 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Table QA via TableGrid Navigation and Progressive Inference Prompting
May 18, 2026Large Language Models (LLMs) have shown promising results on NLP tasks, however, their performance on tabular data still needs research attention, because Table Question-Answering (TQA) requires precise cell retrieval and multi-step structured reasoning. Existing work improves TQA either by fine-tuning or training LLMs on task-specific tabular data, but often lacks verifiable control over how the model navigates tables and derives answers. In this work, we propose a training-free TQA approach with two structured prompting frameworks: TableGrid Navigation (TGN), which iteratively navigates rows and columns via a three-module loop to locate evidence and refine answers, and Progressive Inference Prompting (PIP), which enforces columns identification for explicit progressive row selection constraint according to the query. We evaluate 17 LLMs against 6 baselines on TableBench and FeTaQa dataset. On TableBench, TGN improves over the strongest baseline by 3.8 points, and on FeTaQa, PIP achieves SOTA performance over ReAct and Chain-of-Thought. Beyond inference-time gains, PIP and TGN can also serve as supervision templates to fine-tune small models, narrowing the performance gap to much larger architectures in resource-constrained settings, offering versatile and cost-efficient solution for TQA.
Cortex 2.0: Grounding World Models in Real-World Industrial Deployment
Apr 22, 2026Industrial robotic manipulation demands reliable long-horizon execution across embodiments, tasks, and changing object distributions. While Vision-Language-Action models have demonstrated strong generalization, they remain fundamentally reactive. By optimizing the next action given the current observation without evaluating potential futures, they are brittle to the compounding failure modes of long-horizon tasks. Cortex 2.0 shifts from reactive control to plan-and-act by generating candidate future trajectories in visual latent space, scoring them for expected success and efficiency, then committing only to the highest-scoring candidate. We evaluate Cortex 2.0 on a single-arm and dual-arm manipulation platform across four tasks of increasing complexity: pick and place, item and trash sorting, screw sorting, and shoebox unpacking. Cortex 2.0 consistently outperforms state-of-the-art Vision-Language-Action baselines, achieving the best results across all tasks. The system remains reliable in unstructured environments characterized by heavy clutter, frequent occlusions, and contact-rich manipulation, where reactive policies fail. These results demonstrate that world-model-based planning can operate reliably in complex industrial environments.
CHAOS: Chart Analysis with Outlier Samples
May 22, 2025Charts play a critical role in data analysis and visualization, yet real-world applications often present charts with challenging or noisy features. However, "outlier charts" pose a substantial challenge even for Multimodal Large Language Models (MLLMs), which can struggle to interpret perturbed charts. In this work, we introduce CHAOS (CHart Analysis with Outlier Samples), a robustness benchmark to systematically evaluate MLLMs against chart perturbations. CHAOS encompasses five types of textual and ten types of visual perturbations, each presented at three levels of severity (easy, mid, hard) inspired by the study result of human evaluation. The benchmark includes 13 state-of-the-art MLLMs divided into three groups (i.e., general-, document-, and chart-specific models) according to the training scope and data. Comprehensive analysis involves two downstream tasks (ChartQA and Chart-to-Text). Extensive experiments and case studies highlight critical insights into robustness of models across chart perturbations, aiming to guide future research in chart understanding domain. Data and code are publicly available at: http://huggingface.co/datasets/omoured/CHAOS.
RefChartQA: Grounding Visual Answer on Chart Images through Instruction Tuning
Mar 29, 2025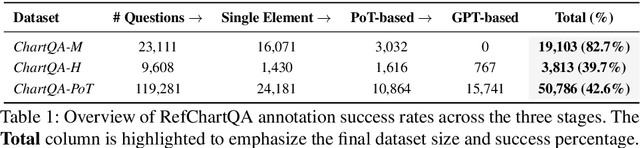
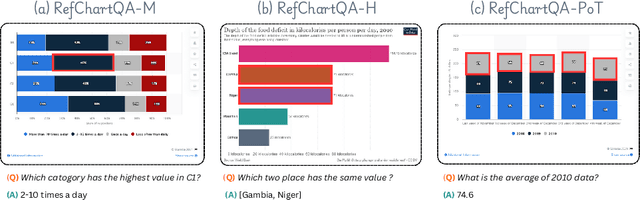
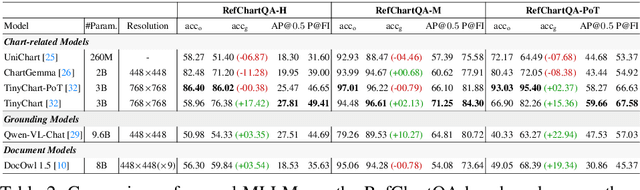
