 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeoTTC: Object Time-to-Contact for Motion Estimation in Autonomous Driving
May 13, 2024



Autonomous driving systems require a quick and robust perception of the nearby environment to carry out their routines effectively. With the aim to avoid collisions and drive safely, autonomous driving systems rely heavily on object detection. However, 2D object detections alone are insufficient; more information, such as relative velocity and distance, is required for safer planning. Monocular 3D object detectors try to solve this problem by directly predicting 3D bounding boxes and object velocities given a camera image. Recent research estimates time-to-contact in a per-pixel manner and suggests that it is more effective measure than velocity and depth combined. However, per-pixel time-to-contact requires object detection to serve its purpose effectively and hence increases overall computational requirements as two different models need to run. To address this issue, we propose per-object time-to-contact estimation by extending object detection models to additionally predict the time-to-contact attribute for each object. We compare our proposed approach with existing time-to-contact methods and provide benchmarking results on well-known datasets. Our proposed approach achieves higher precision compared to prior art while using a single image.
Real-time Traffic Object Detection for Autonomous Driving
Jan 31, 2024



With recent advances in computer vision, it appears that autonomous driving will be part of modern society sooner rather than later. However, there are still a significant number of concerns to address. Although modern computer vision techniques demonstrate superior performance, they tend to prioritize accuracy over efficiency, which is a crucial aspect of real-time applications. Large object detection models typically require higher computational power, which is achieved by using more sophisticated onboard hardware. For autonomous driving, these requirements translate to increased fuel costs and, ultimately, a reduction in mileage. Further, despite their computational demands, the existing object detectors are far from being real-time. In this research, we assess the robustness of our previously proposed, highly efficient pedestrian detector LSFM on well-established autonomous driving benchmarks, including diverse weather conditions and nighttime scenes. Moreover, we extend our LSFM model for general object detection to achieve real-time object detection in traffic scenes. We evaluate its performance, low latency, and generalizability on traffic object detection datasets. Furthermore, we discuss the inadequacy of the current key performance indicator employed by object detection systems in the context of autonomous driving and propose a more suitable alternative that incorporates real-time requirements.
Knowledge Augmented Machine Learning with Applications in Autonomous Driving: A Survey
May 10, 2022
The existence of representative datasets is a prerequisite of many successful artificial intelligence and machine learning models. However, the subsequent application of these models often involves scenarios that are inadequately represented in the data used for training. The reasons for this are manifold and range from time and cost constraints to ethical considerations. As a consequence, the reliable use of these models, especially in safety-critical applications, is a huge challenge. Leveraging additional, already existing sources of knowledge is key to overcome the limitations of purely data-driven approaches, and eventually to increase the generalization capability of these models. Furthermore, predictions that conform with knowledge are crucial for making trustworthy and safe decisions even in underrepresented scenarios. This work provides an overview of existing techniques and methods in the literature that combine data-based models with existing knowledge. The identified approaches are structured according to the categories integration, extraction and conformity. Special attention is given to applications in the field of autonomous driving.
Utilizing Out-Domain Datasets to Enhance Multi-Task Citation Analysis
Feb 22, 2022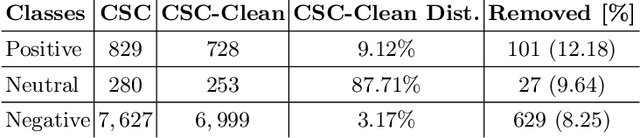

