 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHO: Robust Holistic OSM-Based Metric Cross-View Geo-Localization
Mar 29, 2026Metric Cross-View Geo-Localization (MCVGL) aims to estimate the 3-DoF camera pose (position and heading) by matching ground and satellite images. In this work, instead of pinhole and satellite images, we study robust MCVGL using holistic panoramas and OpenStreetMap (OSM). To this end, we establish a large-scale MCVGL benchmark dataset, CV-RHO, with over 2.7M images under different weather and lighting conditions, as well as sensor noise. Furthermore, we propose a model termed RHO with a two-branch Pin-Pan architecture for accurate visual localization. A Split-Undistort-Merge (SUM) module is introduced to address the panoramic distortion, and a Position-Orientation Fusion (POF) mechanism is designed to enhance the localization accuracy. Extensive experiments prove the value of our CV-RHO dataset and the effectiveness of the RHO model, with a significant performance gain up to 20% compared with the state-of-the-art baselines. Project page: https://github.com/InSAI-Lab/RHO.
Not an Obstacle for Dog, but a Hazard for Human: A Co-Ego Navigation System for Guide Dog Robots
Mar 20, 2026Guide dogs offer independence to Blind and Low-Vision (BLV) individuals, yet their limited availability leaves the vast majority of BLV users without access. Quadruped robotic guide dogs present a promising alternative, but existing systems rely solely on the robot's ground-level sensors for navigation, overlooking a critical class of hazards: obstacles that are transparent to the robot yet dangerous at human body height, such as bent branches. We term this the viewpoint asymmetry problem and present the first system to explicitly address it. Our Co-Ego system adopts a dual-branch obstacle avoidance framework that integrates the robot-centric ground sensing with the user's elevated egocentric perspective to ensure comprehensive navigation safety. Deployed on a quadruped robot, the system is evaluated in a controlled user study with sighted participants under blindfold across three conditions: unassisted, single-view, and cross-view fusion. Results demonstrate that cross-view fusion significantly reduces collision times and cognitive load, verifying the necessity of viewpoint complementarity for safe robotic guide dog navigation.
InterEdit: Navigating Text-Guided Multi-Human 3D Motion Editing
Mar 13, 2026Text-guided 3D motion editing has seen success in single-person scenarios, but its extension to multi-person settings is less explored due to limited paired data and the complexity of inter-person interactions. We introduce the task of multi-person 3D motion editing, where a target motion is generated from a source and a text instruction. To support this, we propose InterEdit3D, a new dataset with manual two-person motion change annotations, and a Text-guided Multi-human Motion Editing (TMME) benchmark. We present InterEdit, a synchronized classifier-free conditional diffusion model for TMME. It introduces Semantic-Aware Plan Token Alignment with learnable tokens to capture high-level interaction cues and an Interaction-Aware Frequency Token Alignment strategy using DCT and energy pooling to model periodic motion dynamics. Experiments show that InterEdit improves text-to-motion consistency and edit fidelity, achieving state-of-the-art TMME performance. The dataset and code will be released at https://github.com/YNG916/InterEdit.
DriveXQA: Cross-modal Visual Question Answering for Adverse Driving Scene Understanding
Mar 11, 2026Fusing sensors with complementary modalities is crucial for maintaining a stable and comprehensive understanding of abnormal driving scenes. However, Multimodal Large Language Models (MLLMs) are underexplored for leveraging multi-sensor information to understand adverse driving scenarios in autonomous vehicles. To address this gap, we propose the DriveXQA, a multimodal dataset for autonomous driving VQA. In addition to four visual modalities, five sensor failure cases, and five weather conditions, it includes $102,505$ QA pairs categorized into three types: global scene level, allocentric level, and ego-vehicle centric level. Since no existing MLLM framework adopts multiple complementary visual modalities as input, we design MVX-LLM, a token-efficient architecture with a Dual Cross-Attention (DCA) projector that fuses the modalities to alleviate information redundancy. Experiments demonstrate that our DCA achieves improved performance under challenging conditions such as foggy (GPTScore: $53.5$ vs. $25.1$ for the baseline). The established dataset and source code will be made publicly available.
