 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Efficient Adaptation of Large Language Models for Text Embeddings via Prompt Engineering and Contrastive Fine-tuning
Jul 30, 2025



Large Language Models (LLMs) have become a cornerstone in Natural Language Processing (NLP), achieving impressive performance in text generation. Their token-level representations capture rich, human-aligned semantics. However, pooling these vectors into a text embedding discards crucial information. Nevertheless, many non-generative downstream tasks, such as clustering, classification, or retrieval, still depend on accurate and controllable sentence- or document-level embeddings. We explore several adaptation strategies for pre-trained, decoder-only LLMs: (i) various aggregation techniques for token embeddings, (ii) task-specific prompt engineering, and (iii) text-level augmentation via contrastive fine-tuning. Combining these components yields state-of-the-art performance on the English clustering track of the Massive Text Embedding Benchmark (MTEB). An analysis of the attention map further shows that fine-tuning shifts focus from prompt tokens to semantically relevant words, indicating more effective compression of meaning into the final hidden state. Our experiments demonstrate that LLMs can be effectively adapted as text embedding models through a combination of prompt engineering and resource-efficient contrastive fine-tuning on synthetically generated positive pairs.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022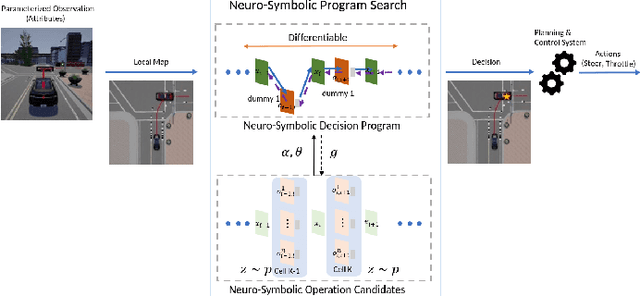
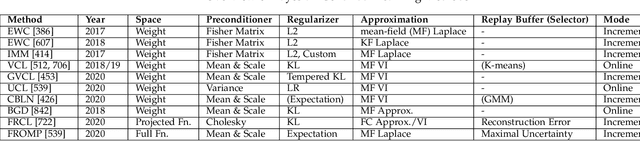
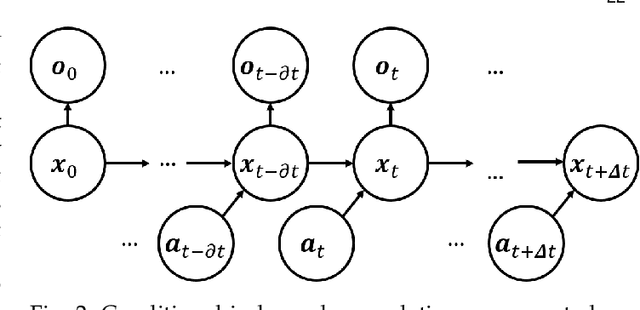
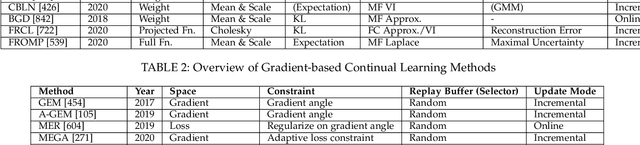
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
Dynamic Texture Recognition via Nuclear Distances on Kernelized Scattering Histogram Spaces
Feb 01, 2021
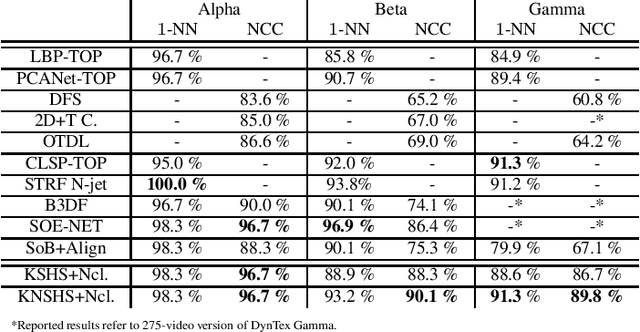
Distance-based dynamic texture recognition is an important research field in multimedia processing with applications ranging from retrieval to segmentation of video data. Based on the conjecture that the most distinctive characteristic of a dynamic texture is the appearance of its individual frames, this work proposes to describe dynamic textures as kernelized spaces of frame-wise feature vectors computed using the Scattering transform. By combining these spaces with a basis-invariant metric, we get a framework that produces competitive results for nearest neighbor classification and state-of-the-art results for nearest class center classification.
