 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge as Invariance -- History and Perspectives of Knowledge-augmented Machine Learning
Dec 21, 2020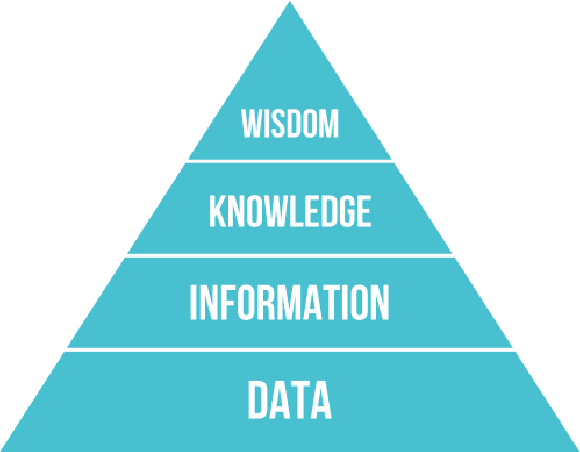
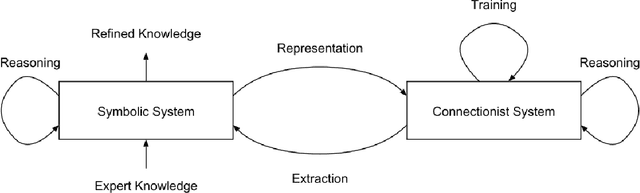
Research in machine learning is at a turning point. While supervised deep learning has conquered the field at a breathtaking pace and demonstrated the ability to solve inference problems with unprecedented accuracy, it still does not quite live up to its name if we think of learning as the process of acquiring knowledge about a subject or problem. Major weaknesses of present-day deep learning models are, for instance, their lack of adaptability to changes of environment or their incapability to perform other kinds of tasks than the one they were trained for. While it is still unclear how to overcome these limitations, one can observe a paradigm shift within the machine learning community, with research interests shifting away from increasing the performance of highly parameterized models to exceedingly specific tasks, and towards employing machine learning algorithms in highly diverse domains. This research question can be approached from different angles. For instance, the field of Informed AI investigates the problem of infusing domain knowledge into a machine learning model, by using techniques such as regularization, data augmentation or post-processing. On the other hand, a remarkable number of works in the recent years has focused on developing models that by themselves guarantee a certain degree of versatility and invariance with respect to the domain or problem at hand. Thus, rather than investigating how to provide domain-specific