 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtilizing Out-Domain Datasets to Enhance Multi-Task Citation Analysis
Feb 22, 2022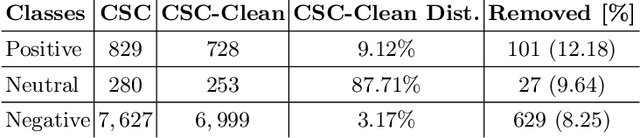

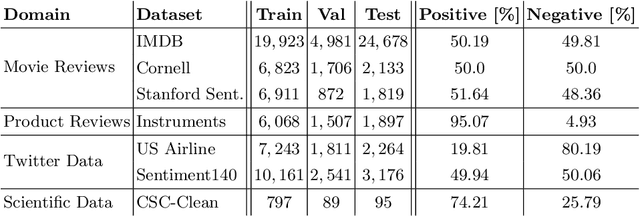
Citations are generally analyzed using only quantitative measures while excluding qualitative aspects such as sentiment and intent. However, qualitative aspects provide deeper insights into the impact of a scientific research artifact and make it possible to focus on relevant literature free from bias associated with quantitative aspects. Therefore, it is possible to rank and categorize papers based on their sentiment and intent. For this purpose, larger citation sentiment datasets are required. However, from a time and cost perspective, curating a large citation sentiment dataset is a challenging task. Particularly, citation sentiment analysis suffers from both data scarcity and tremendous costs for dataset annotation. To overcome the bottleneck of data scarcity in the citation analysis domain we explore the impact of out-domain data during training to enhance the model performance. Our results emphasize the use of different scheduling methods based on the use case. We empirically found that a model trained using sequential data scheduling is more suitable for domain-specific usecases. Conversely, shuffled data feeding achieves better performance on a cross-domain task. Based on our findings, we propose an end-to-end trainable multi-task model that covers the sentiment and intent analysis that utilizes out-domain datasets to overcome the data scarcity.
ImpactCite: An XLNet-based method for Citation Impact Analysis
May 05, 2020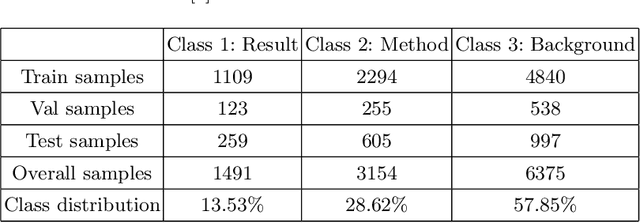
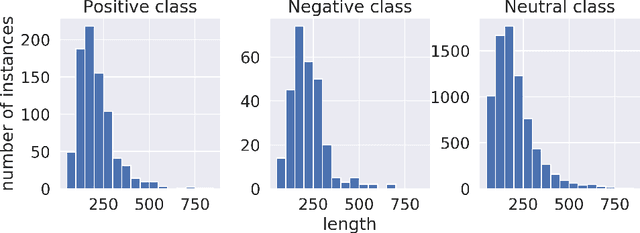

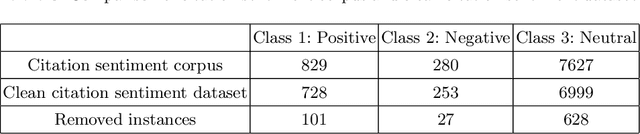
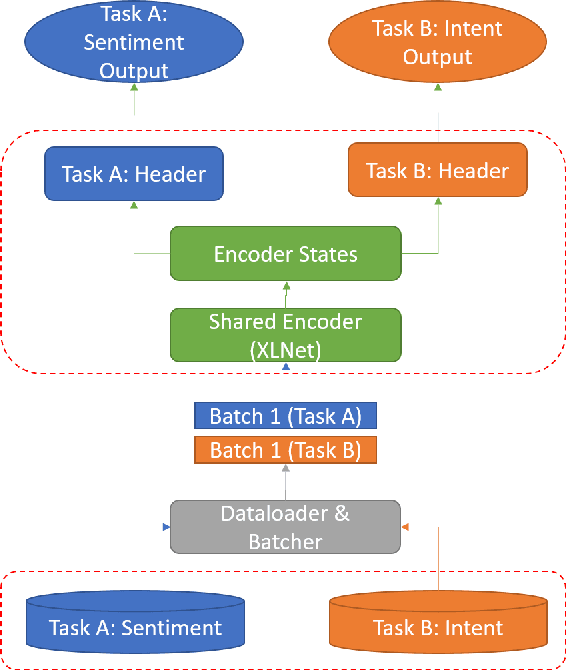
Citations play a vital role in understanding the impact of scientific literature. Generally, citations are analyzed quantitatively whereas qualitative analysis of citations can reveal deeper insights into the impact of a scientific artifact in the community. Therefore, citation impact analysis (which includes sentiment and intent classification) enables us to quantify the quality of the citations which can eventually assist us in the estimation of ranking and impact. The contribution of this paper is two-fold. First, we benchmark the well-known language models like BERT and ALBERT along with several popular networks for both tasks of sentiment and intent classification. Second, we provide ImpactCite, which is XLNet-based method for citation impact analysis. All evaluations are performed on a set of publicly available citation analysis datasets. Evaluation results reveal that ImpactCite achieves a new state-of-the-art performance for both citation intent and sentiment classification by outperforming the existing approaches by 3.44% and 1.33% in F1-score. Therefore, we emphasize ImpactCite (XLNet-based solution) for both tasks to better understand the impact of a citation. Additional efforts have been performed to come up with CSC-Clean corpus, which is a clean and reliable dataset for citation sentiment classification.