 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame2Freq: Spectral Adapters for Fine-Grained Video Understanding
Feb 21, 2026Adapting image-pretrained backbones to video typically relies on time-domain adapters tuned to a single temporal scale. Our experiments show that these modules pick up static image cues and very fast flicker changes, while overlooking medium-speed motion. Capturing dynamics across multiple time-scales is, however, crucial for fine-grained temporal analysis (i.e., opening vs. closing bottle). To address this, we introduce Frame2Freq -- a family of frequency-aware adapters that perform spectral encoding during image-to-video adaptation of pretrained Vision Foundation Models (VFMs), improving fine-grained action recognition. Frame2Freq uses Fast Fourier Transform (FFT) along time and learns frequency-band specific embeddings that adaptively highlight the most discriminative frequency ranges. Across five fine-grained activity recognition datasets, Frame2Freq outperforms prior PEFT methods and even surpasses fully fine-tuned models on four of them. These results provide encouraging evidence that frequency analysis methods are a powerful tool for modeling temporal dynamics in image-to-video transfer. Code is available at https://github.com/th-nesh/Frame2Freq.
Deep Learning for Metabolic Rate Estimation from Biosignals: A Comparative Study of Architectures and Signal Selection
Nov 12, 2025Energy expenditure estimation aims to infer human metabolic rate from physiological signals such as heart rate, respiration, or accelerometer data, and has been studied primarily with classical regression methods. The few existing deep learning approaches rarely disentangle the role of neural architecture from that of signal choice. In this work, we systematically evaluate both aspects. We compare classical baselines with newer neural architectures across single signals, signal pairs, and grouped sensor inputs for diverse physical activities. Our results show that minute ventilation is the most predictive individual signal, with a transformer model achieving the lowest root mean square error (RMSE) of 0.87 W/kg across all activities. Paired and grouped signals, such as those from the Hexoskin smart shirt (five signals), offer good alternatives for faster models like CNN and ResNet with attention. Per-activity evaluation revealed mixed outcomes: notably better results in low-intensity activities (RMSE down to 0.29 W/kg; NRMSE = 0.04), while higher-intensity tasks showed larger RMSE but more comparable normalized errors. Finally, subject-level analysis highlights strong inter-individual variability, motivating the need for adaptive modeling strategies. Our code and models will be publicly available at https://github.com/Sarvibabakhani/deeplearning-biosignals-ee .
Prompt-Guided Relational Reasoning for Social Behavior Understanding with Vision Foundation Models
Aug 11, 2025
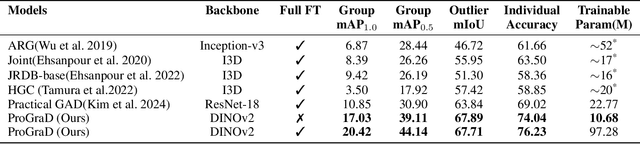
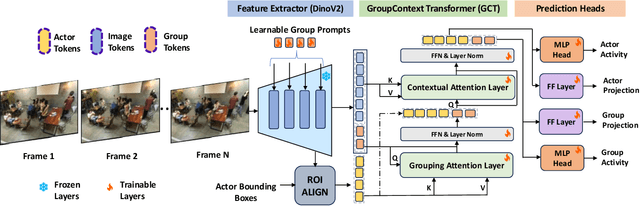
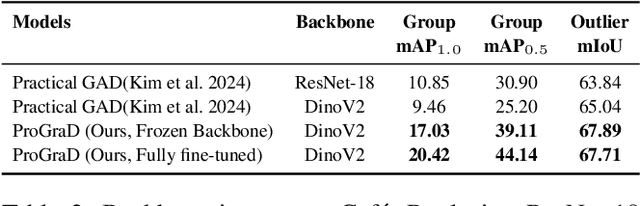
Group Activity Detection (GAD) involves recognizing social groups and their collective behaviors in videos. Vision Foundation Models (VFMs), like DinoV2, offer excellent features, but are pretrained primarily on object-centric data and remain underexplored for modeling group dynamics. While they are a promising alternative to highly task-specific GAD architectures that require full fine-tuning, our initial investigation reveals that simply swapping CNN backbones used in these methods with VFMs brings little gain, underscoring the need for structured, group-aware reasoning on top. We introduce Prompt-driven Group Activity Detection (ProGraD) -- a method that bridges this gap through 1) learnable group prompts to guide the VFM attention toward social configurations, and 2) a lightweight two-layer GroupContext Transformer that infers actor-group associations and collective behavior. We evaluate our approach on two recent GAD benchmarks: Cafe, which features multiple concurrent social groups, and Social-CAD, which focuses on single-group interactions. While we surpass state-of-the-art in both settings, our method is especially effective in complex multi-group scenarios, where we yield a gain of 6.5\% (Group mAP\@1.0) and 8.2\% (Group mAP\@0.5) using only 10M trainable parameters. Furthermore, our experiments reveal that ProGraD produces interpretable attention maps, offering insights into actor-group reasoning. Code and models will be released.
