 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDocDjinn: Controllable Synthetic Document Generation with VLMs and Handwriting Diffusion
Feb 25, 2026Effective document intelligence models rely on large amounts of annotated training data. However, procuring sufficient and high-quality data poses significant challenges due to the labor-intensive and costly nature of data acquisition. Additionally, leveraging language models to annotate real documents raises concerns about data privacy. Synthetic document generation has emerged as a promising, privacy-preserving alternative. We propose DocDjinn, a novel framework for controllable synthetic document generation using Vision-Language Models (VLMs) that produces annotated documents from unlabeled seed samples. Our approach generates visually plausible and semantically consistent synthetic documents that follow the distribution of an existing source dataset through clustering-based seed selection with parametrized sampling. By enriching documents with realistic diffusion-based handwriting and contextual visual elements via semantic-visual decoupling, we generate diverse, high-quality annotated synthetic documents. We evaluate across eleven benchmarks spanning key information extraction, question answering, document classification, and document layout analysis. To our knowledge, this is the first work demonstrating that VLMs can generate faithful annotated document datasets at scale from unlabeled seeds that can effectively enrich or approximate real, manually annotated data for diverse document understanding tasks. We show that with only 100 real training samples, our framework achieves on average $87\%$ of the performance of the full real-world dataset. We publicly release our code and 140k+ synthetic document samples.
The Sound of Death: Deep Learning Reveals Vascular Damage from Carotid Ultrasound
Feb 19, 2026Cardiovascular diseases (CVDs) remain the leading cause of mortality worldwide, yet early risk detection is often limited by available diagnostics. Carotid ultrasound, a non-invasive and widely accessible modality, encodes rich structural and hemodynamic information that is largely untapped. Here, we present a machine learning (ML) framework that extracts clinically meaningful representations of vascular damage (VD) from carotid ultrasound videos, using hypertension as a weak proxy label. The model learns robust features that are biologically plausible, interpretable, and strongly associated with established cardiovascular risk factors, comorbidities, and laboratory measures. High VD stratifies individuals for myocardial infarction, cardiac death, and all-cause mortality, matching or outperforming conventional risk models such as SCORE2. Explainable AI analyses reveal that the model relies on vessel morphology and perivascular tissue characteristics, uncovering novel functional and anatomical signatures of vascular damage. This work demonstrates that routine carotid ultrasound contains far more prognostic information than previously recognized. Our approach provides a scalable, non-invasive, and cost-effective tool for population-wide cardiovascular risk assessment, enabling earlier and more personalized prevention strategies without reliance on laboratory tests or complex clinical inputs.
SLUM-i: Semi-supervised Learning for Urban Mapping of Informal Settlements and Data Quality Benchmarking
Feb 04, 2026Rapid urban expansion has fueled the growth of informal settlements in major cities of low- and middle-income countries, with Lahore and Karachi in Pakistan and Mumbai in India serving as prominent examples. However, large-scale mapping of these settlements is severely constrained not only by the scarcity of annotations but by inherent data quality challenges, specifically high spectral ambiguity between formal and informal structures and significant annotation noise. We address this by introducing a benchmark dataset for Lahore, constructed from scratch, along with companion datasets for Karachi and Mumbai, which were derived from verified administrative boundaries, totaling 1,869 $\text{km}^2$ of area. To evaluate the global robustness of our framework, we extend our experiments to five additional established benchmarks, encompassing eight cities across three continents, and provide comprehensive data quality assessments of all datasets. We also propose a new semi-supervised segmentation framework designed to mitigate the class imbalance and feature degradation inherent in standard semi-supervised learning pipelines. Our method integrates a Class-Aware Adaptive Thresholding mechanism that dynamically adjusts confidence thresholds to prevent minority class suppression and a Prototype Bank System that enforces semantic consistency by anchoring predictions to historically learned high-fidelity feature representations. Extensive experiments across a total of eight cities spanning three continents demonstrate that our approach outperforms state-of-the-art semi-supervised baselines. Most notably, our method demonstrates superior domain transfer capability whereby a model trained on only 10% of source labels reaches a 0.461 mIoU on unseen geographies and outperforms the zero-shot generalization of fully supervised models.
LD-ViCE: Latent Diffusion Model for Video Counterfactual Explanations
Sep 10, 2025



Video-based AI systems are increasingly adopted in safety-critical domains such as autonomous driving and healthcare. However, interpreting their decisions remains challenging due to the inherent spatiotemporal complexity of video data and the opacity of deep learning models. Existing explanation techniques often suffer from limited temporal coherence, insufficient robustness, and a lack of actionable causal insights. Current counterfactual explanation methods typically do not incorporate guidance from the target model, reducing semantic fidelity and practical utility. We introduce Latent Diffusion for Video Counterfactual Explanations (LD-ViCE), a novel framework designed to explain the behavior of video-based AI models. Compared to previous approaches, LD-ViCE reduces the computational costs of generating explanations by operating in latent space using a state-of-the-art diffusion model, while producing realistic and interpretable counterfactuals through an additional refinement step. Our experiments demonstrate the effectiveness of LD-ViCE across three diverse video datasets, including EchoNet-Dynamic (cardiac ultrasound), FERV39k (facial expression), and Something-Something V2 (action recognition). LD-ViCE outperforms a recent state-of-the-art method, achieving an increase in R2 score of up to 68% while reducing inference time by half. Qualitative analysis confirms that LD-ViCE generates semantically meaningful and temporally coherent explanations, offering valuable insights into the target model behavior. LD-ViCE represents a valuable step toward the trustworthy deployment of AI in safety-critical domains.
