 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame2Freq: Spectral Adapters for Fine-Grained Video Understanding
Feb 21, 2026Adapting image-pretrained backbones to video typically relies on time-domain adapters tuned to a single temporal scale. Our experiments show that these modules pick up static image cues and very fast flicker changes, while overlooking medium-speed motion. Capturing dynamics across multiple time-scales is, however, crucial for fine-grained temporal analysis (i.e., opening vs. closing bottle). To address this, we introduce Frame2Freq -- a family of frequency-aware adapters that perform spectral encoding during image-to-video adaptation of pretrained Vision Foundation Models (VFMs), improving fine-grained action recognition. Frame2Freq uses Fast Fourier Transform (FFT) along time and learns frequency-band specific embeddings that adaptively highlight the most discriminative frequency ranges. Across five fine-grained activity recognition datasets, Frame2Freq outperforms prior PEFT methods and even surpasses fully fine-tuned models on four of them. These results provide encouraging evidence that frequency analysis methods are a powerful tool for modeling temporal dynamics in image-to-video transfer. Code is available at https://github.com/th-nesh/Frame2Freq.
Prompt-Guided Relational Reasoning for Social Behavior Understanding with Vision Foundation Models
Aug 11, 2025
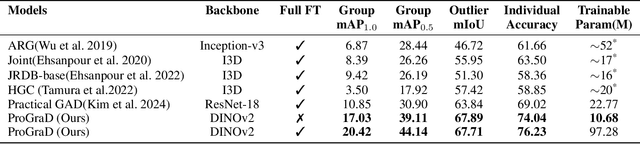
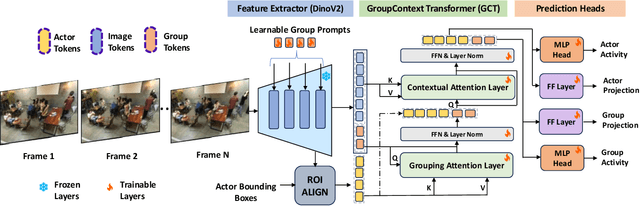
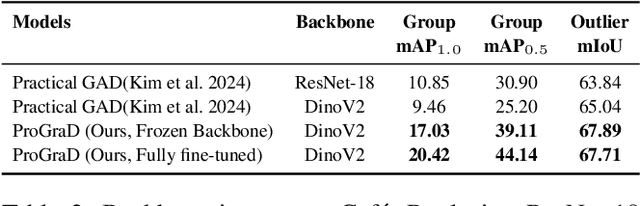
Group Activity Detection (GAD) involves recognizing social groups and their collective behaviors in videos. Vision Foundation Models (VFMs), like DinoV2, offer excellent features, but are pretrained primarily on object-centric data and remain underexplored for modeling group dynamics. While they are a promising alternative to highly task-specific GAD architectures that require full fine-tuning, our initial investigation reveals that simply swapping CNN backbones used in these methods with VFMs brings little gain, underscoring the need for structured, group-aware reasoning on top. We introduce Prompt-driven Group Activity Detection (ProGraD) -- a method that bridges this gap through 1) learnable group prompts to guide the VFM attention toward social configurations, and 2) a lightweight two-layer GroupContext Transformer that infers actor-group associations and collective behavior. We evaluate our approach on two recent GAD benchmarks: Cafe, which features multiple concurrent social groups, and Social-CAD, which focuses on single-group interactions. While we surpass state-of-the-art in both settings, our method is especially effective in complex multi-group scenarios, where we yield a gain of 6.5\% (Group mAP\@1.0) and 8.2\% (Group mAP\@0.5) using only 10M trainable parameters. Furthermore, our experiments reveal that ProGraD produces interpretable attention maps, offering insights into actor-group reasoning. Code and models will be released.