Order Matters: On Parameter-Efficient Image-to-Video Probing for Recognizing Nearly Symmetric Actions
Mar 31, 2025
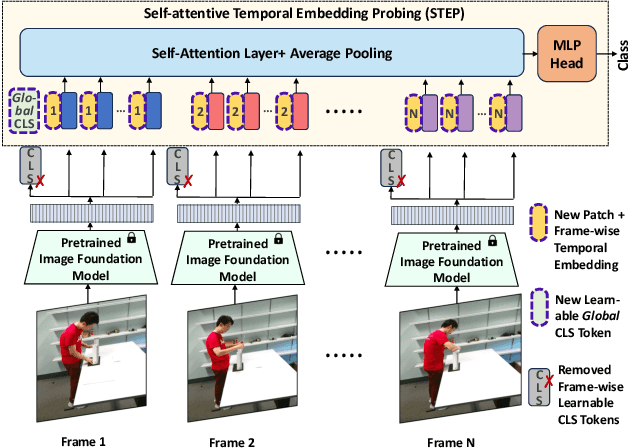
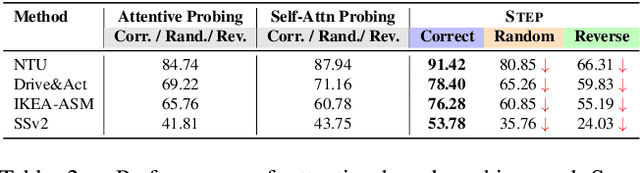

We study parameter-efficient image-to-video probing for the unaddressed challenge of recognizing nearly symmetric actions - visually similar actions that unfold in opposite temporal order (e.g., opening vs. closing a bottle). Existing probing mechanisms for image-pretrained models, such as DinoV2 and CLIP, rely on attention mechanism for temporal modeling but are inherently permutation-invariant, leading to identical predictions regardless of frame order. To address this, we introduce Self-attentive Temporal Embedding Probing (STEP), a simple yet effective approach designed to enforce temporal sensitivity in parameter-efficient image-to-video transfer. STEP enhances self-attentive probing with three key modifications: (1) a learnable frame-wise positional encoding, explicitly encoding temporal order; (2) a single global CLS token, for sequence coherence; and (3) a simplified attention mechanism to improve parameter efficiency. STEP outperforms existing image-to-video probing mechanisms by 3-15% across four activity recognition benchmarks with only 1/3 of the learnable parameters. On two datasets, it surpasses all published methods, including fully fine-tuned models. STEP shows a distinct advantage in recognizing nearly symmetric actions, surpassing other probing mechanisms by 9-19%. and parameter-heavier PEFT-based transfer methods by 5-15%. Code and models will be made publicly available.