DocVCE: Diffusion-based Visual Counterfactual Explanations for Document Image Classification
Aug 06, 2025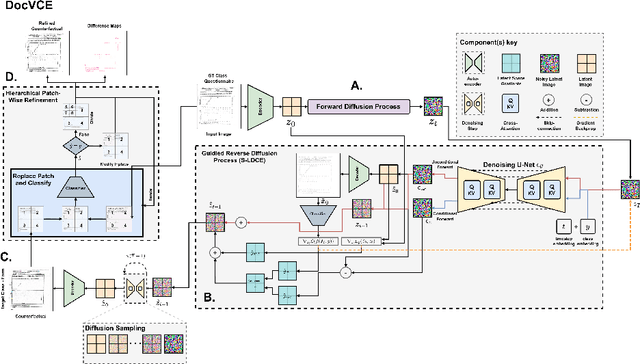
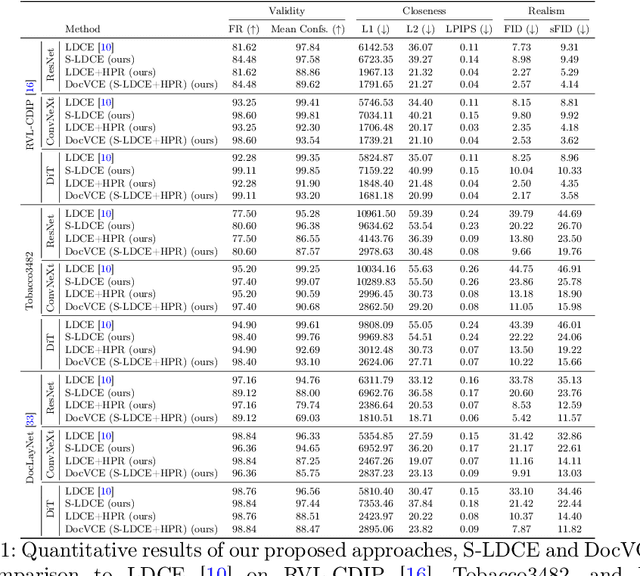


As black-box AI-driven decision-making systems become increasingly widespread in modern document processing workflows, improving their transparency and reliability has become critical, especially in high-stakes applications where biases or spurious correlations in decision-making could lead to serious consequences. One vital component often found in such document processing workflows is document image classification, which, despite its widespread use, remains difficult to explain. While some recent works have attempted to explain the decisions of document image classification models through feature-importance maps, these maps are often difficult to interpret and fail to provide insights into the global features learned by the model. In this paper, we aim to bridge this research gap by introducing generative document counterfactuals that provide meaningful insights into the model's decision-making through actionable explanations. In particular, we propose DocVCE, a novel approach that leverages latent diffusion models in combination with classifier guidance to first generate plausible in-distribution visual counterfactual explanations, and then performs hierarchical patch-wise refinement to search for a refined counterfactual that is closest to the target factual image. We demonstrate the effectiveness of our approach through a rigorous qualitative and quantitative assessment on 3 different document classification datasets -- RVL-CDIP, Tobacco3482, and DocLayNet -- and 3 different models -- ResNet, ConvNeXt, and DiT -- using well-established evaluation criteria such as validity, closeness, and realism. To the best of the authors' knowledge, this is the first work to explore generative counterfactual explanations in document image analysis.
Discovering Concept Directions from Diffusion-based Counterfactuals via Latent Clustering
May 11, 2025Concept-based explanations have emerged as an effective approach within Explainable Artificial Intelligence, enabling interpretable insights by aligning model decisions with human-understandable concepts. However, existing methods rely on computationally intensive procedures and struggle to efficiently capture complex, semantic concepts. Recently, the Concept Discovery through Latent Diffusion-based Counterfactual Trajectories (CDCT) framework, introduced by Varshney et al. (2025), attempts to identify concepts via dimension-wise traversal of the latent space of a Variational Autoencoder trained on counterfactual trajectories. Extending the CDCT framework, this work introduces Concept Directions via Latent Clustering (CDLC), which extracts global, class-specific concept directions by clustering latent difference vectors derived from factual and diffusion-generated counterfactual image pairs. CDLC substantially reduces computational complexity by eliminating the exhaustive latent dimension traversal required in CDCT and enables the extraction of multidimensional semantic concepts encoded across the latent dimensions. This approach is validated on a real-world skin lesion dataset, demonstrating that the extracted concept directions align with clinically recognized dermoscopic features and, in some cases, reveal dataset-specific biases or unknown biomarkers. These results highlight that CDLC is interpretable, scalable, and applicable across high-stakes domains and diverse data modalities.