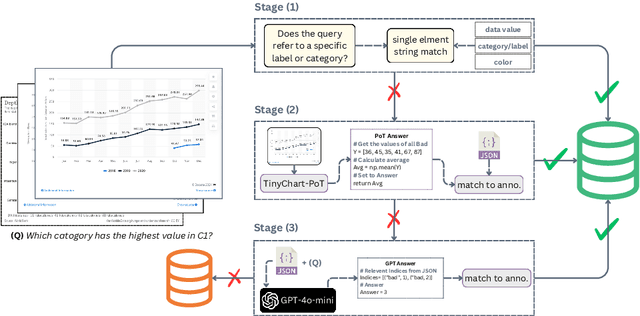
Recently, Vision Language Models (VLMs) have increasingly emphasized document visual grounding to achieve better human-computer interaction, accessibility, and detailed understanding. However, its application to visualizations such as charts remains under-explored due to the inherent complexity of interleaved visual-numerical relationships in chart images. Existing chart understanding methods primarily focus on answering questions without explicitly identifying the visual elements that support their predictions. To bridge this gap, we introduce RefChartQA, a novel benchmark that integrates Chart Question Answering (ChartQA) with visual grounding, enabling models to refer elements at multiple granularities within chart images. Furthermore, we conduct a comprehensive evaluation by instruction-tuning 5 state-of-the-art VLMs across different categories. Our experiments demonstrate that incorporating spatial awareness via grounding improves response accuracy by over 15%, reducing hallucinations, and improving model reliability. Additionally, we identify key factors influencing text-spatial alignment, such as architectural improvements in TinyChart, which leverages a token-merging module for enhanced feature fusion. Our dataset is open-sourced for community development and further advancements. All models and code will be publicly available at https://github.com/moured/RefChartQA.
SFDLA: Source-Free Document Layout Analysis
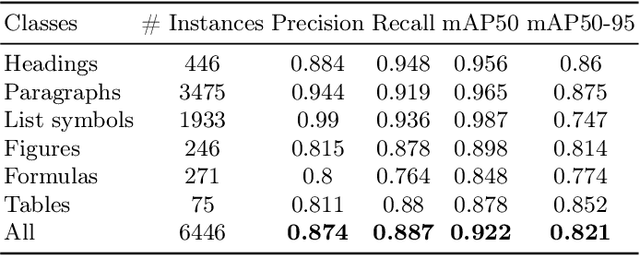
Mar 24, 2025Document Layout Analysis (DLA) is a fundamental task in document understanding. However, existing DLA and adaptation methods often require access to large-scale source data and target labels. This requirements severely limiting their real-world applicability, particularly in privacy-sensitive and resource-constrained domains, such as financial statements, medical records, and proprietary business documents. According to our observation, directly transferring source-domain fine-tuned models on target domains often results in a significant performance drop (Avg. -32.64%). In this work, we introduce Source-Free Document Layout Analysis (SFDLA), aiming for adapting a pre-trained source DLA models to an unlabeled target domain, without access to any source data. To address this challenge, we establish the first SFDLA benchmark, covering three major DLA datasets for geometric- and content-aware adaptation. Furthermore, we propose Document Layout Analysis Adapter (DLAdapter), a novel framework that is designed to improve source-free adaptation across document domains. Our method achieves a +4.21% improvement over the source-only baseline and a +2.26% gain over existing source-free methods from PubLayNet to DocLayNet. We believe this work will inspire the DLA community to further investigate source-free document understanding. To support future research of the community, the benchmark, models, and code will be publicly available at https://github.com/s3setewe/sfdla-DLAdapter.
ACCSAMS: Automatic Conversion of Exam Documents to Accessible Learning Material for Blind and Visually Impaired
May 29, 2024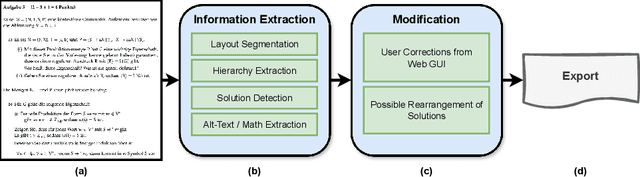
Exam documents are essential educational materials for exam preparation. However, they pose a significant academic barrier for blind and visually impaired students, as they are often created without accessibility considerations. Typically, these documents are incompatible with screen readers, contain excessive white space, and lack alternative text for visual elements. This situation frequently requires intervention by experienced sighted individuals to modify the format and content for accessibility. We propose ACCSAMS, a semi-automatic system designed to enhance the accessibility of exam documents. Our system offers three key contributions: (1) creating an accessible layout and removing unnecessary white space, (2) adding navigational structures, and (3) incorporating alternative text for visual elements that were previously missing. Additionally, we present the first multilingual manually annotated dataset, comprising 1,293 German and 900 English exam documents which could serve as a good training source for deep learning models.