knowledge to machine learning models, these works explore methods that equip the models with the capability of acquiring the knowledge by themselves. This white paper provides an introduction and discussion of this emerging field in machine learning research. To this end, it reviews the role of knowledge in machine learning, and discusses its relation to the concept of invariance, before providing a literature review of the field.
Application of the Neural Network Dependability Kit in Real-World Environments
Dec 14, 2020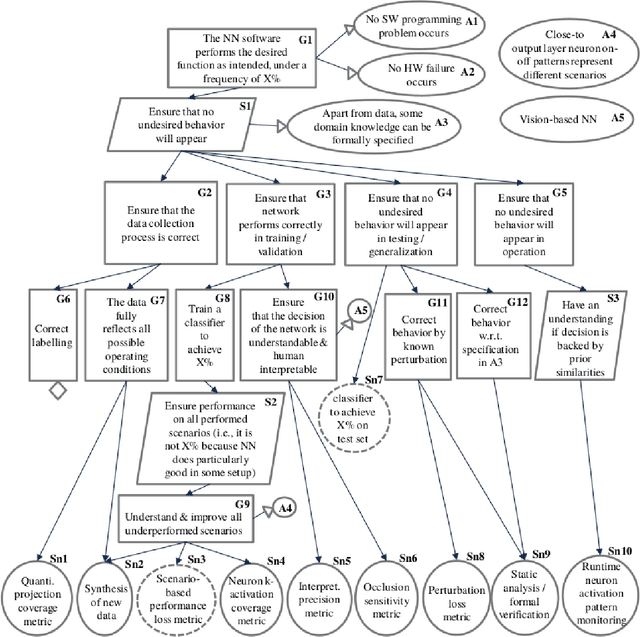
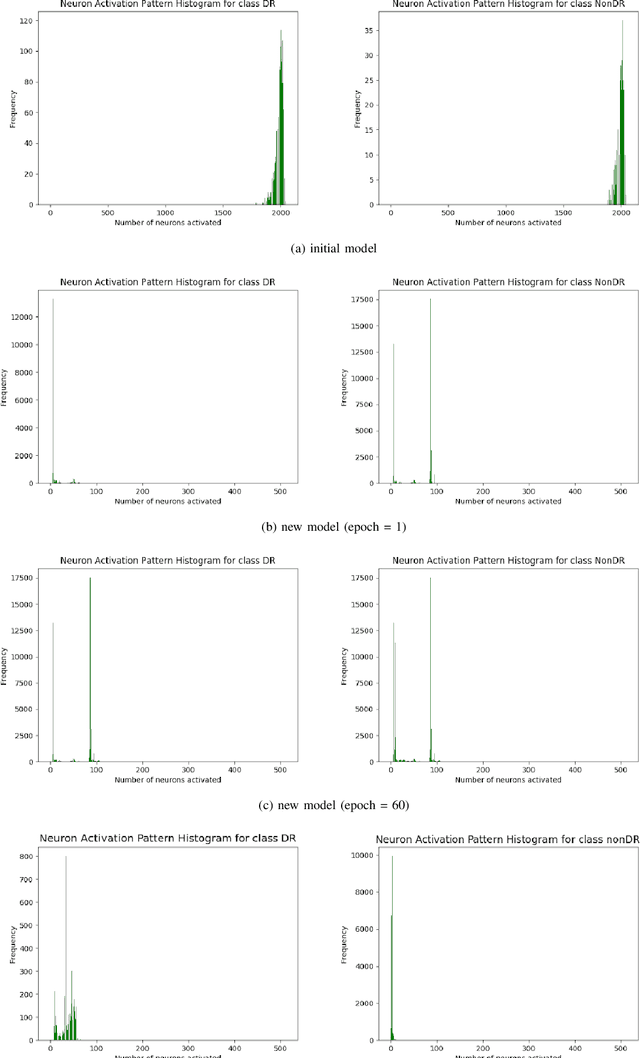
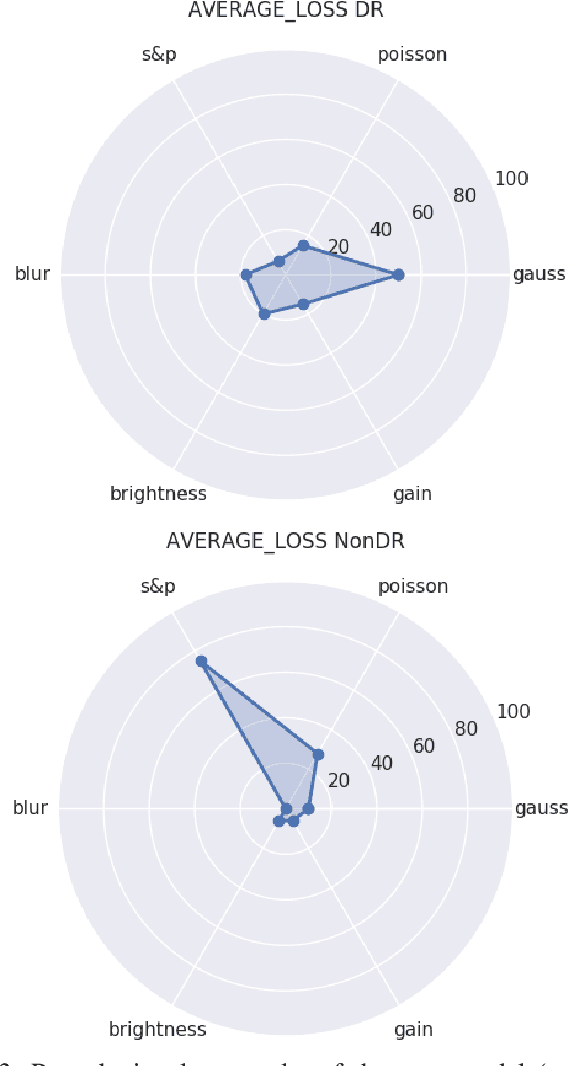
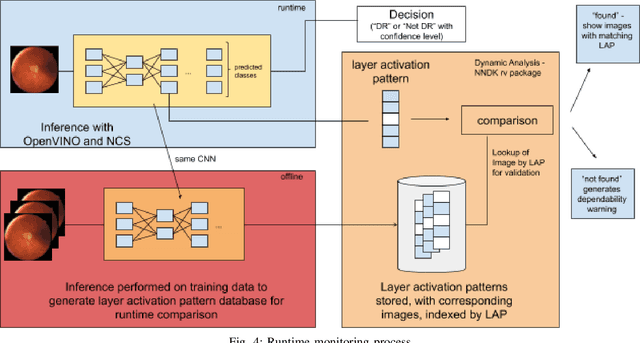
In this paper, we provide a guideline for using the Neural Network Dependability Kit (NNDK) during the development process of NN models, and show how the algorithm is applied in two image classification use cases. The case studies demonstrate the usage of the dependability kit to obtain insights about the NN model and how they informed the development process of the neural network model. After interpreting neural networks via the different metrics available in the NNDK, the developers were able to increase the NNs' accuracy, trust the developed networks, and make them more robust. In addition, we obtained a novel application-oriented technique to provide supporting evidence for an NN's classification result to the user. In the medical image classification use case, it was used to retrieve case images from the training dataset that were similar to the current patient's image and could therefore act as a support for the NN model's decision and aid doctors in interpreting the results.
