 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMF: Event Meta Formers for Event-based Real-time Traffic Object Detection
Apr 05, 2025



Event cameras have higher temporal resolution, and require less storage and bandwidth compared to traditional RGB cameras. However, due to relatively lagging performance of event-based approaches, event cameras have not yet replace traditional cameras in performance-critical applications like autonomous driving. Recent approaches in event-based object detection try to bridge this gap by employing computationally expensive transformer-based solutions. However, due to their resource-intensive components, these solutions fail to exploit the sparsity and higher temporal resolution of event cameras efficiently. Moreover, these solutions are adopted from the vision domain, lacking specificity to the event cameras. In this work, we explore efficient and performant alternatives to recurrent vision transformer models and propose a novel event-based object detection backbone. The proposed backbone employs a novel Event Progression Extractor module, tailored specifically for event data, and uses Metaformer concept with convolution-based efficient components. We evaluate the resultant model on well-established traffic object detection benchmarks and conduct cross-dataset evaluation to test its ability to generalize. The proposed model outperforms the state-of-the-art on Prophesee Gen1 dataset by 1.6 mAP while reducing inference time by 14%. Our proposed EMF becomes the fastest DNN-based architecture in the domain by outperforming most efficient event-based object detectors. Moreover, the proposed model shows better ability to generalize to unseen data and scales better with the abundance of data.
oTTC: Object Time-to-Contact for Motion Estimation in Autonomous Driving
May 13, 2024



Autonomous driving systems require a quick and robust perception of the nearby environment to carry out their routines effectively. With the aim to avoid collisions and drive safely, autonomous driving systems rely heavily on object detection. However, 2D object detections alone are insufficient; more information, such as relative velocity and distance, is required for safer planning. Monocular 3D object detectors try to solve this problem by directly predicting 3D bounding boxes and object velocities given a camera image. Recent research estimates time-to-contact in a per-pixel manner and suggests that it is more effective measure than velocity and depth combined. However, per-pixel time-to-contact requires object detection to serve its purpose effectively and hence increases overall computational requirements as two different models need to run. To address this issue, we propose per-object time-to-contact estimation by extending object detection models to additionally predict the time-to-contact attribute for each object. We compare our proposed approach with existing time-to-contact methods and provide benchmarking results on well-known datasets. Our proposed approach achieves higher precision compared to prior art while using a single image.
Real-time Traffic Object Detection for Autonomous Driving
Jan 31, 2024



With recent advances in computer vision, it appears that autonomous driving will be part of modern society sooner rather than later. However, there are still a significant number of concerns to address. Although modern computer vision techniques demonstrate superior performance, they tend to prioritize accuracy over efficiency, which is a crucial aspect of real-time applications. Large object detection models typically require higher computational power, which is achieved by using more sophisticated onboard hardware. For autonomous driving, these requirements translate to increased fuel costs and, ultimately, a reduction in mileage. Further, despite their computational demands, the existing object detectors are far from being real-time. In this research, we assess the robustness of our previously proposed, highly efficient pedestrian detector LSFM on well-established autonomous driving benchmarks, including diverse weather conditions and nighttime scenes. Moreover, we extend our LSFM model for general object detection to achieve real-time object detection in traffic scenes. We evaluate its performance, low latency, and generalizability on traffic object detection datasets. Furthermore, we discuss the inadequacy of the current key performance indicator employed by object detection systems in the context of autonomous driving and propose a more suitable alternative that incorporates real-time requirements.
F2DNet: Fast Focal Detection Network for Pedestrian Detection
Mar 04, 2022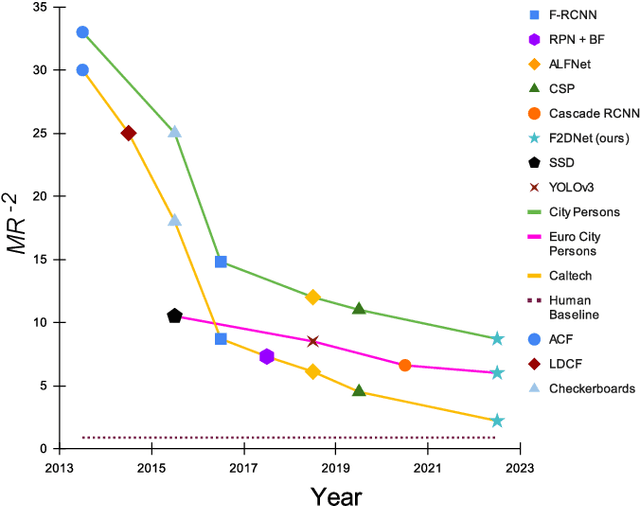
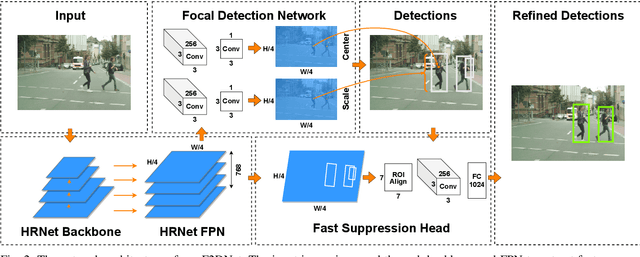

Two-stage detectors are state-of-the-art in object detection as well as pedestrian detection. However, the current two-stage detectors are inefficient as they do bounding box regression in multiple steps i.e. in region proposal networks and bounding box heads. Also, the anchor-based region proposal networks are computationally expensive to train. We propose F2DNet, a novel two-stage detection architecture which eliminates redundancy of current two-stage detectors by replacing the region proposal network with our focal detection network and bounding box head with our fast suppression head. We benchmark F2DNet on top pedestrian detection datasets, thoroughly compare it against the existing state-of-the-art detectors and conduct cross dataset evaluation to test the generalizability of our model to unseen data. Our F2DNet achieves 8.7%, 2.2%, and 6.1% MR-2 on City Persons, Caltech Pedestrian, and Euro City Person datasets respectively when trained on a single dataset and reaches 20.4% and 26.2% MR-2 in heavy occlusion setting of Caltech Pedestrian and City Persons datasets when using progressive fine-tunning. On top of that F2DNet have significantly lesser inference time compared to the current state-of-the-art. Code and trained models will be available at https://github.com/AbdulHannanKhan/F2DNet.