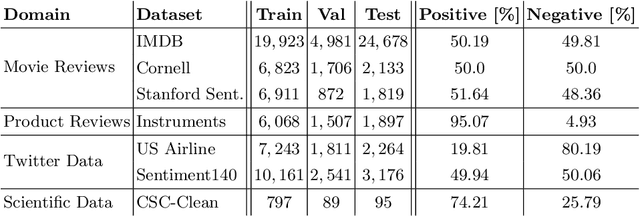
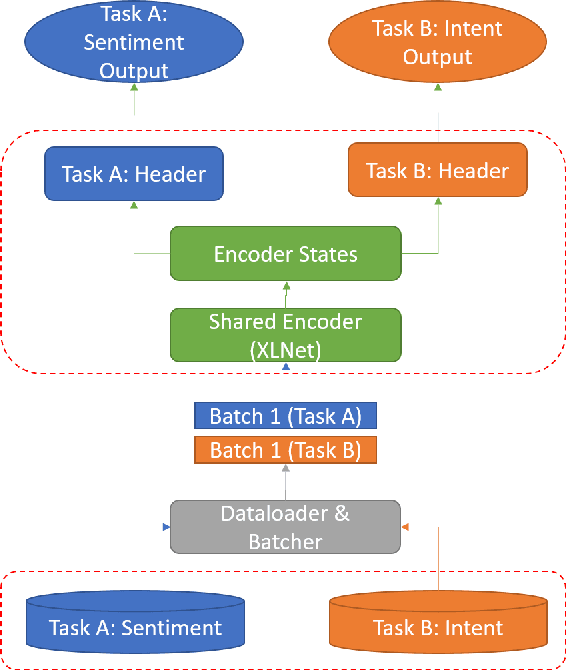
Citations are generally analyzed using only quantitative measures while excluding qualitative aspects such as sentiment and intent. However, qualitative aspects provide deeper insights into the impact of a scientific research artifact and make it possible to focus on relevant literature free from bias associated with quantitative aspects. Therefore, it is possible to rank and categorize papers based on their sentiment and intent. For this purpose, larger citation sentiment datasets are required. However, from a time and cost perspective, curating a large citation sentiment dataset is a challenging task. Particularly, citation sentiment analysis suffers from both data scarcity and tremendous costs for dataset annotation. To overcome the bottleneck of data scarcity in the citation analysis domain we explore the impact of out-domain data during training to enhance the model performance. Our results emphasize the use of different scheduling methods based on the use case. We empirically found that a model trained using sequential data scheduling is more suitable for domain-specific usecases. Conversely, shuffled data feeding achieves better performance on a cross-domain task. Based on our findings, we propose an end-to-end trainable multi-task model that covers the sentiment and intent analysis that utilizes out-domain datasets to overcome the data scarcity.
ImpactCite: An XLNet-based method for Citation Impact Analysis
May 05, 2020
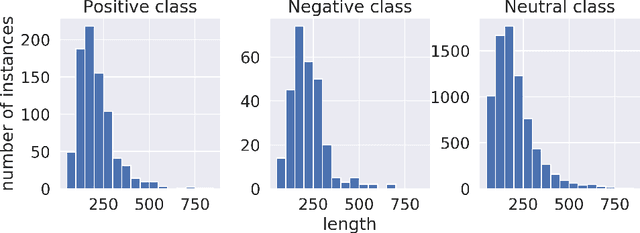

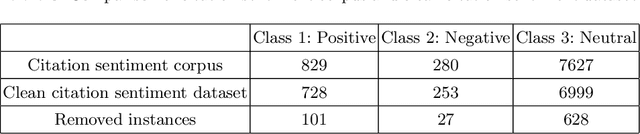
Citations play a vital role in understanding the impact of scientific literature. Generally, citations are analyzed quantitatively whereas qualitative analysis of citations can reveal deeper insights into the impact of a scientific artifact in the community. Therefore, citation impact analysis (which includes sentiment and intent classification) enables us to quantify the quality of the citations which can eventually assist us in the estimation of ranking and impact. The contribution of this paper is two-fold. First, we benchmark the well-known language models like BERT and ALBERT along with several popular networks for both tasks of sentiment and intent classification. Second, we provide ImpactCite, which is XLNet-based method for citation impact analysis. All evaluations are performed on a set of publicly available citation analysis datasets. Evaluation results reveal that ImpactCite achieves a new state-of-the-art performance for both citation intent and sentiment classification by outperforming the existing approaches by 3.44% and 1.33% in F1-score. Therefore, we emphasize ImpactCite (XLNet-based solution) for both tasks to better understand the impact of a citation. Additional efforts have been performed to come up with CSC-Clean corpus, which is a clean and reliable dataset for citation sentiment classification.
DeepBiRD: An Automatic Bibliographic Reference Detection Approach
Dec 16, 2019
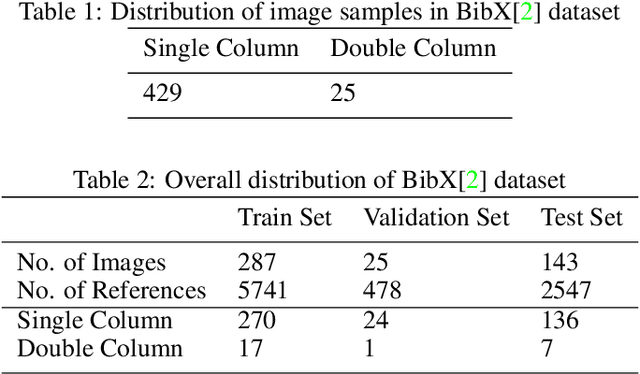