Subword Semantic Hashing for Intent Classification on Small Datasets
Oct 16, 2018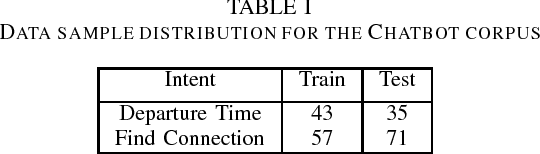

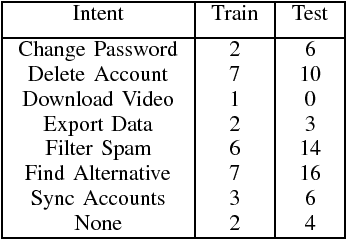
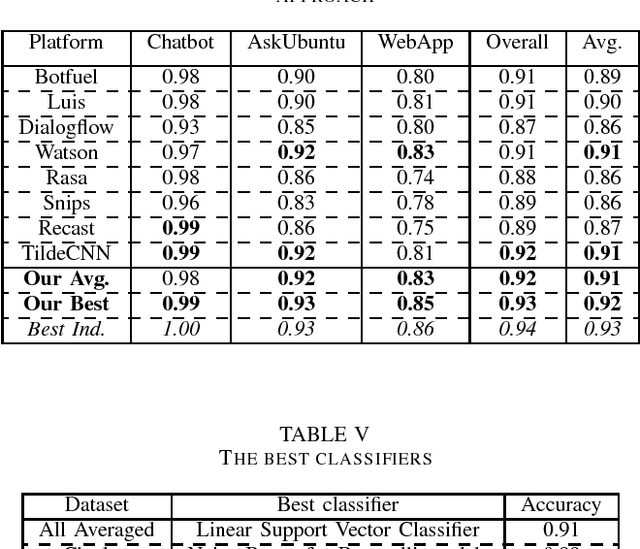
In this paper, we introduce the use of Semantic Hashing as embedding for the task of Intent Classification and outperform previous state-of-the-art methods on three frequently used benchmarks. Intent Classification on a small dataset is a challenging task for data-hungry state-of-the-art Deep Learning based systems. Semantic Hashing is an attempt to overcome such a challenge and learn robust text classification. Current word embedding based methods are dependent on vocabularies. One of the major drawbacks of such methods is out-of-vocabulary terms, especially when having small training datasets and using a wider vocabulary. This is the case in Intent Classification for chatbots, where typically small datasets are extracted from internet communication. Two problems arise by the use of internet communication. First, such datasets miss a lot of terms in the vocabulary to use word embeddings efficiently. Second, users frequently make spelling errors. Typically, the models for intent classification are not trained with spelling errors and it is difficult to think about ways in which users will make mistakes. Models depending on a word vocabulary will always face such issues. An ideal classifier should handle spelling errors inherently. With Semantic Hashing, we overcome these challenges and achieve state-of-the-art results on three datasets: AskUbuntu, Chatbot, and Web Application. Our benchmarks are available online: https://github.com/kumar-shridhar/Know-Your-Intent
