 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Weight Imprinting: Insights from Neural Collapse and Proxy-Based Aggregation
Mar 18, 2025The capacity of a foundation model allows for adaptation to new downstream tasks. Weight imprinting is a universal and efficient method to fulfill this purpose. It has been reinvented several times, but it has not been systematically studied. In this paper, we propose a framework for imprinting, identifying three main components: generation, normalization, and aggregation. This allows us to conduct an in-depth analysis of imprinting and a comparison of the existing work. We reveal the benefits of representing novel data with multiple proxies in the generation step and show the importance of proper normalization. We determine those proxies through clustering and propose a novel variant of imprinting that outperforms previous work. We motivate this by the neural collapse phenomenon -- an important connection that we can draw for the first time. Our results show an increase of up to 4% in challenging scenarios with complex data distributions for new classes.
Feedback-driven object detection and iterative model improvement
Nov 29, 2024Automated object detection has become increasingly valuable across diverse applications, yet efficient, high-quality annotation remains a persistent challenge. In this paper, we present the development and evaluation of a platform designed to interactively improve object detection models. The platform allows uploading and annotating images as well as fine-tuning object detection models. Users can then manually review and refine annotations, further creating improved snapshots that are used for automatic object detection on subsequent image uploads - a process we refer to as semi-automatic annotation resulting in a significant gain in annotation efficiency. Whereas iterative refinement of model results to speed up annotation has become common practice, we are the first to quantitatively evaluate its benefits with respect to time, effort, and interaction savings. Our experimental results show clear evidence for a significant time reduction of up to 53% for semi-automatic compared to manual annotation. Importantly, these efficiency gains did not compromise annotation quality, while matching or occasionally even exceeding the accuracy of manual annotations. These findings demonstrate the potential of our lightweight annotation platform for creating high-quality object detection datasets and provide best practices to guide future development of annotation platforms. The platform is open-source, with the frontend and backend repositories available on GitHub.
"Oh LLM, I'm Asking Thee, Please Give Me a Decision Tree": Zero-Shot Decision Tree Induction and Embedding with Large Language Models
Sep 27, 2024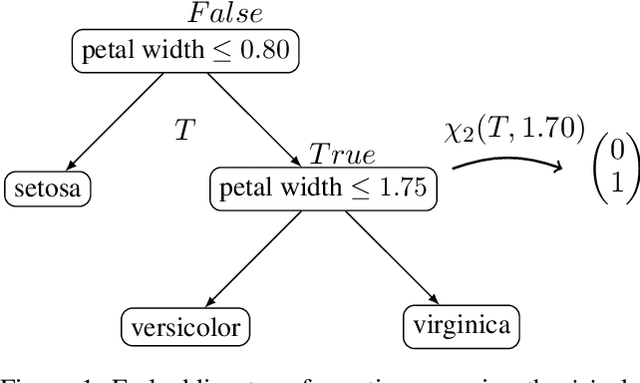
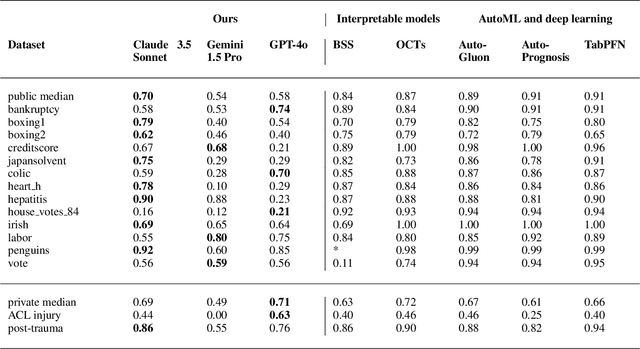
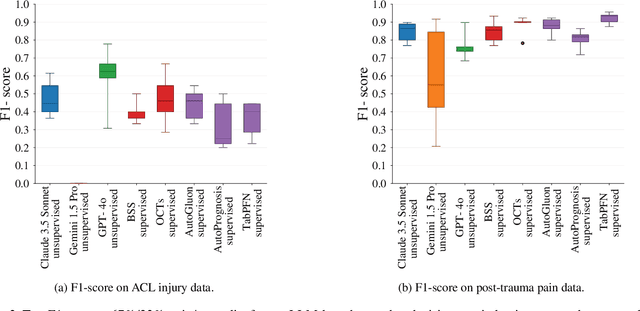
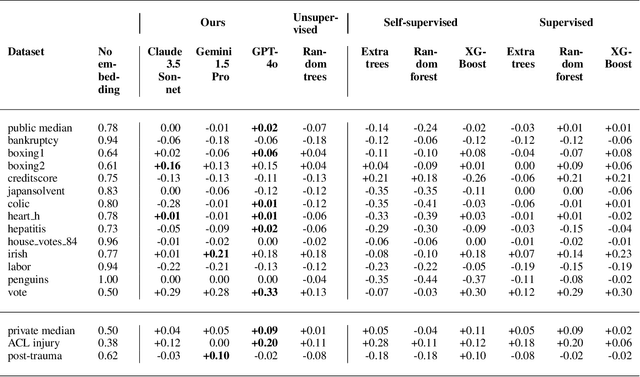
Large language models (LLMs) provide powerful means to leverage prior knowledge for predictive modeling when data is limited. In this work, we demonstrate how LLMs can use their compressed world knowledge to generate intrinsically interpretable machine learning models, i.e., decision trees, without any training data. We find that these zero-shot decision trees can surpass data-driven trees on some small-sized tabular datasets and that embeddings derived from these trees perform on par with data-driven tree-based embeddings on average. Our knowledge-driven decision tree induction and embedding approaches therefore serve as strong new baselines for data-driven machine learning methods in the low-data regime.