* \c{opyright} 2021 IEEE. Personal use of this material is permitted. Permission from IEEE must be obtained for all other uses, in any current or future media, including reprinting/republishing this material for advertising or promotional purposes, creating new collective works, for resale or redistribution to servers or lists, or reuse of any copyrighted component of this work in other works
Knowledge as Invariance -- History and Perspectives of Knowledge-augmented Machine Learning
Dec 21, 2020
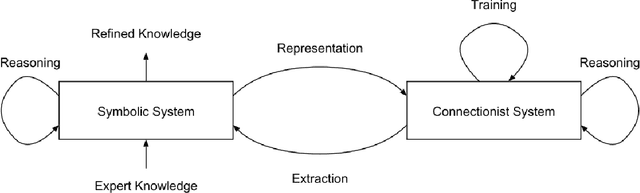
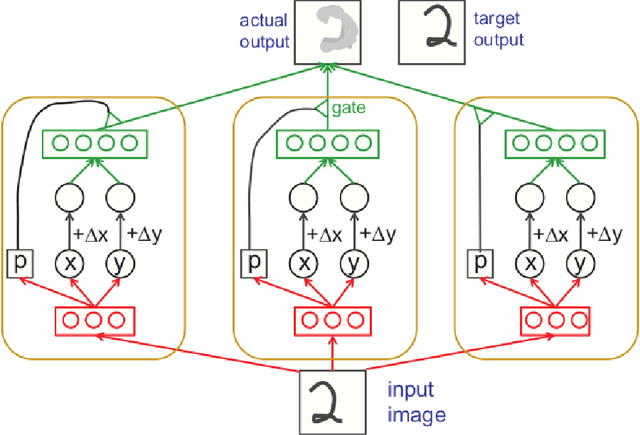
Research in machine learning is at a turning point. While supervised deep learning has conquered the field at a breathtaking pace and demonstrated the ability to solve inference problems with unprecedented accuracy, it still does not quite live up to its name if we think of learning as the process of acquiring knowledge about a subject or problem. Major weaknesses of present-day deep learning models are, for instance, their lack of adaptability to changes of environment or their incapability to perform other kinds of tasks than the one they were trained for. While it is still unclear how to overcome these limitations, one can observe a paradigm shift within the machine learning community, with research interests shifting away from increasing the performance of highly parameterized models to exceedingly specific tasks, and towards employing machine learning algorithms in highly diverse domains. This research question can be approached from different angles. For instance, the field of Informed AI investigates the problem of infusing domain knowledge into a machine learning model, by using techniques such as regularization, data augmentation or post-processing. On the other hand, a remarkable number of works in the recent years has focused on developing models that by themselves guarantee a certain degree of versatility and invariance with respect to the domain or problem at hand. Thus, rather than investigating how to provide domain-specific knowledge to machine learning models, these works explore methods that equip the models with the capability of acquiring the knowledge by themselves. This white paper provides an introduction and discussion of this emerging field in machine learning research. To this end, it reviews the role of knowledge in machine learning, and discusses its relation to the concept of invariance, before providing a literature review of the field.