Survey of reasoning using Neural networks
Mar 02, 2017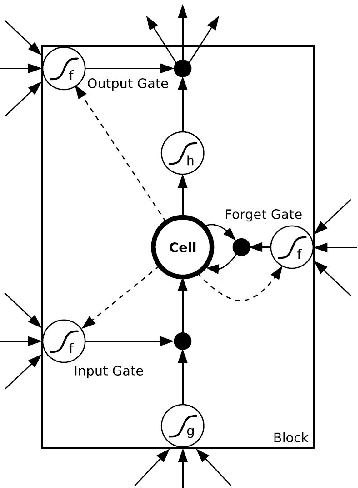
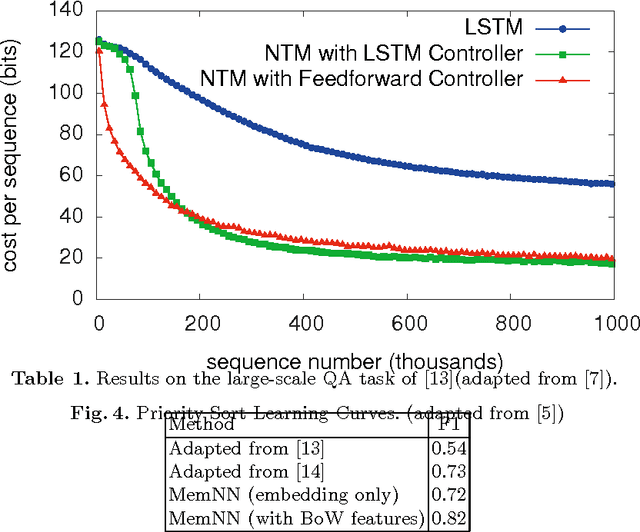
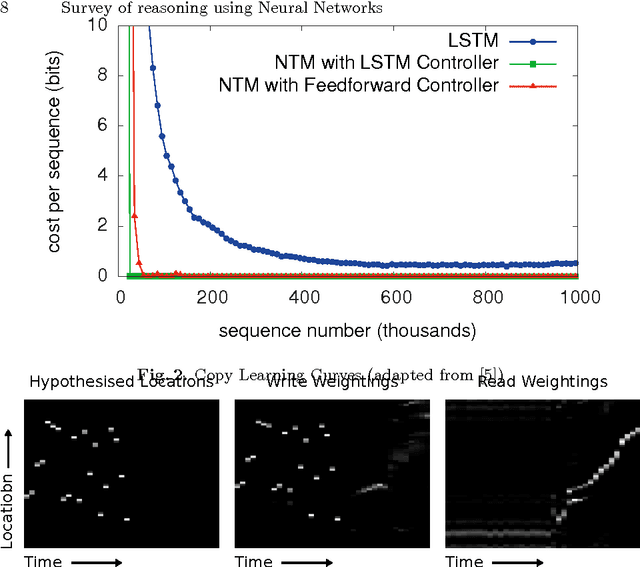
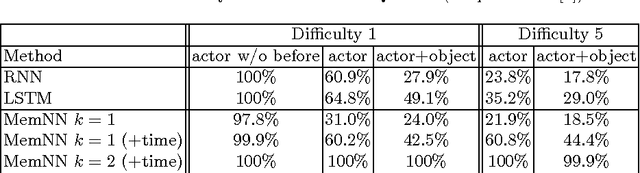
Reason and inference require process as well as memory skills by humans. Neural networks are able to process tasks like image recognition (better than humans) but in memory aspects are still limited (by attention mechanism, size). Recurrent Neural Network (RNN) and it's modified version LSTM are able to solve small memory contexts, but as context becomes larger than a threshold, it is difficult to use them. The Solution is to use large external memory. Still, it poses many challenges like, how to train neural networks for discrete memory representation, how to describe long term dependencies in sequential data etc. Most prominent neural architectures for such tasks are Memory networks: inference components combined with long term memory and Neural Turing Machines: neural networks using external memory resources. Also, additional techniques like attention mechanism, end to end gradient descent on discrete memory representation are needed to support these solutions. Preliminary results of above neural architectures on simple algorithms (sorting, copying) and Question Answering (based on story, dialogs) application are comparable with the state of the art. In this paper, I explain these architectures (in general), the additional techniques used and the results of their application.