Deep Learning for Cardiovascular Risk Assessment: Proxy Features from Carotid Sonography as Predictors of Arterial Damage
Apr 09, 2025In this study, hypertension is utilized as an indicator of individual vascular damage. This damage can be identified through machine learning techniques, providing an early risk marker for potential major cardiovascular events and offering valuable insights into the overall arterial condition of individual patients. To this end, the VideoMAE deep learning model, originally developed for video classification, was adapted by finetuning for application in the domain of ultrasound imaging. The model was trained and tested using a dataset comprising over 31,000 carotid sonography videos sourced from the Gutenberg Health Study (15,010 participants), one of the largest prospective population health studies. This adaptation facilitates the classification of individuals as hypertensive or non-hypertensive (75.7% validation accuracy), functioning as a proxy for detecting visual arterial damage. We demonstrate that our machine learning model effectively captures visual features that provide valuable insights into an individual's overall cardiovascular health.
WordVIS: A Color Worth A Thousand Words
Dec 13, 2024



Document classification is considered a critical element in automated document processing systems. In recent years multi-modal approaches have become increasingly popular for document classification. Despite their improvements, these approaches are underutilized in the industry due to their requirement for a tremendous volume of training data and extensive computational power. In this paper, we attempt to address these issues by embedding textual features directly into the visual space, allowing lightweight image-based classifiers to achieve state-of-the-art results using small-scale datasets in document classification. To evaluate the efficacy of the visual features generated from our approach on limited data, we tested on the standard dataset Tobacco-3482. Our experiments show a tremendous improvement in image-based classifiers, achieving an improvement of 4.64% using ResNet50 with no document pre-training. It also sets a new record for the best accuracy of the Tobacco-3482 dataset with a score of 91.14% using the image-based DocXClassifier with no document pre-training. The simplicity of the approach, its resource requirements, and subsequent results provide a good prospect for its use in industrial use cases.
Latent Diffusion for Guided Document Table Generation
Aug 19, 2024Obtaining annotated table structure data for complex tables is a challenging task due to the inherent diversity and complexity of real-world document layouts. The scarcity of publicly available datasets with comprehensive annotations for intricate table structures hinders the development and evaluation of models designed for such scenarios. This research paper introduces a novel approach for generating annotated images for table structure by leveraging conditioned mask images of rows and columns through the application of latent diffusion models. The proposed method aims to enhance the quality of synthetic data used for training object detection models. Specifically, the study employs a conditioning mechanism to guide the generation of complex document table images, ensuring a realistic representation of table layouts. To evaluate the effectiveness of the generated data, we employ the popular YOLOv5 object detection model for training. The generated table images serve as valuable training samples, enriching the dataset with diverse table structures. The model is subsequently tested on the challenging pubtables-1m testset, a benchmark for table structure recognition in complex document layouts. Experimental results demonstrate that the introduced approach significantly improves the quality of synthetic data for training, leading to YOLOv5 models with enhanced performance. The mean Average Precision (mAP) values obtained on the pubtables-1m testset showcase results closely aligned with state-of-the-art methods. Furthermore, low FID results obtained on the synthetic data further validate the efficacy of the proposed methodology in generating annotated images for table structure.
StylusAI: Stylistic Adaptation for Robust German Handwritten Text Generation
Jul 22, 2024



In this study, we introduce StylusAI, a novel architecture leveraging diffusion models in the domain of handwriting style generation. StylusAI is specifically designed to adapt and integrate the stylistic nuances of one language's handwriting into another, particularly focusing on blending English handwriting styles into the context of the German writing system. This approach enables the generation of German text in English handwriting styles and German handwriting styles into English, enriching machine-generated handwriting diversity while ensuring that the generated text remains legible across both languages. To support the development and evaluation of StylusAI, we present the \lq{Deutscher Handschriften-Datensatz}\rq~(DHSD), a comprehensive dataset encompassing 37 distinct handwriting styles within the German language. This dataset provides a fundamental resource for training and benchmarking in the realm of handwritten text generation. Our results demonstrate that StylusAI not only introduces a new method for style adaptation in handwritten text generation but also surpasses existing models in generating handwriting samples that improve both text quality and stylistic fidelity, evidenced by its performance on the IAM database and our newly proposed DHSD. Thus, StylusAI represents a significant advancement in the field of handwriting style generation, offering promising avenues for future research and applications in cross-linguistic style adaptation for languages with similar scripts.