Learning Co-Sparse Analysis Operators with Separable Structures
Sep 11, 2015
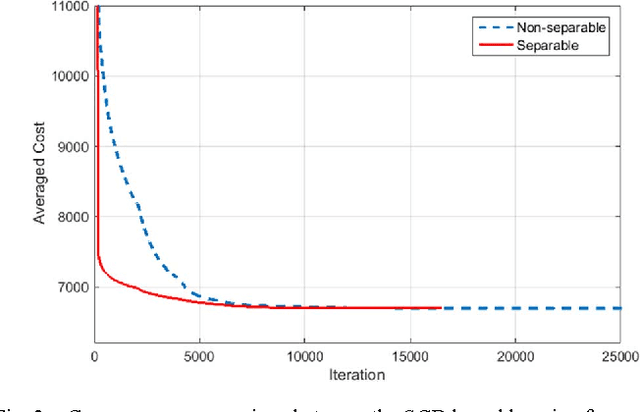
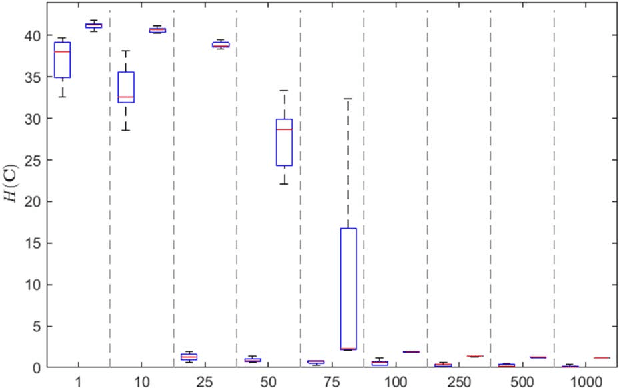
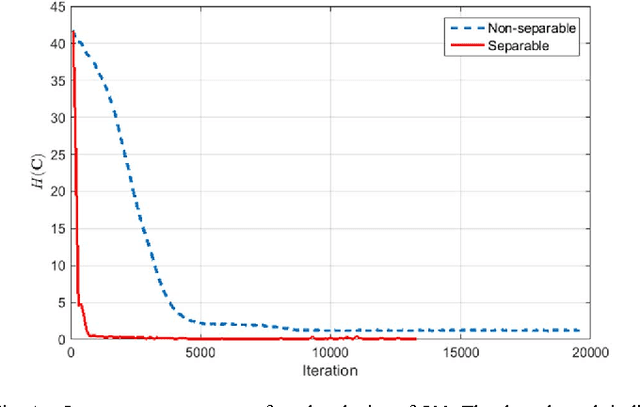
In the co-sparse analysis model a set of filters is applied to a signal out of the signal class of interest yielding sparse filter responses. As such, it may serve as a prior in inverse problems, or for structural analysis of signals that are known to belong to the signal class. The more the model is adapted to the class, the more reliable it is for these purposes. The task of learning such operators for a given class is therefore a crucial problem. In many applications, it is also required that the filter responses are obtained in a timely manner, which can be achieved by filters with a separable structure. Not only can operators of this sort be efficiently used for computing the filter responses, but they also have the advantage that less training samples are required to obtain a reliable estimate of the operator. The first contribution of this work is to give theoretical evidence for this claim by providing an upper bound for the sample complexity of the learning process. The second is a stochastic gradient descent (SGD) method designed to learn an analysis operator with separable structures, which includes a novel and efficient step size selection rule. Numerical experiments are provided that link the sample complexity to the convergence speed of the SGD algorithm.
Separable Cosparse Analysis Operator Learning
Jun 06, 2014
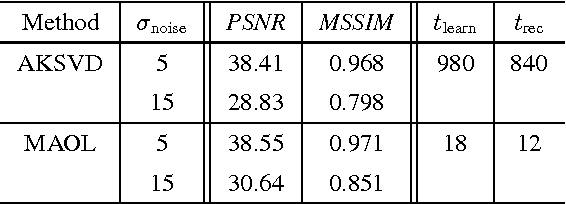
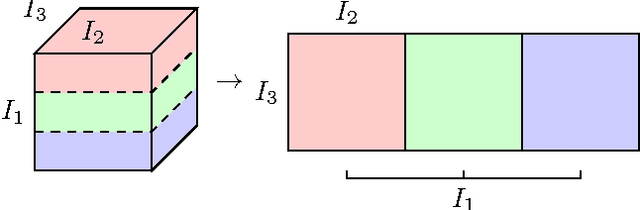
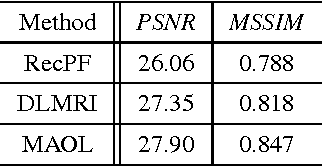
The ability of having a sparse representation for a certain class of signals has many applications in data analysis, image processing, and other research fields. Among sparse representations, the cosparse analysis model has recently gained increasing interest. Many signals exhibit a multidimensional structure, e.g. images or three-dimensional MRI scans. Most data analysis and learning algorithms use vectorized signals and thereby do not account for this underlying structure. The drawback of not taking the inherent structure into account is a dramatic increase in computational cost. We propose an algorithm for learning a cosparse Analysis Operator that adheres to the preexisting structure of the data, and thus allows for a very efficient implementation. This is achieved by enforcing a separable structure on the learned operator. Our learning algorithm is able to deal with multidimensional data of arbitrary order. We evaluate our method on volumetric data at the example of three-dimensional MRI scans.