decision-making. A topic of continued interest in both neuroscience and artificial intelligence is whether some neurons behave like grandmother cells, i.e., neurons that are inherently interpretable because they exclusively respond to single concepts. In this work, we propose two information-theoretic measures that quantify the neuronal saliency and selectivity for single concepts. We apply these metrics to the representations of TabPFN, a tabular foundation model, and perform a simple search across neuron-concept pairs to find the most salient and selective pair. Our analysis provides the first evidence that some neurons in such models show moderate, statistically significant saliency and selectivity for high-level concepts. These findings suggest that interpretable neurons can emerge naturally and that they can, in some cases, be identified without resorting to more complex interpretability techniques.
"Oh LLM, I'm Asking Thee, Please Give Me a Decision Tree": Zero-Shot Decision Tree Induction and Embedding with Large Language Models
Sep 27, 2024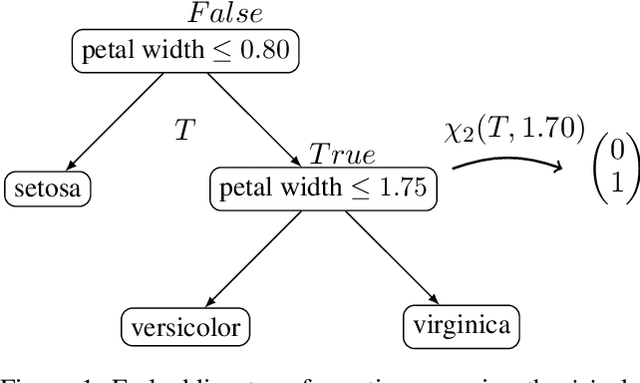
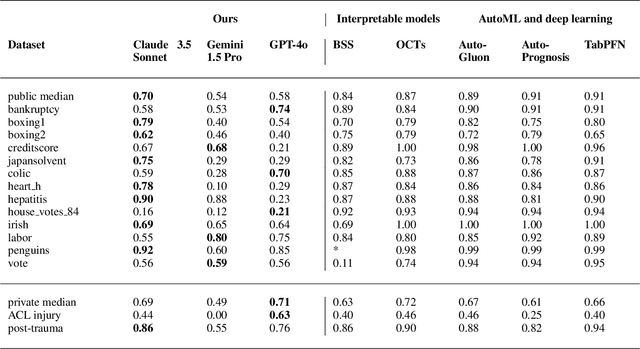
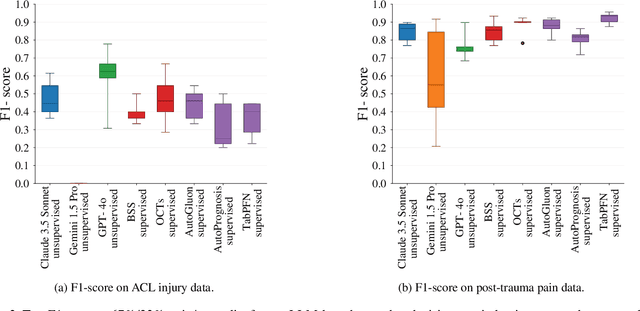
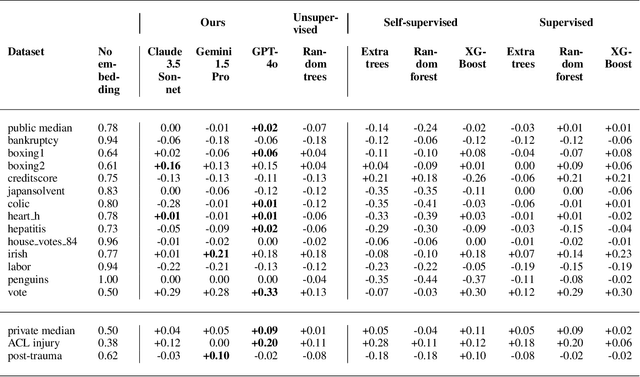
Large language models (LLMs) provide powerful means to leverage prior knowledge for predictive modeling when data is limited. In this work, we demonstrate how LLMs can use their compressed world knowledge to generate intrinsically interpretable machine learning models, i.e., decision trees, without any training data. We find that these zero-shot decision trees can surpass data-driven trees on some small-sized tabular datasets and that embeddings derived from these trees perform on par with data-driven tree-based embeddings on average. Our knowledge-driven decision tree induction and embedding approaches therefore serve as strong new baselines for data-driven machine learning methods in the low-data regime.
PMLBmini: A Tabular Classification Benchmark Suite for Data-Scarce Applications
Sep 03, 2024



In practice, we are often faced with small-sized tabular data. However, current tabular benchmarks are not geared towards data-scarce applications, making it very difficult to derive meaningful conclusions from empirical comparisons. We introduce PMLBmini, a tabular benchmark suite of 44 binary classification datasets with sample sizes $\leq$ 500. We use our suite to thoroughly evaluate current automated machine learning (AutoML) frameworks, off-the-shelf tabular deep neural networks, as well as classical linear models in the low-data regime. Our analysis reveals that state-of-the-art AutoML and deep learning approaches often fail to appreciably outperform even a simple logistic regression baseline, but we also identify scenarios where AutoML and deep learning methods are indeed reasonable to apply. Our benchmark suite, available on https://github.com/RicardoKnauer/TabMini , allows researchers and practitioners to analyze their own methods and challenge their data efficiency.
Squeezing Lemons with Hammers: An Evaluation of AutoML and Tabular Deep Learning for Data-Scarce Classification Applications
May 13, 2024



Many industry verticals are confronted with small-sized tabular data. In this low-data regime, it is currently unclear whether the best performance can be expected from simple baselines, or more complex machine learning approaches that leverage meta-learning and ensembling. On 44 tabular classification datasets with sample sizes $\leq$ 500, we find that L2-regularized logistic regression performs similar to state-of-the-art automated machine learning (AutoML) frameworks (AutoPrognosis, AutoGluon) and off-the-shelf deep neural networks (TabPFN, HyperFast) on the majority of the benchmark datasets. We therefore recommend to consider logistic regression as the first choice for data-scarce applications with tabular data and provide practitioners with best practices for further method selection.
Cost-Sensitive Best Subset Selection for Logistic Regression: A Mixed-Integer Conic Optimization Perspective
Oct 09, 2023A key challenge in machine learning is to design interpretable models that can reduce their inputs to the best subset for making transparent predictions, especially in the clinical domain. In this work, we propose a certifiably optimal feature selection procedure for logistic regression from a mixed-integer conic optimization perspective that can take an auxiliary cost to obtain features into account. Based on an extensive review of the literature, we carefully create a synthetic dataset generator for clinical prognostic model research. This allows us to systematically evaluate different heuristic and optimal cardinality- and budget-constrained feature selection procedures. The analysis shows key limitations of the methods for the low-data regime and when confronted with label noise. Our paper not only provides empirical recommendations for suitable methods and dataset designs, but also paves the way for future research in the area of meta-learning.