$M^2$-Occ: Resilient 3D Semantic Occupancy Prediction for Autonomous Driving with Incomplete Camera Inputs
Mar 10, 2026Semantic occupancy prediction enables dense 3D geometric and semantic understanding for autonomous driving. However, existing camera-based approaches implicitly assume complete surround-view observations, an assumption that rarely holds in real-world deployment due to occlusion, hardware malfunction, or communication failures. We study semantic occupancy prediction under incomplete multi-camera inputs and introduce $M^2$-Occ, a framework designed to preserve geometric structure and semantic coherence when views are missing. $M^2$-Occ addresses two complementary challenges. First, a Multi-view Masked Reconstruction (MMR) module leverages the spatial overlap among neighboring cameras to recover missing-view representations directly in the feature space. Second, a Feature Memory Module (FMM) introduces a learnable memory bank that stores class-level semantic prototypes. By retrieving and integrating these global priors, the FMM refines ambiguous voxel features, ensuring semantic consistency even when observational evidence is incomplete. We introduce a systematic missing-view evaluation protocol on the nuScenes-based SurroundOcc benchmark, encompassing both deterministic single-view failures and stochastic multi-view dropout scenarios. Under the safety-critical missing back-view setting, $M^2$-Occ improves the IoU by 4.93%. As the number of missing cameras increases, the robustness gap further widens; for instance, under the setting with five missing views, our method boosts the IoU by 5.01%. These gains are achieved without compromising full-view performance. The source code will be publicly released at https://github.com/qixi7up/M2-Occ.
More than the Sum: Panorama-Language Models for Adverse Omni-Scenes
Mar 10, 2026Existing vision-language models (VLMs) are tailored for pinhole imagery, stitching multiple narrow field-of-view inputs to piece together a complete omni-scene understanding. Yet, such multi-view perception overlooks the holistic spatial and contextual relationships that a single panorama inherently preserves. In this work, we introduce the Panorama-Language Modeling (PLM)paradigm, a unified $360^\circ$ vision-language reasoning that is more than the sum of its pinhole counterparts. Besides, we present PanoVQA, a large-scale panoramic VQA dataset that involves adverse omni-scenes, enabling comprehensive reasoning under object occlusions and driving accidents. To establish a foundation for PLM, we develop a plug-and-play panoramic sparse attention module that allows existing pinhole-based VLMs to process equirectangular panoramas without retraining. Extensive experiments demonstrate that our PLM achieves superior robustness and holistic reasoning under challenging omni-scenes, yielding understanding greater than the sum of its narrow parts. Project page: https://github.com/InSAI-Lab/PanoVQA.
SGR3 Model: Scene Graph Retrieval-Reasoning Model in 3D
Mar 04, 20263D scene graphs provide a structured representation of object entities and their relationships, enabling high-level interpretation and reasoning for robots while remaining intuitively understandable to humans. Existing approaches for 3D scene graph generation typically combine scene reconstruction with graph neural networks (GNNs). However, such pipelines require multi-modal data that may not always be available, and their reliance on heuristic graph construction can constrain the prediction of relationship triplets. In this work, we introduce a Scene Graph Retrieval-Reasoning Model in 3D (SGR3 Model), a training-free framework that leverages multi-modal large language models (MLLMs) with retrieval-augmented generation (RAG) for semantic scene graph generation. SGR3 Model bypasses the need for explicit 3D reconstruction. Instead, it enhances relational reasoning by incorporating semantically aligned scene graphs retrieved via a ColPali-style cross-modal framework. To improve retrieval robustness, we further introduce a weighted patch-level similarity selection mechanism that mitigates the negative impact of blurry or semantically uninformative regions. Experiments demonstrate that SGR3 Model achieves competitive performance compared to training-free baselines and on par with GNN-based expert models. Moreover, an ablation study on the retrieval module and knowledge base scale reveals that retrieved external information is explicitly integrated into the token generation process, rather than being implicitly internalized through abstraction.