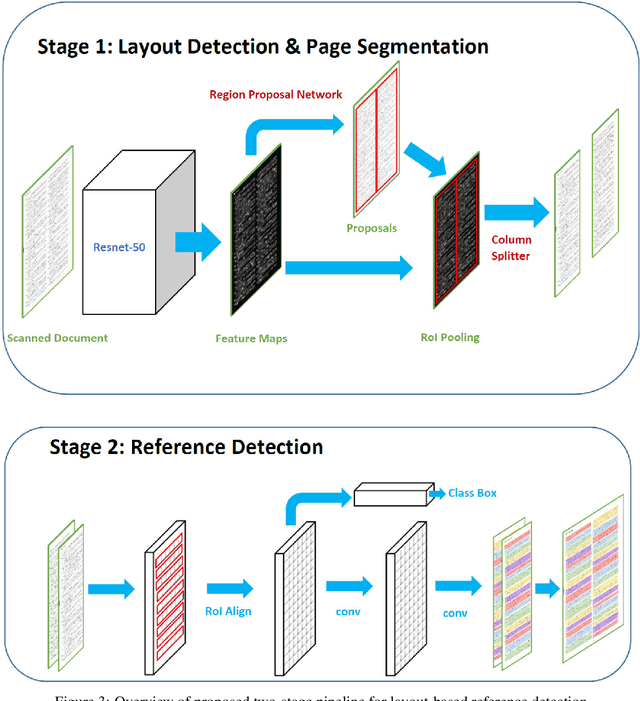
The contribution of this paper is two fold. First, it presents a novel approach called DeepBiRD which is inspired from human visual perception and exploits layout features to identify individual references in a scientific publication. Second, we present a new dataset for image-based reference detection with 2401 scans containing 12244 references, all manually annotated for individual reference. Our proposed approach consists of two stages, firstly it identifies whether given document image is single column or multi-column. Using this information, document image is then splitted into individual columns. Secondly it performs layout driven reference detection using Mask R-CNN in a given scientific publication. DeepBiRD was evaluated on two different datasets to demonstrate the generalization of this approach. The proposed system achieved an F-measure of 0.96 on our dataset. DeepBiRD detected 2.5 times more references than current state-of-the-art approach on their own dataset. Therefore, suggesting that DeepBiRD is significantly superior in performance, generalizable and independent of any domain or referencing style.
Judging a Book By its Cover
Oct 13, 2017
Book covers communicate information to potential readers, but can that same information be learned by computers? We propose using a deep Convolutional Neural Network (CNN) to predict the genre of a book based on the visual clues provided by its cover. The purpose of this research is to investigate whether relationships between books and their covers can be learned. However, determining the genre of a book is a difficult task because covers can be ambiguous and genres can be overarching. Despite this, we show that a CNN can extract features and learn underlying design rules set by the designer to define a genre. Using machine learning, we can bring the large amount of resources available to the book cover design process. In addition, we present a new challenging dataset that can be used for many pattern recognition tasks.