ChartFormer: A Large Vision Language Model for Converting Chart Images into Tactile Accessible SVGs
May 29, 2024Visualizations, such as charts, are crucial for interpreting complex data. However, they are often provided as raster images, which are not compatible with assistive technologies for people with blindness and visual impairments, such as embossed papers or tactile displays. At the same time, creating accessible vector graphics requires a skilled sighted person and is time-intensive. In this work, we leverage advancements in the field of chart analysis to generate tactile charts in an end-to-end manner. Our three key contributions are as follows: (1) introducing the ChartFormer model trained to convert raster chart images into tactile-accessible SVGs, (2) training this model on the Chart2Tactile dataset, a synthetic chart dataset we created following accessibility standards, and (3) evaluating the effectiveness of our SVGs through a pilot user study with an refreshable two-dimensional tactile display. Our work is publicly available at https://github.com/nsothman/ChartFormer .
Alt4Blind: A User Interface to Simplify Charts Alt-Text Creation
May 29, 2024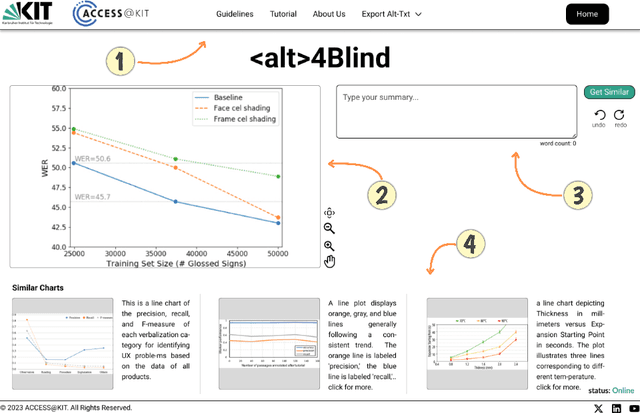
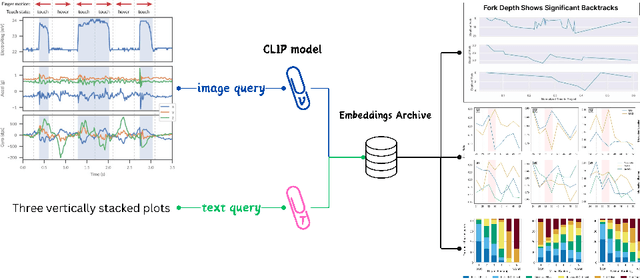
Alternative Texts (Alt-Text) for chart images are essential for making graphics accessible to people with blindness and visual impairments. Traditionally, Alt-Text is manually written by authors but often encounters issues such as oversimplification or complication. Recent trends have seen the use of AI for Alt-Text generation. However, existing models are susceptible to producing inaccurate or misleading information. We address this challenge by retrieving high-quality alt-texts from similar chart images, serving as a reference for the user when creating alt-texts. Our three contributions are as follows: (1) we introduce a new benchmark comprising 5,000 real images with semantically labeled high-quality Alt-Texts, collected from Human Computer Interaction venues. (2) We developed a deep learning-based model to rank and retrieve similar chart images that share the same visual and textual semantics. (3) We designed a user interface (UI) to facilitate the alt-text creation process. Our preliminary interviews and investigations highlight the usability of our UI. For the dataset and further details, please refer to our project page: https://moured.github.io/alt4blind/.
AltChart: Enhancing VLM-based Chart Summarization Through Multi-Pretext Tasks
May 22, 2024Chart summarization is a crucial task for blind and visually impaired individuals as it is their primary means of accessing and interpreting graphical data. Crafting high-quality descriptions is challenging because it requires precise communication of essential details within the chart without vision perception. Many chart analysis methods, however, produce brief, unstructured responses that may contain significant hallucinations, affecting their reliability for blind people. To address these challenges, this work presents three key contributions: (1) We introduce the AltChart dataset, comprising 10,000 real chart images, each paired with a comprehensive summary that features long-context, and semantically rich annotations. (2) We propose a new method for pretraining Vision-Language Models (VLMs) to learn fine-grained chart representations through training with multiple pretext tasks, yielding a performance gain with ${\sim}2.5\%$. (3) We conduct extensive evaluations of four leading chart summarization models, analyzing how accessible their descriptions are. Our dataset and codes are publicly available on our project page: https://github.com/moured/AltChart.
Line Graphics Digitization: A Step Towards Full Automation
Jul 05, 2023The digitization of documents allows for wider accessibility and reproducibility. While automatic digitization of document layout and text content has been a long-standing focus of research, this problem in regard to graphical elements, such as statistical plots, has been under-explored. In this paper, we introduce the task of fine-grained visual understanding of mathematical graphics and present the Line Graphics (LG) dataset, which includes pixel-wise annotations of 5 coarse and 10 fine-grained categories. Our dataset covers 520 images of mathematical graphics collected from 450 documents from different disciplines. Our proposed dataset can support two different computer vision tasks, i.e., semantic segmentation and object detection. To benchmark our LG dataset, we explore 7 state-of-the-art models. To foster further research on the digitization of statistical graphs, we will make the dataset, code, and models publicly available to the community.