Mitigating Label Noise using Prompt-Based Hyperbolic Meta-Learning in Open-Set Domain Generalization
Dec 24, 2024



Open-Set Domain Generalization (OSDG) is a challenging task requiring models to accurately predict familiar categories while minimizing confidence for unknown categories to effectively reject them in unseen domains. While the OSDG field has seen considerable advancements, the impact of label noise--a common issue in real-world datasets--has been largely overlooked. Label noise can mislead model optimization, thereby exacerbating the challenges of open-set recognition in novel domains. In this study, we take the first step towards addressing Open-Set Domain Generalization under Noisy Labels (OSDG-NL) by constructing dedicated benchmarks derived from widely used OSDG datasets, including PACS and DigitsDG. We evaluate baseline approaches by integrating techniques from both label denoising and OSDG methodologies, highlighting the limitations of existing strategies in handling label noise effectively. To address these limitations, we propose HyProMeta, a novel framework that integrates hyperbolic category prototypes for label noise-aware meta-learning alongside a learnable new-category agnostic prompt designed to enhance generalization to unseen classes. Our extensive experiments demonstrate the superior performance of HyProMeta compared to state-of-the-art methods across the newly established benchmarks. The source code of this work is released at https://github.com/KPeng9510/HyProMeta.
Advancing Open-Set Domain Generalization Using Evidential Bi-Level Hardest Domain Scheduler
Sep 26, 2024



In Open-Set Domain Generalization (OSDG), the model is exposed to both new variations of data appearance (domains) and open-set conditions, where both known and novel categories are present at test time. The challenges of this task arise from the dual need to generalize across diverse domains and accurately quantify category novelty, which is critical for applications in dynamic environments. Recently, meta-learning techniques have demonstrated superior results in OSDG, effectively orchestrating the meta-train and -test tasks by employing varied random categories and predefined domain partition strategies. These approaches prioritize a well-designed training schedule over traditional methods that focus primarily on data augmentation and the enhancement of discriminative feature learning. The prevailing meta-learning models in OSDG typically utilize a predefined sequential domain scheduler to structure data partitions. However, a crucial aspect that remains inadequately explored is the influence brought by strategies of domain schedulers during training. In this paper, we observe that an adaptive domain scheduler benefits more in OSDG compared with prefixed sequential and random domain schedulers. We propose the Evidential Bi-Level Hardest Domain Scheduler (EBiL-HaDS) to achieve an adaptive domain scheduler. This method strategically sequences domains by assessing their reliabilities in utilizing a follower network, trained with confidence scores learned in an evidential manner, regularized by max rebiasing discrepancy, and optimized in a bi-level manner. The results show that our method substantially improves OSDG performance and achieves more discriminative embeddings for both the seen and unseen categories. The source code will be available at https://github.com/KPeng9510/EBiL-HaDS.
Towards Synthetic Data Generation for Improved Pain Recognition in Videos under Patient Constraints
Sep 24, 2024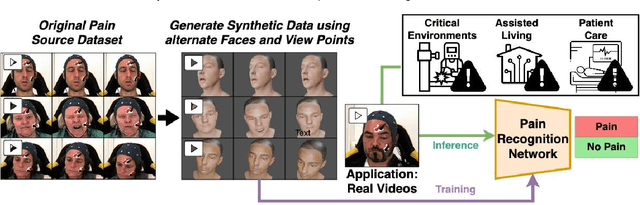
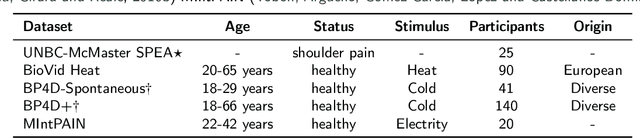
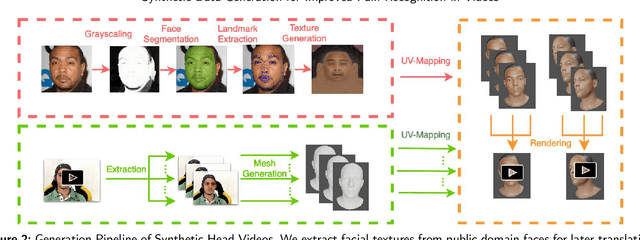
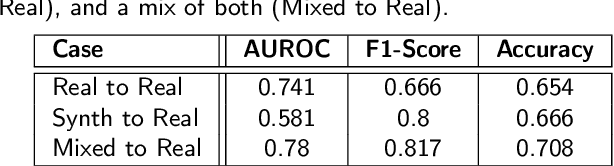