EReLiFM: Evidential Reliability-Aware Residual Flow Meta-Learning for Open-Set Domain Generalization under Noisy Labels
Oct 14, 2025
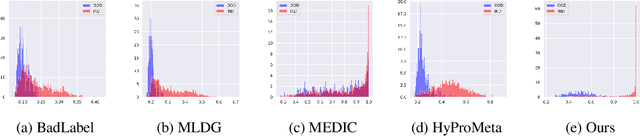


Open-Set Domain Generalization (OSDG) aims to enable deep learning models to recognize unseen categories in new domains, which is crucial for real-world applications. Label noise hinders open-set domain generalization by corrupting source-domain knowledge, making it harder to recognize known classes and reject unseen ones. While existing methods address OSDG under Noisy Labels (OSDG-NL) using hyperbolic prototype-guided meta-learning, they struggle to bridge domain gaps, especially with limited clean labeled data. In this paper, we propose Evidential Reliability-Aware Residual Flow Meta-Learning (EReLiFM). We first introduce an unsupervised two-stage evidential loss clustering method to promote label reliability awareness. Then, we propose a residual flow matching mechanism that models structured domain- and category-conditioned residuals, enabling diverse and uncertainty-aware transfer paths beyond interpolation-based augmentation. During this meta-learning process, the model is optimized such that the update direction on the clean set maximizes the loss decrease on the noisy set, using pseudo labels derived from the most confident predicted class for supervision. Experimental results show that EReLiFM outperforms existing methods on OSDG-NL, achieving state-of-the-art performance. The source code is available at https://github.com/KPeng9510/ERELIFM.
MICA: Multi-Agent Industrial Coordination Assistant
Sep 17, 2025Industrial workflows demand adaptive and trustworthy assistance that can operate under limited computing, connectivity, and strict privacy constraints. In this work, we present MICA (Multi-Agent Industrial Coordination Assistant), a perception-grounded and speech-interactive system that delivers real-time guidance for assembly, troubleshooting, part queries, and maintenance. MICA coordinates five role-specialized language agents, audited by a safety checker, to ensure accurate and compliant support. To achieve robust step understanding, we introduce Adaptive Step Fusion (ASF), which dynamically blends expert reasoning with online adaptation from natural speech feedback. Furthermore, we establish a new multi-agent coordination benchmark across representative task categories and propose evaluation metrics tailored to industrial assistance, enabling systematic comparison of different coordination topologies. Our experiments demonstrate that MICA consistently improves task success, reliability, and responsiveness over baseline structures, while remaining deployable on practical offline hardware. Together, these contributions highlight MICA as a step toward deployable, privacy-preserving multi-agent assistants for dynamic factory environments. The source code will be made publicly available at https://github.com/Kratos-Wen/MICA.
A Multi-Agent System for Information Extraction from the Chemical Literature
Jul 27, 2025To fully expedite AI-powered chemical research, high-quality chemical databases are the cornerstone. Automatic extraction of chemical information from the literature is essential for constructing reaction databases, but it is currently limited by the multimodality and style variability of chemical information. In this work, we developed a multimodal large language model (MLLM)-based multi-agent system for automatic chemical information extraction. We used the MLLM's strong reasoning capability to understand the structure of complex chemical graphics, decompose the extraction task into sub-tasks and coordinate a set of specialized agents to solve them. Our system achieved an F1 score of 80.8% on a benchmark dataset of complex chemical reaction graphics from the literature, surpassing the previous state-of-the-art model (F1 score: 35.6%) by a significant margin. Additionally, it demonstrated consistent improvements in key sub-tasks, including molecular image recognition, reaction image parsing, named entity recognition and text-based reaction extraction. This work is a critical step toward automated chemical information extraction into structured datasets, which will be a strong promoter of AI-driven chemical research.