 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022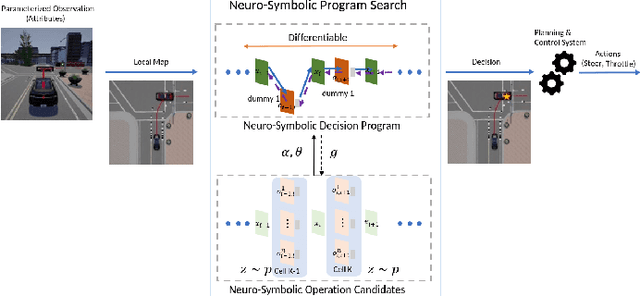
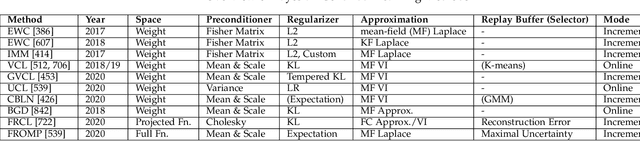
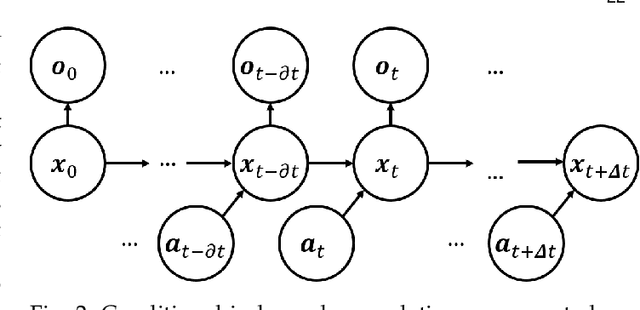
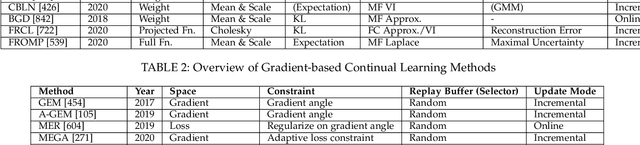
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
F2DNet: Fast Focal Detection Network for Pedestrian Detection
Mar 04, 2022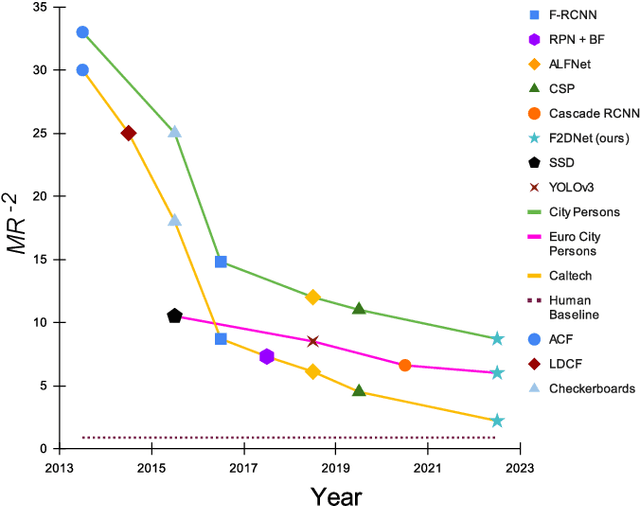
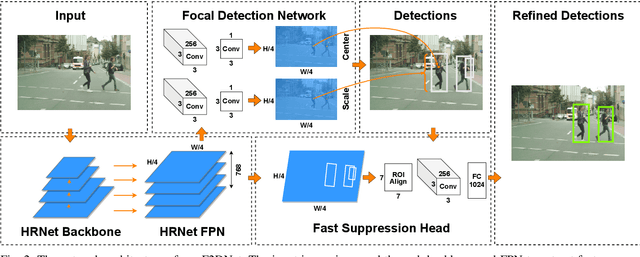

Two-stage detectors are state-of-the-art in object detection as well as pedestrian detection. However, the current two-stage detectors are inefficient as they do bounding box regression in multiple steps i.e. in region proposal networks and bounding box heads. Also, the anchor-based region proposal networks are computationally expensive to train. We propose F2DNet, a novel two-stage detection architecture which eliminates redundancy of current two-stage detectors by replacing the region proposal network with our focal detection network and bounding box head with our fast suppression head. We benchmark F2DNet on top pedestrian detection datasets, thoroughly compare it against the existing state-of-the-art detectors and conduct cross dataset evaluation to test the generalizability of our model to unseen data. Our F2DNet achieves 8.7%, 2.2%, and 6.1% MR-2 on City Persons, Caltech Pedestrian, and Euro City Person datasets respectively when trained on a single dataset and reaches 20.4% and 26.2% MR-2 in heavy occlusion setting of Caltech Pedestrian and City Persons datasets when using progressive fine-tunning. On top of that F2DNet have significantly lesser inference time compared to the current state-of-the-art. Code and trained models will be available at https://github.com/AbdulHannanKhan/F2DNet.