Recognizing pain in video is crucial for improving patient-computer interaction systems, yet traditional data collection in this domain raises significant ethical and logistical challenges. This study introduces a novel approach that leverages synthetic data to enhance video-based pain recognition models, providing an ethical and scalable alternative. We present a pipeline that synthesizes realistic 3D facial models by capturing nuanced facial movements from a small participant pool, and mapping these onto diverse synthetic avatars. This process generates 8,600 synthetic faces, accurately reflecting genuine pain expressions from varied angles and perspectives. Utilizing advanced facial capture techniques, and leveraging public datasets like CelebV-HQ and FFHQ-UV for demographic diversity, our new synthetic dataset significantly enhances model training while ensuring privacy by anonymizing identities through facial replacements. Experimental results demonstrate that models trained on combinations of synthetic data paired with a small amount of real participants achieve superior performance in pain recognition, effectively bridging the gap between synthetic simulations and real-world applications. Our approach addresses data scarcity and ethical concerns, offering a new solution for pain detection and opening new avenues for research in privacy-preserving dataset generation. All resources are publicly available to encourage further innovation in this field.
Probing Fine-Grained Action Understanding and Cross-View Generalization of Foundation Models
Jul 22, 2024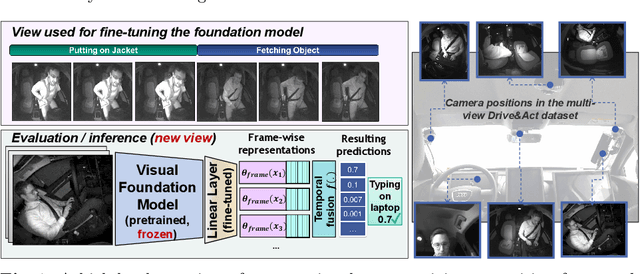



Foundation models (FMs) are large neural networks trained on broad datasets, excelling in downstream tasks with minimal fine-tuning. Human activity recognition in video has advanced with FMs, driven by competition among different architectures. However, high accuracies on standard benchmarks can draw an artificially rosy picture, as they often overlook real-world factors like changing camera perspectives. Popular benchmarks, mostly from YouTube or movies, offer diverse views but only coarse actions, which are insufficient for use-cases needing fine-grained, domain-specific actions. Domain-specific datasets (e.g., for industrial assembly) typically use data from limited static perspectives. This paper empirically evaluates how perspective changes affect different FMs in fine-grained human activity recognition. We compare multiple backbone architectures and design choices, including image- and video- based models, and various strategies for temporal information fusion, including commonly used score averaging and more novel attention-based temporal aggregation mechanisms. This is the first systematic study of different foundation models and specific design choices for human activity recognition from unknown views, conducted with the goal to provide guidance for backbone- and temporal- fusion scheme selection. Code and models will be made publicly available to the community.
Referring Atomic Video Action Recognition
Jul 02, 2024We introduce a new task called Referring Atomic Video Action Recognition (RAVAR), aimed at identifying atomic actions of a particular person based on a textual description and the video data of this person. This task differs from traditional action recognition and localization, where predictions are delivered for all present individuals. In contrast, we focus on recognizing the correct atomic action of a specific individual, guided by text. To explore this task, we present the RefAVA dataset, containing 36,630 instances with manually annotated textual descriptions of the individuals. To establish a strong initial benchmark, we implement and validate baselines from various domains, e.g., atomic action localization, video question answering, and text-video retrieval. Since these existing methods underperform on RAVAR, we introduce RefAtomNet -- a novel cross-stream attention-driven method specialized for the unique challenges of RAVAR: the need to interpret a textual referring expression for the targeted individual, utilize this reference to guide the spatial localization and harvest the prediction of the atomic actions for the referring person. The key ingredients are: (1) a multi-stream architecture that connects video, text, and a new location-semantic stream, and (2) cross-stream agent attention fusion and agent token fusion which amplify the most relevant information across these streams and consistently surpasses standard attention-based fusion on RAVAR. Extensive experiments demonstrate the effectiveness of RefAtomNet and its building blocks for recognizing the action of the described individual. The dataset and code will be made publicly available at https://github.com/KPeng9510/RAVAR.