Order Matters: On Parameter-Efficient Image-to-Video Probing for Recognizing Nearly Symmetric Actions
Mar 31, 2025
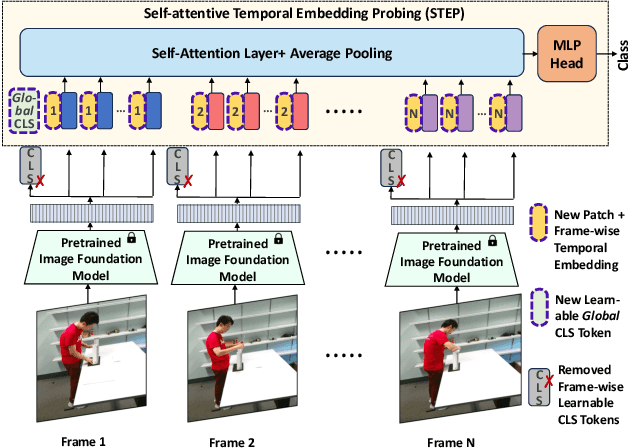
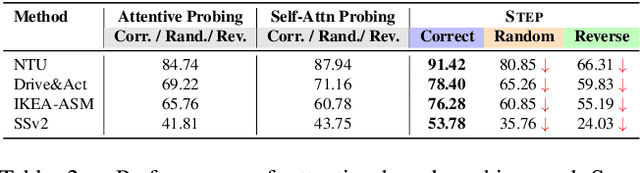

We study parameter-efficient image-to-video probing for the unaddressed challenge of recognizing nearly symmetric actions - visually similar actions that unfold in opposite temporal order (e.g., opening vs. closing a bottle). Existing probing mechanisms for image-pretrained models, such as DinoV2 and CLIP, rely on attention mechanism for temporal modeling but are inherently permutation-invariant, leading to identical predictions regardless of frame order. To address this, we introduce Self-attentive Temporal Embedding Probing (STEP), a simple yet effective approach designed to enforce temporal sensitivity in parameter-efficient image-to-video transfer. STEP enhances self-attentive probing with three key modifications: (1) a learnable frame-wise positional encoding, explicitly encoding temporal order; (2) a single global CLS token, for sequence coherence; and (3) a simplified attention mechanism to improve parameter efficiency. STEP outperforms existing image-to-video probing mechanisms by 3-15% across four activity recognition benchmarks with only 1/3 of the learnable parameters. On two datasets, it surpasses all published methods, including fully fine-tuned models. STEP shows a distinct advantage in recognizing nearly symmetric actions, surpassing other probing mechanisms by 9-19%. and parameter-heavier PEFT-based transfer methods by 5-15%. Code and models will be made publicly available.
Probing Fine-Grained Action Understanding and Cross-View Generalization of Foundation Models
Jul 22, 2024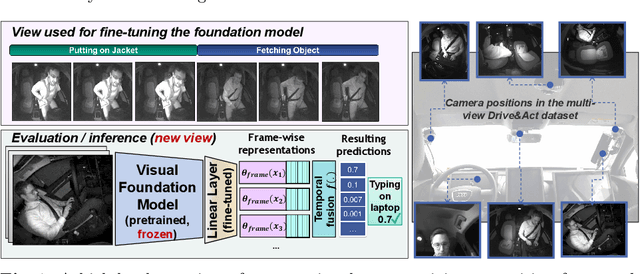



Foundation models (FMs) are large neural networks trained on broad datasets, excelling in downstream tasks with minimal fine-tuning. Human activity recognition in video has advanced with FMs, driven by competition among different architectures. However, high accuracies on standard benchmarks can draw an artificially rosy picture, as they often overlook real-world factors like changing camera perspectives. Popular benchmarks, mostly from YouTube or movies, offer diverse views but only coarse actions, which are insufficient for use-cases needing fine-grained, domain-specific actions. Domain-specific datasets (e.g., for industrial assembly) typically use data from limited static perspectives. This paper empirically evaluates how perspective changes affect different FMs in fine-grained human activity recognition. We compare multiple backbone architectures and design choices, including image- and video- based models, and various strategies for temporal information fusion, including commonly used score averaging and more novel attention-based temporal aggregation mechanisms. This is the first systematic study of different foundation models and specific design choices for human activity recognition from unknown views, conducted with the goal to provide guidance for backbone- and temporal- fusion scheme selection. Code and models will be made publicly available to the community.