KENN: Enhancing Deep Neural Networks by Leveraging Knowledge for Time Series Forecasting
Feb 16, 2022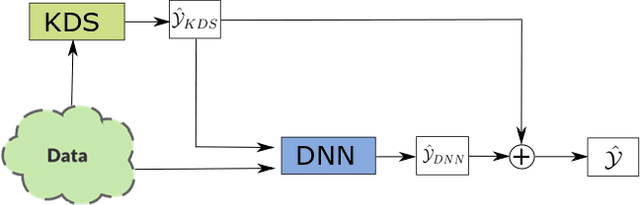

End-to-end data-driven machine learning methods often have exuberant requirements in terms of quality and quantity of training data which are often impractical to fulfill in real-world applications. This is specifically true in time series domain where problems like disaster prediction, anomaly detection, and demand prediction often do not have a large amount of historical data. Moreover, relying purely on past examples for training can be sub-optimal since in doing so we ignore one very important domain i.e knowledge, which has its own distinct advantages. In this paper, we propose a novel knowledge fusion architecture, Knowledge Enhanced Neural Network (KENN), for time series forecasting that specifically aims towards combining strengths of both knowledge and data domains while mitigating their individual weaknesses. We show that KENN not only reduces data dependency of the overall framework but also improves performance by producing predictions that are better than the ones produced by purely knowledge and data driven domains. We also compare KENN with state-of-the-art forecasting methods and show that predictions produced by KENN are significantly better even when trained on only 50\% of the data.
KINN: Incorporating Expert Knowledge in Neural Networks
Feb 15, 2019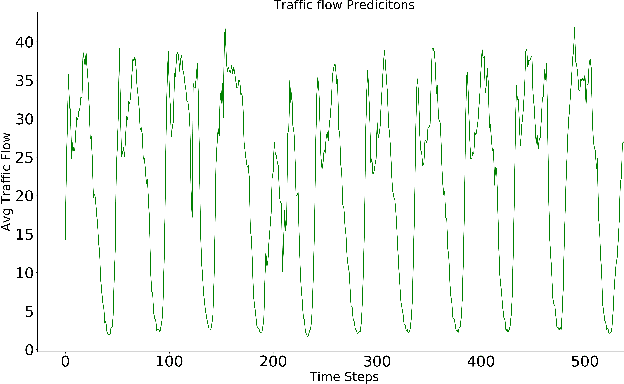
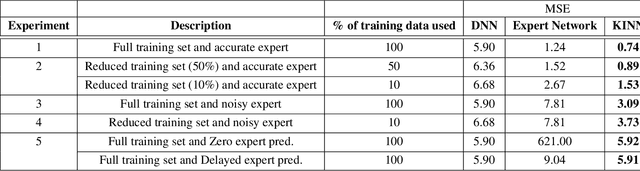
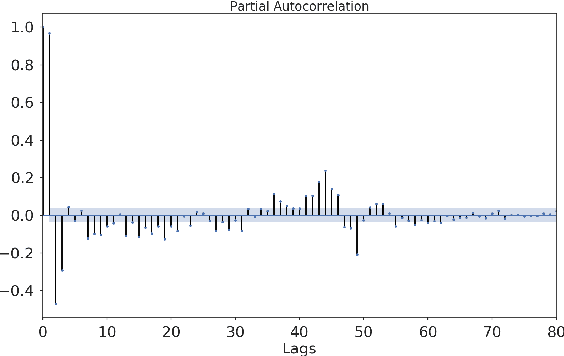
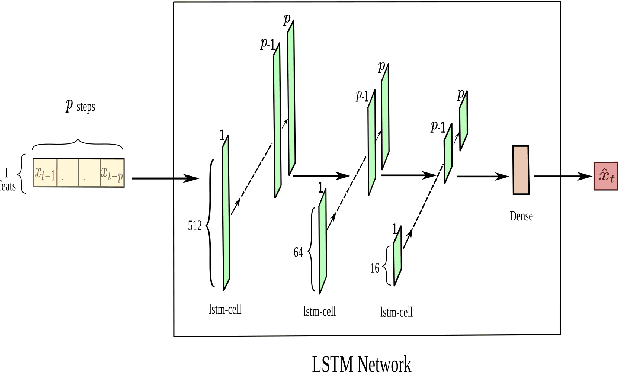
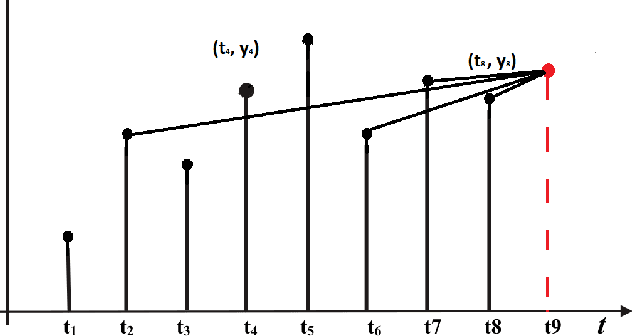
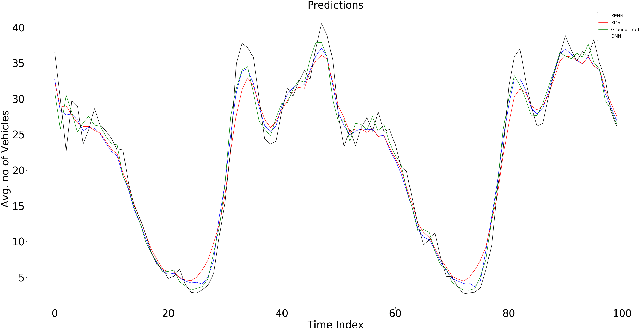