Skeleton-Based Human Action Recognition with Noisy Labels
Mar 15, 2024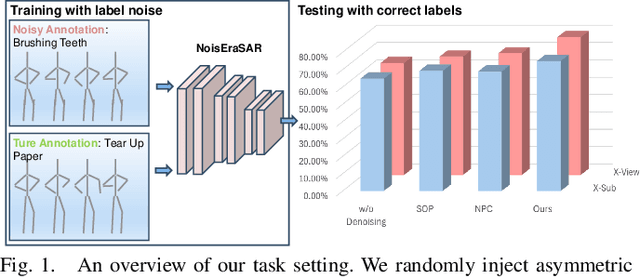
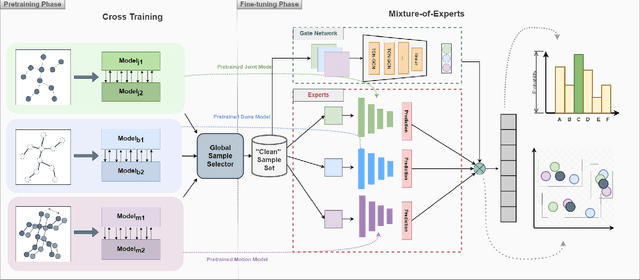
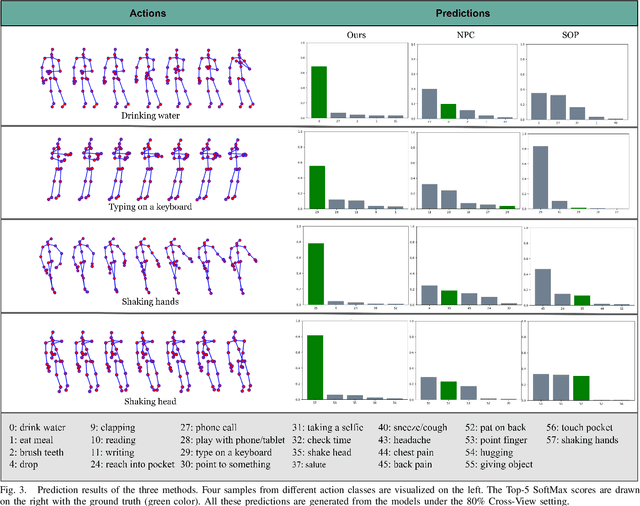

Understanding human actions from body poses is critical for assistive robots sharing space with humans in order to make informed and safe decisions about the next interaction. However, precise temporal localization and annotation of activity sequences is time-consuming and the resulting labels are often noisy. If not effectively addressed, label noise negatively affects the model's training, resulting in lower recognition quality. Despite its importance, addressing label noise for skeleton-based action recognition has been overlooked so far. In this study, we bridge this gap by implementing a framework that augments well-established skeleton-based human action recognition methods with label-denoising strategies from various research areas to serve as the initial benchmark. Observations reveal that these baselines yield only marginal performance when dealing with sparse skeleton data. Consequently, we introduce a novel methodology, NoiseEraSAR, which integrates global sample selection, co-teaching, and Cross-Modal Mixture-of-Experts (CM-MOE) strategies, aimed at mitigating the adverse impacts of label noise. Our proposed approach demonstrates better performance on the established benchmark, setting new state-of-the-art standards. The source code for this study will be made accessible at https://github.com/xuyizdby/NoiseEraSAR.