The promise of ANNs to automatically discover and extract useful features/patterns from data without dwelling on domain expertise although seems highly promising but comes at the cost of high reliance on large amount of accurately labeled data, which is often hard to acquire and formulate especially in time-series domains like anomaly detection, natural disaster management, predictive maintenance and healthcare. As these networks completely rely on data and ignore a very important modality i.e. expert, they are unable to harvest any benefit from the expert knowledge, which in many cases is very useful. In this paper, we try to bridge the gap between these data driven and expert knowledge based systems by introducing a novel framework for incorporating expert knowledge into the network (KINN). Integrating expert knowledge into the network has three key advantages: (a) Reduction in the amount of data needed to train the model, (b) provision of a lower bound on the performance of the resulting classifier by obtaining the best of both worlds, and (c) improved convergence of model parameters (model converges in smaller number of epochs). Although experts are extremely good in solving different tasks, there are some trends and patterns, which are usually hidden only in the data. Therefore, KINN employs a novel residual knowledge incorporation scheme, which can automatically determine the quality of the predictions made by the expert and rectify it accordingly by learning the trends/patterns from data. Specifically, the method tries to use information contained in one modality to complement information missed by the other. We evaluated KINN on a real world traffic flow prediction problem. KINN significantly superseded performance of both the expert and as well as the base network (LSTM in this case) when evaluated in isolation, highlighting its superiority for the task.